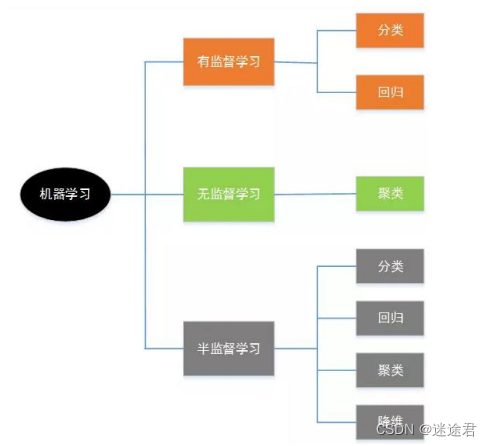
机器学习分类?
1 特征(feature)数据是区分事物和事物的关键。 举例:不同类型的书,我们用书的内容来对它进行分类2 标签(label)数据的标签,显示的分类结果。 举例:书属于的类别,例如“计算机”“图形学”“英文书”“教材”等。3 学习(learning)将很多数据丢给计算机分析,以此来训练该计算机,培养计算机给数据分类的能力。举例:把很多书交给一个学生, 培养他给书本分类的能力。4 分类(classification)定性输出称为分类,或者说是离散变量预测。 举例:预测明天是阴、晴还是雨,就是一个分类任务。5 回归(regression)定量输出称为回归,或者说是连续变量预测; 举例:预测明天的气温是多少度,这是一个回归任务;6 聚类(clustering)无监督学习的结果。聚类的结果将产生一组集合,集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异。 举例:没有标准参考的学生给书本分的类别,表示自己认为这些书可能是同一类别的
模型
我们告诉小明这个动物是猫,那个也是猫。但突然一只狗跑过来,你告诉他,这个不是狗。久而久之,小明就会产生 认知模式。这个学习过程,就叫“训练”。所形成的认知模式,就是”模型“。 训练之后。这时,再跑过来一个动物时,你问小明,这个是猫吧? 他会回答,是/否。这个就叫,预测。在python中我们将海量的数据对我们建立的模型进行训练之后,我们就可以通过模型来预测我们需要的数据
损失函数
是用来度量模型预测值f(x)与样本真实标签值y的不一致程度。给定输入的样本数据x,模型函数输出一个f(x),这个输 出的f(x)与样本的真实值标签值y可能是相同的,也可能是不同的,为了表示我们拟合的好坏,就用一个函数来度量拟 合的程度。例如:之前我们已经训练了猫的模型了,这时候如果来了一只动物,小明说这是猫,这个结论和真实的结论的距离的 评估算法,我们叫做损失函数,偏差大,预估的是错误的,反之,预估是正确的
优化与过拟合,欠拟合
依据损失函数差值,不断调整模型的过程叫优化,使用的算法实现,叫优化方法,但是一味追求让损失函数达到最小,模型就会面临过拟合问题,导致预测未知数据的效果变差,也就是过度理解,使用简单的模型去拟合复杂数据时,会导致模型很难拟合数据的真实分布,这就会面临欠拟合问题
K近邻法(KNN)
K近邻法(K-Nearest Neighbor,KNN,以下简称KNN) 是一种简单易懂的分类方法,当然,它也可以被用于回归运算中,KNN是一种监督学习。 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。KNN是一种分(classification)算法,它输入基于实例的学习(instance-based learning),属于懒惰学习(lazy learning)即KNN 没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。KNN是通过测量不同特征值之间的距离进行分类。 思路是:如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。 KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别 来决定待分样本所属的类别。
让我们来看一个例子吧:
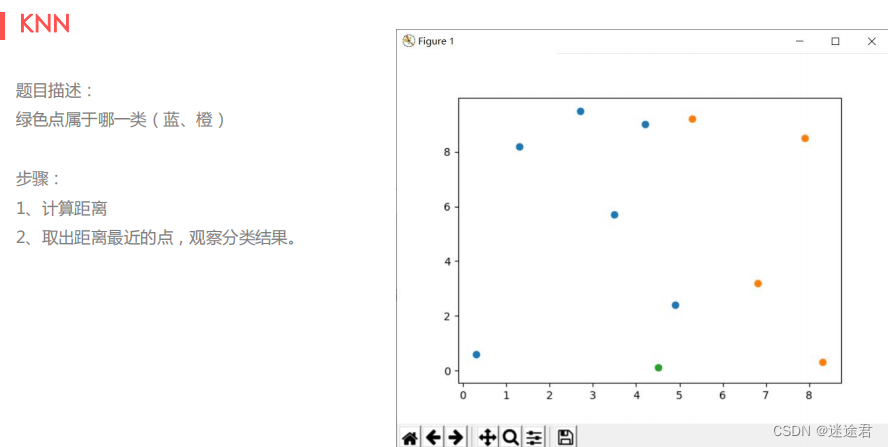
这里我直接从sklearn框架中的neighbors中导入k近邻法的分类器,不再使用数学法去计算点之间的距离:
import numpy as np
import matplotlib.pyplot as plt
# 从neighbors中导入k近邻法的分类器
from sklearn.neighbors import KNeighborsClassifier
def load_data():x = np.array([[0.3, 0.7],[1.2, 8.3],[2.7, 9.5],[3.5, 5.9],[4.1, 8.9],[4.9, 2.4],[5.1, 9.1],[6.8, 3.2],[7.8, 8.7],[8.3, 0.5]])# 准备标签:1表示蓝色阵营,0表示红色阵营y = np.array([1, 1, 1, 1, 1, 1, 0, 0, 0, 0])return x, ydef drawScatter(x, x_test):plt.scatter(x[: 6, 0], x[: 6, 1], c='b')plt.scatter(x[6:, 0], x[6:, 1], c='r')plt.scatter(x_test[0, 0], x_test[0, 1], c='g')plt.show()if __name__ == "__main__":# 获得数据集和标签集x_train, y_train = load_data()# 获得测试点x_test = np.array([[4.5, 0.1]])# 构造分类器对象,指定超参数classifier = KNeighborsClassifier(n_neighbors=7)# 让机器进行假学习训练classifier.fit(x_train, y_train)# 根据假学习得到的模型,进行测试点阵营预测pre = classifier.predict(x_test)print("测试点阵营:", pre)# 绘制图像drawScatter(x_train, x_test)注意:数据集和标签集需要一一对应起来。
K近邻法实现鸢尾花的识别
Iris 鸢尾花数据集是一个经典数据集。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征: 花萼长度(sepal length in cm)、花萼宽度(sepal width in cm)、花瓣长度(petal length in cm)、花瓣宽度 (petal width in cm)四个特征,将鸢尾花分为三类,分别为Iris Setosa,Iris Versicolour,Iris Virginica,每一类 都有50个样本。
# 从sklearn框架的datasets数据集模块导入load_iris函数
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
def load_data():# 获得框架中提供的鸢尾花数据集data = load_iris()# 提取特征数据,这里是字典类型所以直接间接用【key】来x = data["data"]# 提取标签数据y = data["target"]return x, yif __name__ == "__main__":# 1.获得训练的数据集和标签集x, y = load_data()# 2.获得测试的数据集和测试标签集# tran_test_split:将原始的数据集和标签集按照test_size为0.1的比例# 将原始的数据集和标签集分割成数据训练集,数据测试集,标签训练集,标签测试集# 其中测试集和训练集的记录比为1:9x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)print(x_train, len(x_test), x_test)# 3.创建分类器对象classifier = KNeighborsClassifier(n_neighbors=17)# 4.机器学习训练classifier.fit(x_train, y_train)# 5.预测pre = classifier.predict(x_test)print("预测:", pre)print("真实:", y_test)K近邻法实现手写数字识别
我们提前准备了2000个0-9的手写文件数据在当前文件夹,首先我们需要将这些数据进行处理成我们需要的数据集和对应的标签集,将每个数字文件的数据都整合成一行,这样我们就得到了【2000,1024】的二维矩阵,方便我们进行处理,但是识别效果其实不好,因为我们准备的手写数字数据量太少了,远远达不到想要的效果
import os
import cv2
import numpy as np
from sklearn.neighbors import KNeighborsClassifierdef load_data():x = []y = []# 遍历目录,得到所有文件名fileList = os.listdir("./trainingDigits/")print(fileList)for file in fileList:with open("./trainingDigits/" + file, "r") as fd:img = []for i in range(32):data = fd.readline()# 将每行数据的末尾的\n除去,循环结束,列表将会存储文件的所有数据,构成(1024, )的数组for j in data[: -1]:img.append(int(j))# 将一张文件的所有有效数据,追加到 x列表中,那么每个文件的数据就成为列表的 一个元素# 循环结束,那么x中将会存储所有文件的数据,构成 二维矩阵,(2000, 1024)x.append(img)# 准备标签y.append(int(file[0]))return x, y
def getTestData(fileName):img = cv2.imread(fileName)img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# img = np.resize(img, (32, 32))# img中图片数据变成 1 * 1024 [[.........]]img = img.reshape(1, -1)print(img.shape)return imgif __name__ == "__main__":# 获得训练的数据集和标签集x_train, y_train = load_data()# 获得测试数据x_test = getTestData("6_1.png")# 构造knn分类器对象classifier = KNeighborsClassifier(3)# 机器学习,训练,得到模型classifier.fit(x_train, y_train)# 预测pre = classifier.predict(x_test)print("预测数字: ", pre)KNNl 算法优点:(1)简单,易于理解,易于实现,无需估计参数。(2)训练时间为零。(3)KNN可以处理分类问题,同时天然可以处理多分类问题。(4)KNN还可以处理回归问题,也就是预测。(5)和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感。l 算法缺点:(1)计算量太大,尤其是特征数非常多的时候。每一个待分类文本都要计算它到全体已知样本的距离。(2)可理解性差,无法给出像决策树那样的规则。(3)是慵懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢。(4)样本不平衡的时候,对稀有类别的预测准确率低。当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。(5)对训练数据依赖度特别大,对训练数据的容错性太差。如果训练数据集中,有一两个数据是错误的,刚刚好又在需要分类的数值的旁边,这样就会直接导致预测的数据的不准确