1.超参数是什么? 超参数是指的是比如SGD的一个学习率,或者是抑制过拟合时候的一个权重衰减率参数等等,这些参数需要一个合适的值才能很好的提升神经网络的学习效率
2.我们在进行超参数最优化的时候如何去做到超参数最优化?
2.1.设定超参数的搜索范围
2.2.随机选择在这个范围内的超参数
2.3.反复循环1,2步骤,并且不断缩小搜索范围
3.首先为什么上面所说要缩小搜索范围,因为我们搜索最优超参数是通过不断缩小“最优值”的范围,在这个范围内寻找最优秀的参数,这样我们就可以寻找到最优超参数
4.我们在搜索最优超参数时候大概率会需要很久的时间,那么我们如何去缩短搜索时间呢?很简单,我们只需要把epoch调小,让搜索频率更快一点,这样我们就可以跳过很多没用的随机出来的值,实验代码如下:
coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net import MultiLayerNet
from common.util import shuffle_dataset
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
为了实现高速化,减少训练数据
x_train = x_train[:500]
t_train = t_train[:500]
分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_train, t_train = shuffle_dataset(x_train, t_train)# 打乱数据集为了导致数据集没有偏向
x_val = x_train[:validation_num]#获取一部分训练数据集
t_val = t_train[:validation_num]#获取一部分教师数据集
x_train = x_train[validation_num:]#前面获得是验证数据集,那么前面就当作测试获取最优超参数的数据集和后面的训练数据集作为对比
t_train = t_train[validation_num:]
###注:::当验证数据集和训练数据集拟合的很好的情况下就说明超参数训练的相当不错
def __train(lr, weight_decay, epocs=50):#开始训练验证数据集
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],#获取神经网络对象
output_size=10, weight_decay_lambda=weight_decay)
trainer = Trainer(network, x_train, t_train, x_val, t_val,#获取训练神经网络对象
epochs=epocs, mini_batch_size=100,
optimizer=‘sgd’, optimizer_param={‘lr’: lr}, verbose=False)
trainer.train()#开始训练
return trainer.test_acc_list, trainer.train_acc_list#获取最终的训练结果的精确率
超参数的随机搜索======================================
optimization_trial = 100#最优测试
results_val = {}#获取结果的值
results_train = {}#获取训练之后的值
for _ in range(optimization_trial):
# 指定搜索的超参数的范围===============
weight_decay = 10 ** np.random.uniform(-8, -4)#设定权值衰减系数
lr = 10 ** np.random.uniform(-6, -2)#设定学习率
# ================================================
val_acc_list, train_acc_list = __train(lr, weight_decay)#开始训练获取精确率
#输出教师数据集的最终精确率,打印学习率和权重衰减系数
print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))
key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)
results_val[key] = val_acc_list
results_train[key] = train_acc_list
绘制图形========================================================
print(“=========== Hyper-Parameter Optimization Result ===========”)
graph_draw_num = 20
col_num = 5
row_num = int(np.ceil(graph_draw_num / col_num))
i = 0
for key, val_acc_list in sorted(results_val.items(), key=lambda x:x[1][-1], reverse=True):
print(“Best-” + str(i+1) + “(val acc:” + str(val_acc_list[-1]) + ") | " + key)
plt.subplot(row_num, col_num, i+1)
plt.title("Best-" + str(i+1))
plt.ylim(0.0, 1.0)
if i % 5: plt.yticks([])
plt.xticks([])
x = np.arange(len(val_acc_list))
plt.plot(x, val_acc_list)
plt.plot(x, results_train[key], "--")
i += 1if i >= graph_draw_num:break
plt.show()
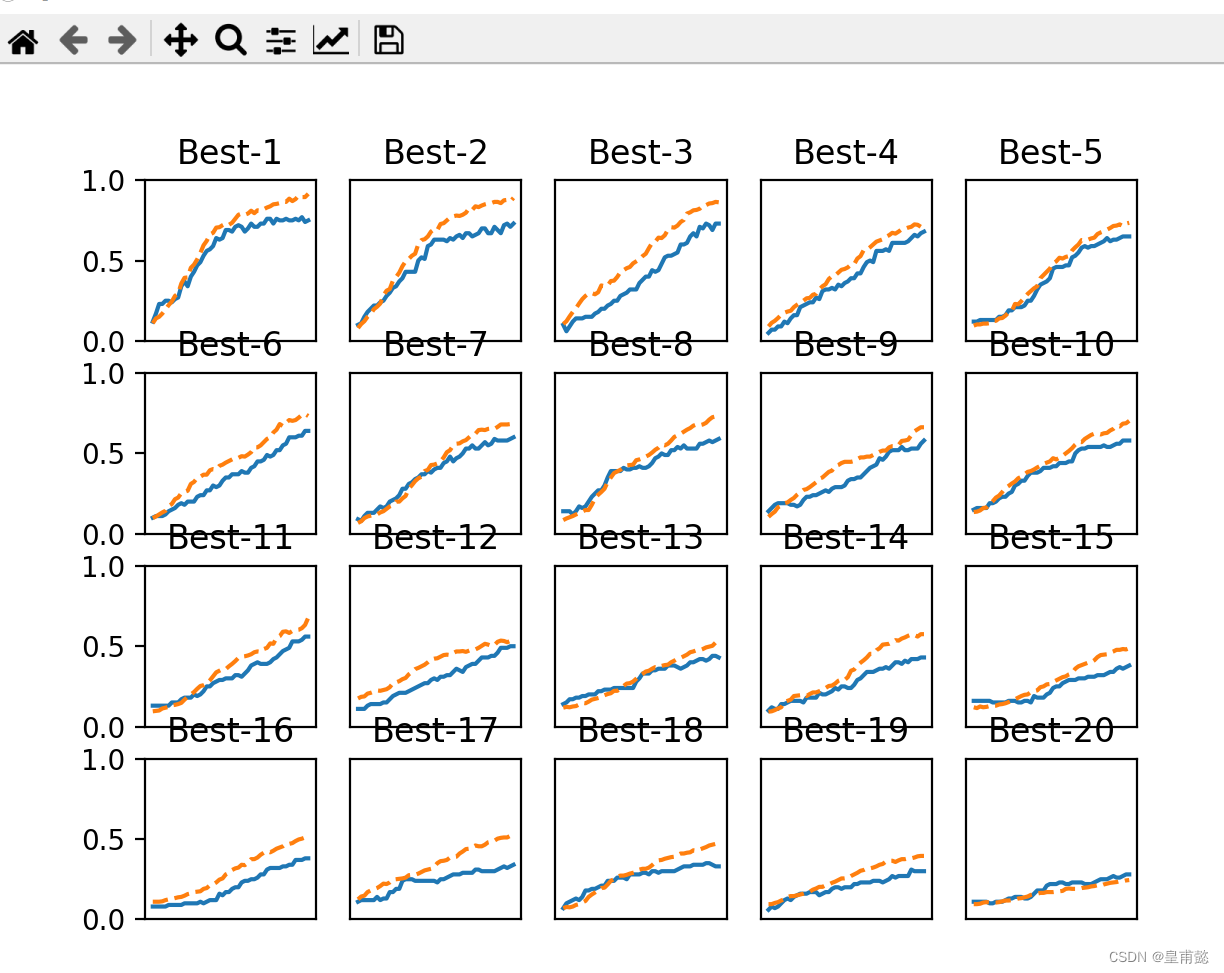
5.上面这张图是我们选择学习率参数在1e-6到1e-2的范围和权重衰减系数在1e-8到1e-4的范围内的一个搜索训练结果,蓝色的线是训练集,黄色是验证数据集,验证数据集是用来搜索最优超参数的数据集,蓝色的训练集是为了最终和验证数据集训练的结果进行对比拟合程度,如果拟合程度相当高,那么说明对应参数很不错!
6.那么为啥拟合程度高就一定超参数训练的好呢? 原因在我理解为如果拟合程度高,说明对应数据集的泛化能力就很强,这个地方用验证数据集和训练数据集对比拟合程度,也就是精确率,就是为了表明,如果随机再挑选一部分数据集,我也可以让对应数据集和训练集的拟合程度很高,这样我们的神经网络就可以很好的拟合其他数据集,泛化能力强!(注意,我的验证数据集是从训练集中随机挑选了百分之20的实验数据)
7.我们发现best1到best5的图拟合程度很好!,那么我们就把对应的超参数范围缩小到前五个图范围之内,再次进行训练,缩小搜索范围,看看有什么神奇的发现把?
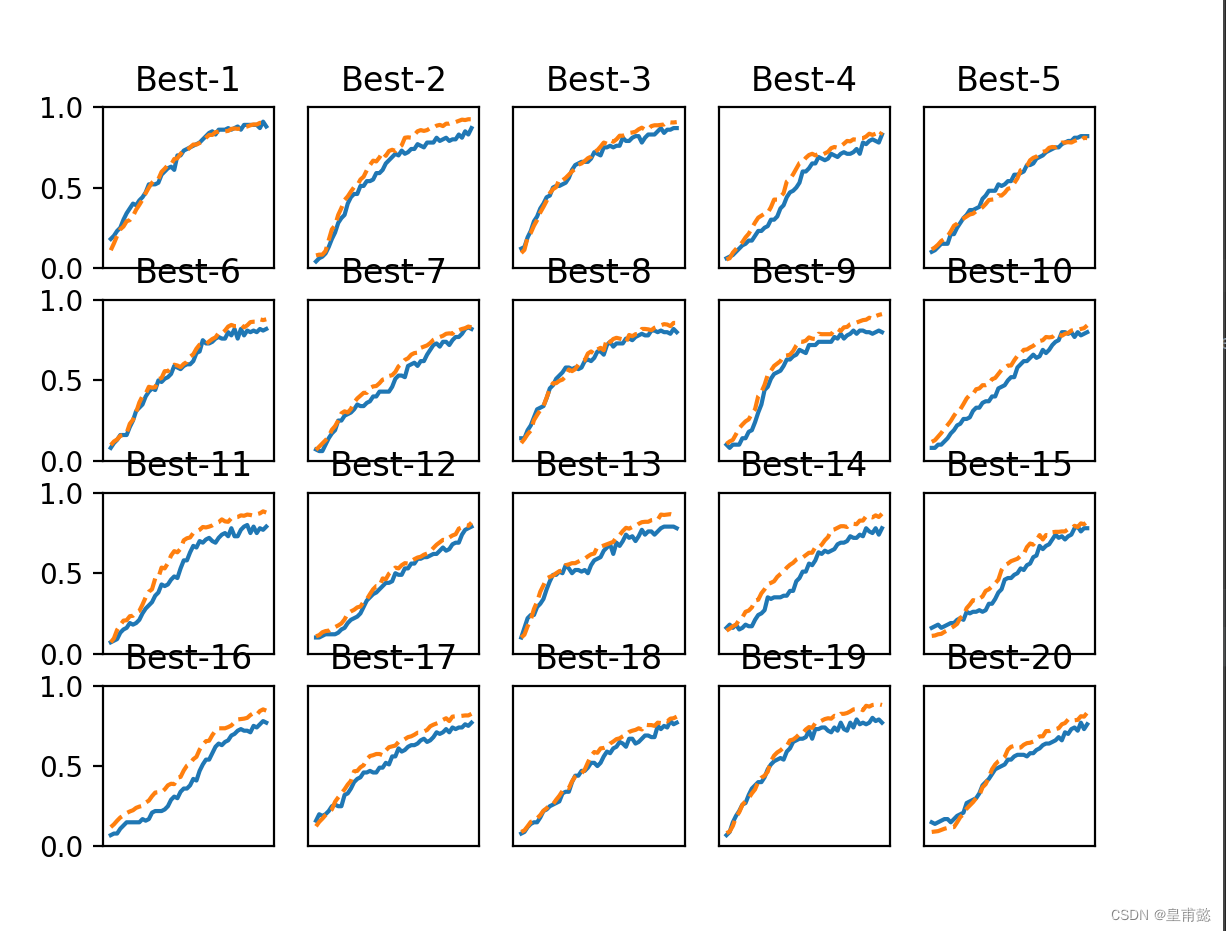
很明显,训练的拟合程度更好了,我们这个时候可以在这些图范围内选择一个拟合程度最好的超参数,然后进行实战训练我们的训练数据集,提升我们的神经网络训练效率