网速123
许多人在使用Nat123时会遇到网速慢的问题,下面就来说说相关的解决方法。
1、cname正确指向。cname指向的唯一性。使用自己的域名时,如设置cname指向nat123的,确保cname的唯一性,不对应的cname指向解析慢或其他不可预知的问题。修改映射不会改变cname,新增映射的cname是不同的。
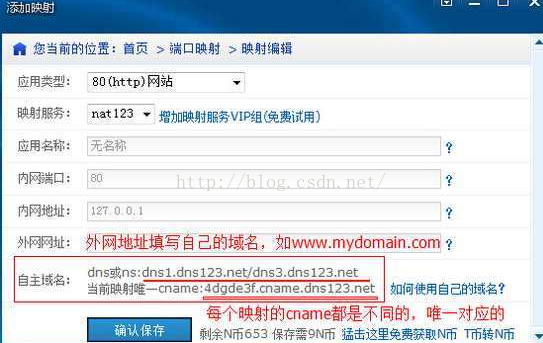
2、使用80映射VIP组,需要编辑映射切换至VIP映射服务线路,如nat123a80、nat123t80。80映射VIP响应更快。
3、本地有(动态)公网IP的,设置本地公网IP加速。设置后网站加载/下载速度由本地速度决定,发挥本地带宽优势。设置位置:主面板/系统设置。打开本地公网IP和加速端口,并使用本地加速。
4、也可能是IP数异常的问题。刷IP或短时IP爆增异常,将自动转移到较慢线路,可能会变慢、丢包、攻击时将黑洞。IP数标准参考套餐服务参数。
5、默认单IP限制5Mbps。可以自定义这个速度。建议这个速度小于自己网络带宽总速度,根据自己的网络速度合理设置。因为如果单IP速度不限,或过大,一个IP用户的操作将吃掉你整个网络速度。
6、全端口映射P2P/转发P2P/使用VIP线路。全端口映射后,访问端需要配合nat123p2p访问者使用,点到点通信,速度由二点间直连网络决定。其中转发P2P是有服务器支持的VIP稳定模式。
每种方法应用的环境不同,这里不做过多说明,选择合适自己的方法即可。
相关阅读
创建一个Navigation Drawer实例代码地址navigation drawer是一个位于屏幕左侧用于显示应用主要导航选项的面板。一般情况下它是隐
这篇文章,我们将展示不同社交网站是如何使用hashtag #标签的,你可以从这篇文章里面学习到如何正确有效地使用hashtag#标签,并且我们
1.springboot 2.0 默认连接池就是Hikari了,所以引用parents后不用专门加依赖
2.贴我自己的配置(时间单位都是毫秒)
# jdbc_config
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/13171191现在Fragment的应用真的是越来越广泛了,之前Android在
在开始讲述之前,先提两个业内用研人士经常会被问到的问题,①为什么要做用研?②用研能为业务做些什么呢?为了回答这两个问题,我将自己从