1. 以往的模拟登陆的方法
1.1 requests模块是如何实现模拟登陆的?
- 直接携带cookies请求页面
- 找url地址,发送post请求存储cookie
1.2 selenium是如何模拟登陆的?
- 找到对应的input标签,输入文本点击登陆
1.3 scrapy的模拟登陆
- 直接携带cookies
- 找url地址,发送post请求存储cookie
2. scrapy携带cookies直接获取需要登陆后的页面
应用场景
- cookie过期时间很长,常见于一些不规范的网站
- 能在cookie过期之前把所有的数据拿到
- 配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
2.1 实现:重构scrapy的starte_rquests方法
scrapy中start_url是通过start_requests来进行处理的,其实现代码如下
# 这是源代码
def start_requests(self):cls = self.__class__if method_is_overridden(cls, Spider, 'make_requests_from_url'):warnings.warn("Spider.make_requests_from_url method is deprecated; it ""won't be called in future Scrapy releases. Please ""override Spider.start_requests method instead (see %s.%s)." % (cls.__module__, cls.__name__),)for url in self.start_urls:yield self.make_requests_from_url(url)else:for url in self.start_urls:yield Request(url, dont_filter=True)
如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie
2.2 携带cookies登陆github
示例代码一:
import scrapy
import reclass Login1Spider(scrapy.Spider):name = 'login1'allowed_domains = ['github.com']start_urls = ['https://github.com/NoobPythoner'] # 这是一个需要登陆以后才能访问的页面def start_requests(self): # 重构start_requests方法# 这个cookies_str是抓包获取的cookies_str = '...' # 抓包获取# 将cookies_str转换为cookies_dictcookies_dict = {i.split('=')[0]:i.split('=')[1] for i in cookies_str.split('; ')}yield scrapy.Request(self.start_urls[0],callback=self.parse,cookies=cookies_dict)def parse(self, response): # 通过正则表达式匹配用户名来验证是否登陆成功# 正则匹配的是github的用户名result_list = re.findall(r'noobpythoner|NoobPythoner', response.body.decode()) print(result_list)pass
示例代码二(推荐使用):
import scrapyclass Git1Spider(scrapy.Spider):name = 'git1'allowed_domains = ['github.com']start_urls = ['https://github.com/XXXXXXX']# 重写start_requests方法def start_requests(self):url = self.start_urls[0]temp = 'XXXXXXXcookies值'cookies = {data.split('=')[0]: data.split('=')[1] for data in temp.split('; ')}yield scrapy.Request(url=url,callback=self.parse,cookies=cookies)def parse(self, response):print(response.xpath('/html/head/title/text()').extract_first()) # 这儿若登录失败,则在环境中添加headers,把认证改为否或直接注释掉
注意:
- scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookie
- 在setting中设置ROBOTS协议、USER_AGENT
3. scrapy.Request发送post请求
我们知道可以通过scrapy.Request()指定method、body参数来发送post请求;但是通常使用scrapy.FormRequest()来发送post请求
3.1 发送post请求
注意:scrapy.FormRequest()能够发送表单和ajax请求,参考阅读 https://www.jb51.net/article/146769.htm
3.1.1 思路分析
-
找到post的url地址:点击登录按钮进行抓包,然后定位url地址为Sign in to GitHub · GitHub
-
找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
-
否登录成功:通过请求个人主页,观察是否包含用户名
-

-
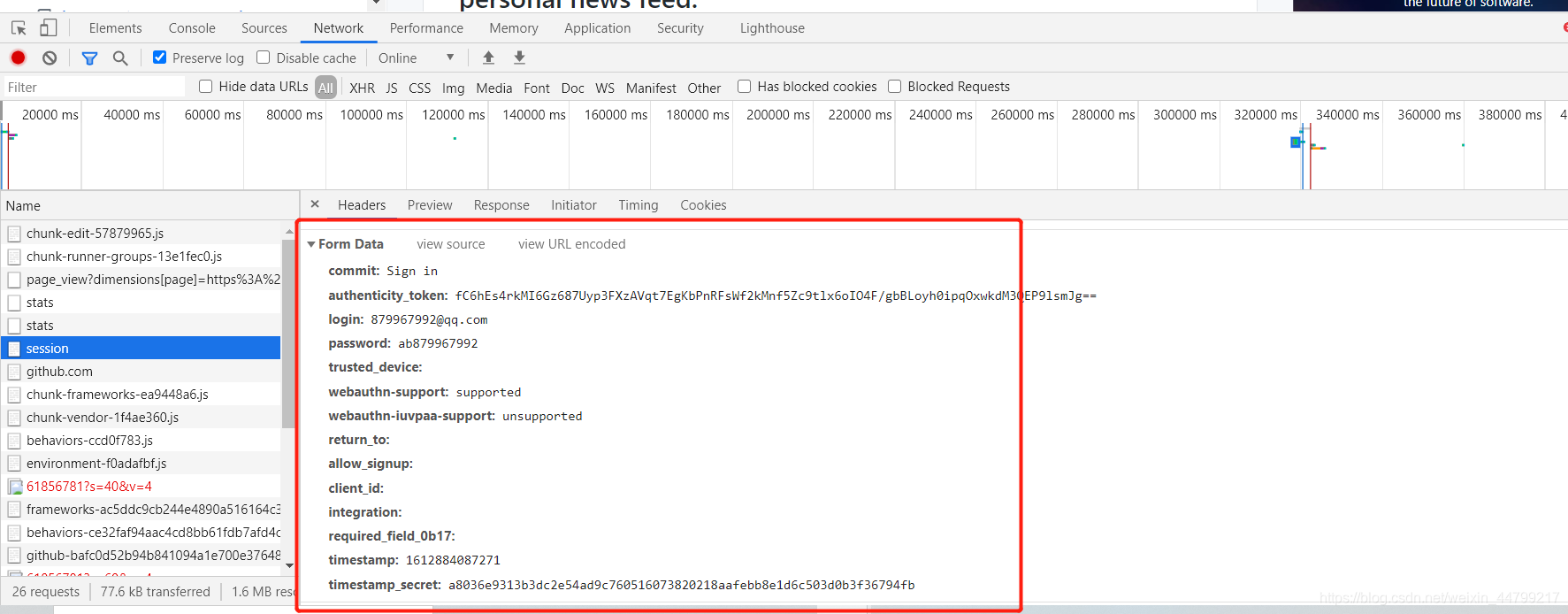
3.1.2 代码实现如下:
示例代码1:
import scrapy
import reclass Login2Spider(scrapy.Spider):name = 'login2'allowed_domains = ['github.com']start_urls = ['https://github.com/login']def parse(self, response):authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()utf8 = response.xpath("//input[@name='utf8']/@value").extract_first()commit = response.xpath("//input[@name='commit']/@value").extract_first()#构造POST请求,传递给引擎yield scrapy.FormRequest("https://github.com/session",formdata={"authenticity_token":authenticity_token,"utf8":utf8,"commit":commit,"login":"***","password":"***"},callback=self.parse_login)def parse_login(self,response):ret = re.findall(r"noobpythoner|NoobPythoner",response.text)print(ret)
示例代码2:
import scrapyclass Git2Spider(scrapy.Spider):name = 'git2'allowed_domains = ['github.com']start_urls = ['http://github.com/login']def parse(self, response):# 从登录页面响应中解析出post数据token = response.xpath('//input[@name="authenticity_token"]/@value').extract_first()print(token)post_data = {"commit": "Sign in","authenticity_token": token,"login": "XXXXXX","password": "XXXXXX","webauthn-support": "supported","webauthn-iuvpaa-support": "unsupported","timestamp": "1612884087271","timestamp_secret": "a8036e9313b3dc2e54ad9c760516073820218aafebb8e1d6c503d0b3f36794fb",}# print(post_data)# 针对登录url发送post请求yield scrapy.FormRequest(url='http://github.com/session',callback=self.after_login,formdata=post_data)def after_login(self, response):yield scrapy.Request('https://github.com/XXXXXXX', callback=self.check_login)def check_login(self, response):print(response.xpath('/html/head/title/text()').extract_first())
小技巧:
在settings.py中通过设置COOKIES_DEBUG=TRUE 能够在终端看到cookie的传递传递过程
总结:
- start_urls中的url地址是交给start_request处理的,如有必要,可以重写start_request函数
- 直接携带cookie登陆:cookie只能传递给cookies参数接收
- scrapy.Request()发送post请求