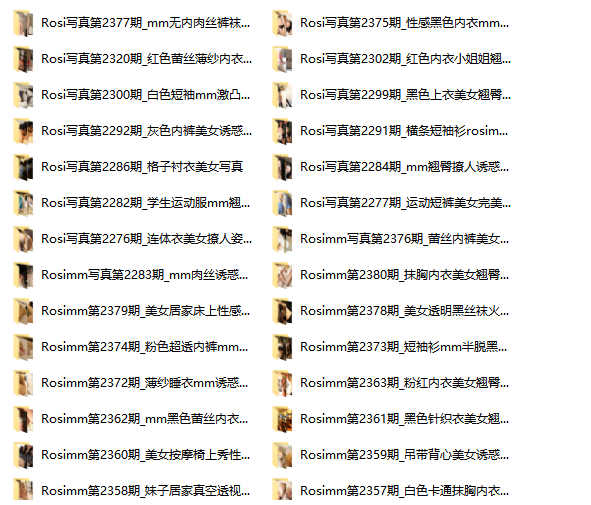
RosimmImage

爬取Rosimm写真网站图片
有图有真相
def main_start(url):"""爬虫入口,主要爬取操作"""try:r = requests.get(url+'.html', headers=HEADERS, timeout=10).textprint(url+'.html')name_index = 0# 套图名,也作为文件夹名folder_name = BeautifulSoup(r, 'lxml').find('h1',class_='article-title').find('a').text.encode('ISO-8859-1').decode('utf-8')with lock:if make_dir(folder_name):# 套图张数max_count = BeautifulSoup(r, 'lxml').find('div',class_='pagination2').find_all('li')[-2].find('a').get_text()print('-------max_count-----'+max_count)# 套图页面page_urls=[]for i in range(1,(int(max_count)+1)):if i==1:page_urls.append(url + '.html')else:page_urls.append(url + '_' + str(i)+'.html')# 图片地址for index, page_url in enumerate(page_urls):print('-----page_url-----'+page_url)result = requests.get(page_url, headers=HEADERS, timeout=10).textimg_url=BeautifulSoup(result,'lxml').find('article',class_='article-content').find_all('img')for s_img_url in img_url:real_img='http://www.rosimm8.com'+s_img_url.get('src')print('-----real_img-----'+real_img)name_index=name_index+1save_pic(real_img,name_index)except Exception as e:print(e)全部代码传送门:https://github.com/SiberiaDante/RosimmImage
仅供学习参考使用