一、背景
作为软件界最为复杂度的软件代表,当时操作系统、数据库、中间件。而学习中间件,分布式系统,必然绕不开zookeepr、Hadoop的学习。以下做个人搭建zookeeper和Hadoop的搭建的简单记录。相关的代码操作放在github上。
二、搭建过程
1、环境准备
- 虚拟机三台(也可采用Docker,云服务,WSL等进行搭建)
- 相关的安装包(jdk、zk、Hadoop)
为便于下载,我将我所选择的版本组合放在以下网盘,大家可进行下载。
链接:https://pan.baidu.com/s/1kdtTdW9i8Qsc4notcueg-A
提取码:1213

2、虚拟机环境配置
基本要点
- 配置JDK环境变量(ZK\Hadoop基于Java开发,运行在JVM中
- 配置主机号、映射、静态网络IP(便于固定访问
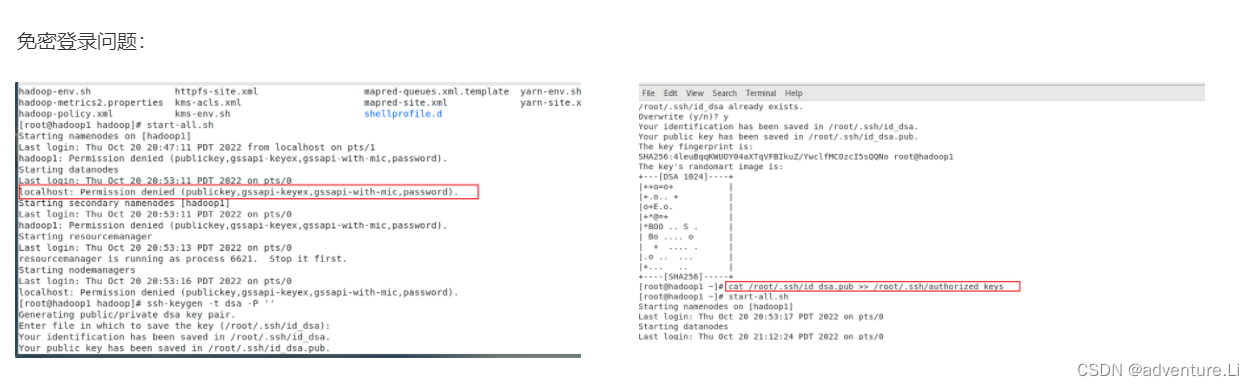
- 配置ssh免密登录(ZK、Hadoop集群是分布式需要机器直接互相通信
- 创建相关文件、并将以上三个软件包进行解压配置
具体步骤
(1)安装虚拟机Hadoop1(先搭好一台再进行克隆,再修改主机号这些细节)
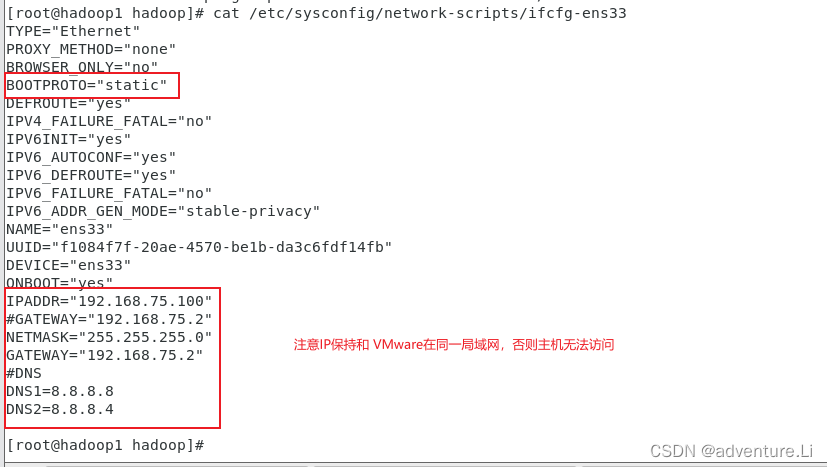
(2)进行主机名修改、静态网络配置、主机映射
- 修改IP映射,DNS:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=""
GATEWAY=""
NETMASK=""
DNS1=""
DNS2=""
- DNS 解析:
vim /etc/resolv.conf
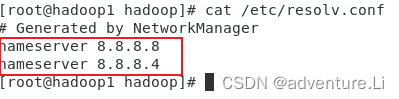
- 主机名修改:
vim /etc/hostname - IP映射:
vim /etc/hosts
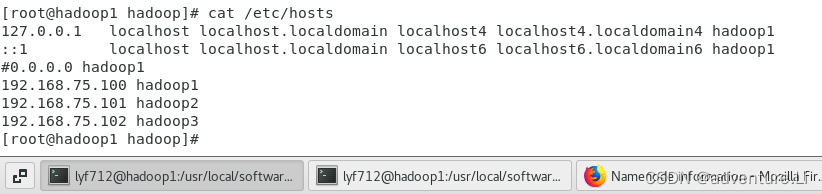
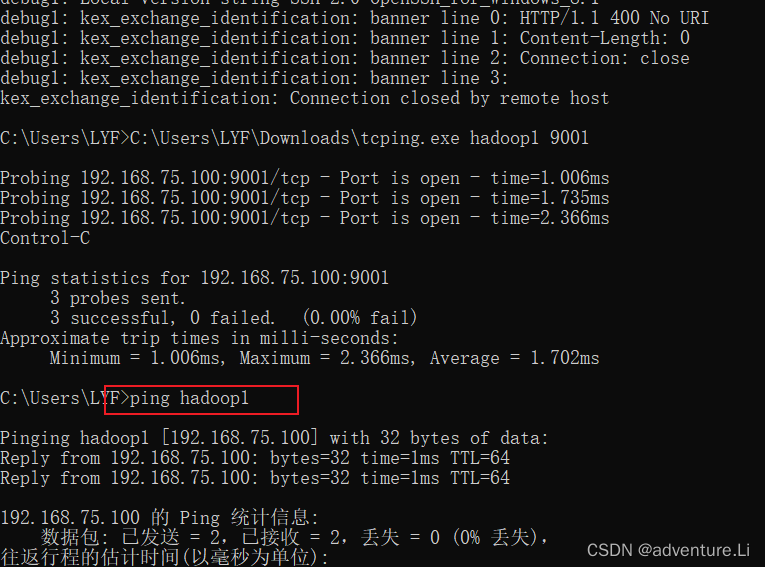
- Windows测试(Windows的 hosts处也进行映射)
C:\Windows\System32\drivers\etc\hosts下进行映射
 ping测试主机连通性
ping测试主机连通性
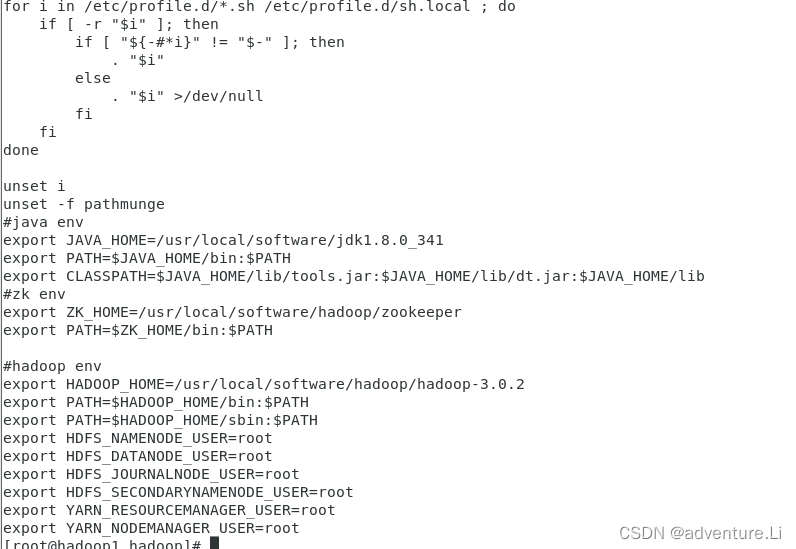
(3)解压JDK安装包,并配置JDK环境变量 - 下载相关安装包,并通过scp或其他方式上传到指定位置
- 进行解压
- 配置JDK环境变量
3、ZK集群的搭建
(1)解压ZK安装包并配置环境变量(同JDK)
(2)配置ZK的配置文件
在 zk文件的etc文件夹具有配置文件,先进行配置文件另命名 mv zoo.sample.cfg zoo.cfg 并进行相关配置。
- dataDir : 放数据文件夹(自己创建一下)
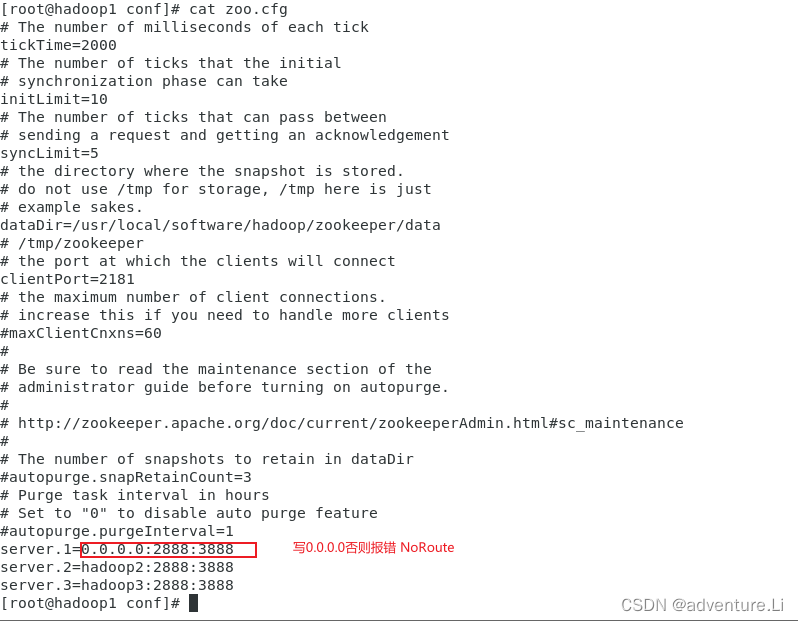
- 集群信息配置 (server.1则至指明节点是哪个机器,会在myid进行标识,2888,3888分别为选举端口,通信端口)
(3)创建myid文件
在 dataDir的文件夹下创建myid,并写入1(代表此节点为序号1):echo 1 >> myid
(4)克隆虚拟机,并修改相关配置
此时第一台机器搭好了,修改其他节点就很快了。主要修改以下
- 修改hostname、hosts映射、IP静态地址(自行分配合理的IP即可)
- 修改ZK的配置文件 myid分别修改为2,3,修改zoo.cfg的集群配置信息,若server.2则修改为 server.2=0.0.0.0:2888:3888
(5)配置SSH进行免密登录(分别对三台机器依次操作)
ssh-keygen
ssh-copy-id root@hadoop1
ssh-copy-id root@hadoop2
ssh-copy-id root@hadoop31)ssh-keygen -t dsa -P ''2)cat ./.ssh/id_dsa.pub >> ./.ssh/authorized_keys(6)测试、相互ssh登录
(7)依次启动ZK
zkServer.sh
采用start-foreground启动,可查看启动的情况,然后进行排除,正常启动则可jps查看到相应的Java进程启动。再通过 status 参数查看状态,可以看到1、3为Follower,2为Leader。
4、Hadoop的搭建
Hadoop有HDFS、Yarn两大块组成,配置相对较复杂。以下主要列一下配置文件,基本步骤:
- 进行相关配置
- 文件夹创建(namenode,datanode)
- namenode格式化:hdfs -format namenode
- 配置相应的环境变量(使用用户)
- 在sbin文件下进行start-all.sh(进行各个组件的启动包装)
- 在logs中进行查看启动的问题


core-site.xml
<configuration>
<property><name>fs.defaultFS</name><!--注意写 0.0.0.0 否则主机访问不了,只能内部访问 ,当然你不想主机来访问测试,也可写localhost,另外端口根据自行需要填写--><value>hdfs://0.0.0.0:9002</value>
</property>
<property><name>hadoop.tmp.dir</name><value>/usr/local/software/hadoop/hadoop-3.0.2/tmp</value>
</property>
</configuration>hdfs-site.xml
<!-- Put site-specific property overrides in this file. --><configuration>
<property><name>dfs.replication</name><value>1</value>
</property>
<property><name>dfs.namenode.name.dir</name><value>/usr/local/software/hadoop/hadoop-3.0.2/namenode</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>/usr/local/software/hadoop/hadoop-3.0.2/datanode</value>
</property><property>
<!--提供HTTP访问,网站访问--><name>dfs.namenode.http-address</name><value>http://0.0.0.0:9001</value>
</property><property><name>dfs.permissions</name><value>false</value><description>need not permissions</description>
</property>
</configuration>
yarn-site.xml
property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
mapred-site.xml
<connfiguration><name>mapreduce.framework.name </name><value>yarn</value>
</configuration>
三、简单的API操作
(1)引入依赖
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.8</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.0.2</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency>
(2)操作ZK
public class ApiTests {//private final static String URL = "hadoop1:2181,hadoop2:2181,hadoop3:281";private ZooKeeper zooKeeper;//@Test@Beforepublic void testCon() throws IOException {//ZooKeeperzooKeeper = new ZooKeeper(URL, 2000, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {System.out.println(watchedEvent);}});}@Testpublic void testBaseOp(){System.out.println("state:"+zooKeeper.getState().isAlive());String path = "/testClientApi";try {System.out.println("create node");System.out.println(zooKeeper.create(path,"ok".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL));} catch (KeeperException | InterruptedException e) {e.printStackTrace();}System.out.println("get node");try {System.out.println(new String(zooKeeper.getData(path, false, new Stat()))); //Arrays.toString(zooKeeper.getData(path, false, new Stat()))} catch (KeeperException | InterruptedException e) {e.printStackTrace();}}
}(3)操作HDFS
public class HdfsApiTests {private final String HDFS_URL = "hdfs://192.168.75.100:9002";//hadoop1private final String SCR_PATH = "E:\\JavaProjects\\CourseProjects\\bigdata-lab\\base-learn\\bigdata-hdfs\\src\\main\\resources\\files\\test_data.json";private final String DST_PATH = "/test";@Beforepublic void initLog() {FileInputStream fileInputStream = null;System.out.println("init log");try {Properties properties = new Properties();fileInputStream = new FileInputStream("src/main/resources/log4j.properties");properties.load(fileInputStream);PropertyConfigurator.configure(properties);} catch (Exception e) {e.printStackTrace();} finally {if (fileInputStream != null) {try {fileInputStream.close();} catch (IOException e) {e.printStackTrace();}}}}@Testpublic void testURL(){try {new URL(HDFS_URL);} catch (MalformedURLException e) {e.printStackTrace();}}@Testpublic void testCopyFile(){System.setProperty("HADOOP_USER_NAME","root");Configuration conf=new Configuration();conf.set("fs.defaultFS",HDFS_URL);FileSystem fs= null;try {fs = FileSystem.get(conf);Path src=new Path(SCR_PATH);Path dst=new Path(DST_PATH);System.out.println("connected");// 为什么一直阻塞住?设计缺陷??超时也该报错呀// time out 就是超时了,需要设置参数,思考业务场景,// 对于大规模的file文件传输很耗时,因此超时的时间也会很长、、HDFS默认的超时时长为10分钟+30秒// 配置需要 0.0.0.0 ;区分 localhost、0.0.0.0、127.0.0.1//if(!fs.exists(new Path("/t2"))){System.out.println("doest exists");fs.mkdirs(new Path("/t2"));}System.out.println("ok!");// fs.copyFromLocalFile(src,dst);//fs.listFiles(dst,true);} catch (IOException e) {e.printStackTrace();} finally {try {assert fs != null;fs.close();} catch (IOException e) {e.printStackTrace();}}}
}四、问题记录
- myid file missing : 在zookeeper目录创建zkData
- 排查错误:start-foreground + logs
- connection refused : hadoop1 — 映射 0.0.0.0:https://www.likecs.com/show-203327394.html
- NoRouteExecption : 防火墙的关闭 , https://blog.csdn.net/weixin_42263618/article/details/111191847
- hdfsAPI操作时无反应(HDFS的超时10Min+,因此连接不上虚拟机,注意掌握测端口进程连通性的方法:https://zhuanlan.zhihu.com/p/451237274)