2019独角兽企业重金招聘Python工程师标准>>> 
某一客户单位的网站首页被篡改,并收到网监的通知说是网站有漏洞,接到上级部门的信息安全整改通报,贵单位网站被植入木马文件,导致网站首页篡改跳转到caipiao网站,根据中华人民共和国计算机信息系统安全保护条例以及信息安全等级保护管理办法的规定,请贵单位尽快对网站漏洞进行修复,核实网站发生的实际安全问题,对发生的问题进行全面的整改与处理,避免网站事态扩大。我们SINE安全公司第一时间应急响应处理,对客户的网站进行安全检测,消除网站安全隐患。
信息安全整改通知书
贵单位,经过信息安全部安全检查及上级部门反馈情况,你院存在以下安全隐患:
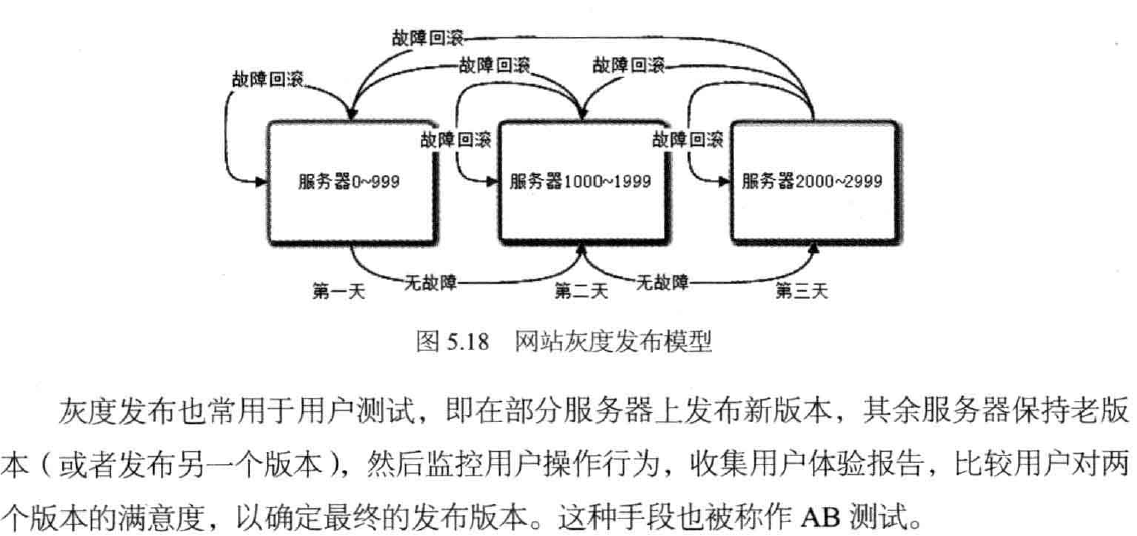
事件类型:网站漏洞--SQL注入漏洞
事件URL://******.cn/search.php?a=
发生时间:2019-02-28
要求整改完成时间:2019-03-06
事件描述:SQL注入漏洞,恶意攻击者可以利用SQL注入漏洞,获取网站数据库中的所有信息,包
括管理员账号密码,造成网站敏感数据信息泄露.网站被篡改。
事件截图:
请贵单位接到网站安全整改通知书后立即整改,并将整改情况以书面形式上报,截止日期为2019年03月06日。在整改期间你院应当采取应急措施,防止发生网站安全事件。
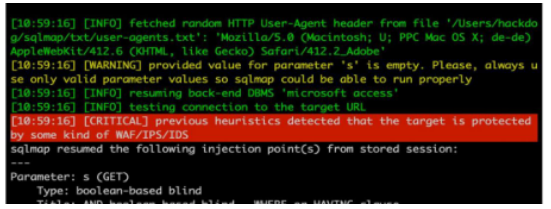
收到信息安全整改通知后,我们SINE安全跟客户对接了相关的网站信息,包括网站的FTP账号密码,以及服务器IP,账号密码。连接FTP对网站代码进行下载,打包,客户网站使用的PHP语言+mysql数据库架构开发的,下载完网站代码对其人工安全审计,发现网站首页文件index.html被篡改成cai票内容,首页的标题,描述,都被改成了bjsaiche等字样,对这些恶意代码进行了强制删除。
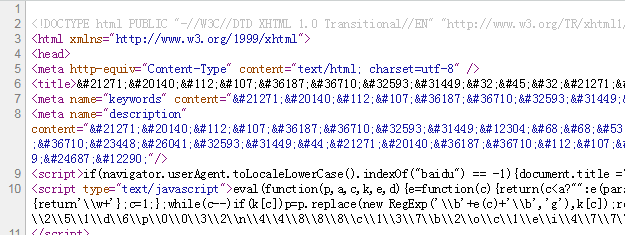
对所有的网站代码进行网站木马后门检测,发现2个木马后门,一个是eval webshell也叫一句话木马后门,另外一个是php网站木马,可以对网站进行篡改,上传,改名等管理员操作的网站木马后门。
对网站的漏洞检测,发现一处sql注入漏洞,漏洞文件是search.php,在搜索中可以插入恶意的sql注入语句,并传送给服务器后端,进行数据库查询,操作,更新表段。我们对该SQL注入漏洞进行了修复,过滤网址请求中的非法特殊字符,采用数据库语句预编译以及绑定变量,检查变量值的类型以及数据格式,限制提交参数的长度。如果自己对程序代码编程不太了解的话,建议找网站安全公司去修复网站的漏洞,以及写信息系统安全等级保护限期整改通知书,国内推荐,SINE安全公司、绿盟安全公司、启明星辰等等的网站安全公司。
关于网站安全,以及漏洞修复方面的安全建议
1.对网站的程序代码定期安全检查,备份,对首页的代码进行查看,是否被篡改添加一些加密的字符内容,尤其标题,描述,内容。
2.网站的后台管理地址,进行更改,默认admin等的地址,改的复杂一些,后台的账号密码使用数字+大小写字母+!@#等的10位以上密码。
3.如果网站使用的单独服务器,像windows系统,linux系统,建议对服务器的系统进行升级,系统漏洞修复,定期扫描系统是否存在木马后门病毒。