项目用到了paddlespeech2,学了几天paddlepaddle,简单记录一下:
文章目录
- 1 手写数字识别任务
- 2 极简方案构建手写数字识别模型
- 模型设计
- 训练配置
- 训练过程
- 模型测试
- 3【手写数字识别】之数据处理
- 4【手写数字识别】网络结构
- 4.1 经典的全连接神经网络
- 4.2 卷积神经网络
- 5【手写数字识别】损失函数
- 5.1 Softmax函数
- 5.2 交叉熵
- 6【手写数字识别】优化算法
- 前提条件
- 设置学习率
- 学习率的主流优化算法
- 7【手写数字识别】之资源配置
- 单GPU训练
- 分布式训练
- 单机多卡程序
- 8【手写数字识别】之训练调试与优化
- 8.1 计算分类准确率,观测模型训练效果。
- 8.2 检查模型训练过程,识别潜在训练问题
- 8.3 加入校验或测试,更好评价模型效果
- 8.4 加入正则化项,避免模型过拟合
- 8.5 可视化分析
- 9【手写数字识别】之恢复训练
- 10 【手写数字识别】之动转静部署
- 动态图转静态图训练
- 动态图转静态图模型保存
- 动态图转静态图模型保存
- paddlespeech体验
- 1.流式语音识别服务
- 服务端使用方法
- ASR 客户端使用方法
- 2.流式语音合成服务
1 手写数字识别任务
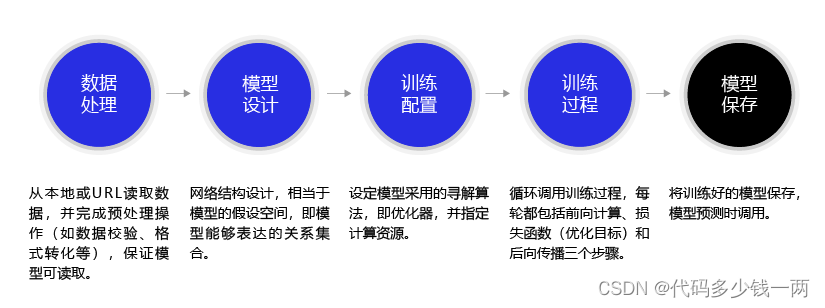
2 极简方案构建手写数字识别模型
首先要加载飞桨平台与“手写数字识别”模型相关的类库
通过paddle.vision.datasets.MNIST API设置数据读取器
# 设置数据读取器,API自动读取MNIST数据训练集
train_dataset = paddle.vision.datasets.MNIST(mode='train')
登录“飞桨官网->文档->API文档”,可以获取飞桨API文档。
模型设计
训练配置
训练过程
模型测试
3【手写数字识别】之数据处理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dQTIPeeR-1661928958262)(https://ai-studio-static-online.cdn.bcebos.com/257c74a23cef401c9db75fd2841bb93cdec28f756c6049b7b3e5ec1bf0ed058d)]
处理程序,一般涉及如下五个环节:
- 数据处理部分之前的代码,加入飞桨平台和数据处理库
- 读入数据并划分数据集
- 训练样本乱序、生成批次数据
- 校验数据有效性
- 封装数据读取与处理函数
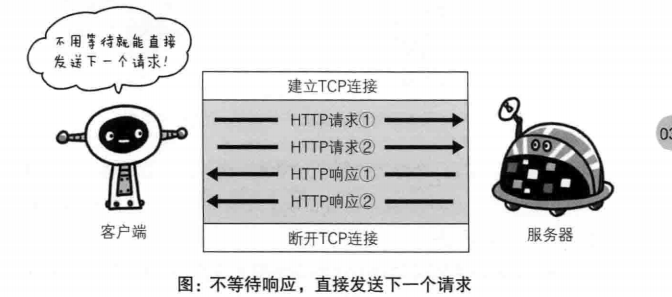
同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
飞桨实现异步数据读取,两个步骤:
- 构建一个继承paddle.io.Dataset类的数据读取器。
- 通过paddle.io.DataLoader创建异步数据读取的迭代器。
4【手写数字识别】网络结构
手写数字输入是28x28的像素值,输出是0-9的数字标签
线性回归模型无法捕捉
需要网络来构建:经典的多层全连接神经网络和卷积神经网络。
先进行数据处理
定义数据集读取器加载数据数据区分训练集,验证集,测试集校验数据定义数据集每个数据的序号, 根据序号读取数据定义数据生成器
4.1 经典的全连接神经网络
包含四层网络:输入层、两个隐含层和输出层
手写数字识别的任务,网络层的设计如下:
输入层的尺度为28×28,中间的两个隐含层为10×10的结构,激活函数使用常见的Sigmoid函数。
与房价预测模型一样,模型的输出是回归一个数字,输出层的尺寸设置成1。
4.2 卷积神经网络
卷积神经网络由多个卷积层和池化层组成,卷积层负责对输入进行扫描以生成更抽象的特征表示,池化层对这些特征表示进行过滤,保留最关键的特征信息。
5【手写数字识别】损失函数
损失函数是模型优化的目标,用于在众多的参数取值中,识别最理想的取值。损失函数的计算在训练过程的代码中,每一轮模型训练的过程都相同,分如下三步:
- 先根据输入数据正向计算预测输出。
- 再根据预测值和真实值计算损失。
- 最后根据损失反向传播梯度并更新参数。
5.1 Softmax函数
真实的标签值可以转变成一个10维度的one-hot向量,在对应数字的位置上为1,其余位置为0,比如标签“6”可以转变成[0,0,0,0,0,0,1,0,0,0]。引入Softmax函数可以将原始输出转变成对应标签的概率
对应到代码上,需要在前向计算中,对全连接网络的输出层增加一个Softmax运算,outputs = F.softmax(outputs)。
5.2 交叉熵
均方误差(常用于回归问题)、交叉熵误差(常用于分类问题)
基于最大似然思想,交叉熵只计算对应着“正确解”标签的输出的自然对数。
比如,假设正确标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是−log0.6=0.51;若“2”对应的输出是0.1,则交叉熵误差为−log0.1=2.30。正确解标签对应的输出越小,则交叉熵的值越大
交叉熵的代码实现:
手写数字识别任务中,仅改动三行代码,就可以将在现有模型的损失函数替换成交叉熵(Cross_entropy)。
- 在读取数据部分,将标签的类型设置成int,体现它是一个标签而不是实数值(飞桨框架默认将标签处理成int64)。
- 在网络定义部分,将输出层改成“输出十个标签的概率”的模式。
- 在训练过程部分,将损失函数从均方误差换成交叉熵。
6【手写数字识别】优化算法
上一节明确了分类任务的损失函数(优化目标)的相关概念和实现方法,本节主要探讨在手写数字识别任务中,使得损失达到最小的参数取值的实现方法。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wXkqVeM9-1661928958264)(https://ai-studio-static-online.cdn.bcebos.com/af41e7b72180495c96e3ed4a370e9e030addebdfd16d42bc9035c53ca5883cd9)]
前提条件
在优化算法之前,需要进行数据处理、设计神经网络结构,代码与上一节保持一致
设置学习率
深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。
学习率的主流优化算法
SGD、Momentum、AdaGrad和Adam
-
SGD: 随机梯度下降算法,每次训练少量数据,抽样偏差导致的参数收敛过程中震荡。
-
Momentum: 引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。
-
AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
-
Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
7【手写数字识别】之资源配置
单GPU训练
分布式训练
分布式训练有两种实现模式:
模型并行,将一个网络模型拆分为多份,拆分后的模型分到多个设备上(GPU)训练,每个设备的训练数据是相同的。适用于模型架构过大、网络模型的结构设计相对独立的场景。
数据并行,每次读取多份数据,读取到的数据输入给多个设备(GPU)上的模型,每个设备上的模型是完全相同的
模型是完全相同,但是输入数据不同,因此每个设备的模型计算出的梯度不同
梯度同步机制保证每个设备的梯度是完全相同:PRC通信方式和NCCL2通信方式
PRC通信方式通常用于CPU分布式训练,它有两个节点:参数服务器Parameter server和训练节点Trainer,parameter server收集来自每个设备的梯度更新信息,并计算出一个全局的梯度更新。Trainer用于训练,每个Trainer上的程序相同,但数据不同。当Parameter server收到来自Trainer的梯度更新请求时,统一更新模型的梯度。
飞桨的GPU分布式训练使用的是基于NCCL2的通信方式,相比PRC通信方式,使用NCCL2(Collective通信方式)进行分布式训练,不需要启动Parameter server进程,每个Trainer进程保存一份完整的模型参数,在完成梯度计算之后通过Trainer之间的相互通信,Reduce梯度数据到所有节点的所有设备,然后每个节点在各自完成参数更新。
单机多卡程序
- 初始化并行环境。
- 使用paddle.DataParallel封装模型。
启动多GPU的训练,有两种方式:
-
基于launch启动;
python train.py #单机单卡启动,默认使用第0号卡。 python -m paddle.distributed.launch train.py #单机多卡,默认使用当前可见的所有卡。 ython -m paddle.distributed.launch --gpus '0,1' --log_dir ./mylog train.py #单机多卡启动,设置当前使用的第0号和第1号卡。 或者 export CUDA_VISIABLE_DEVICES='0,1' python -m paddle.distributed.launch train.py -
基于spawn方式启动。
# 启动train多进程训练,默认使用所有可见的GPU卡。 if __name__ == '__main__':dist.spawn(train)# 启动train函数2个进程训练,默认使用当前可见的前2张卡。 if __name__ == '__main__':dist.spawn(train, nprocs=2)# 启动train函数2个进程训练,默认使用第4号和第5号卡。 if __name__ == '__main__':dist.spawn(train, nprocs=2, selelcted_gpus='4,5')
8【手写数字识别】之训练调试与优化
训练过程优化思路主要有如下五个关键环节:
8.1 计算分类准确率,观测模型训练效果。
交叉熵损失函数只能作为优化目标,无法直接准确衡量模型的训练效果。准确率可以直接衡量训练效果,但由于其离散性质,不适合做为损失函数优化神经网络。通常情况下,交叉熵损失越小的模型,分类的准确率也越高。基于分类准确率,我们可以公平地比较两种损失函数的优劣。
例如在【手写数字识别】之损失函数章节中均方误差和交叉熵的比较。使用飞桨提供的计算分类准确率API,可以直接计算准确率:
class paddle.metric.Accuracy该API的输入参数input为预测的分类结果predict,输入参数label为数据真实的label。
在模型前向计算过程forward函数中计算分类准确率
8.2 检查模型训练过程,识别潜在训练问题
如果模型的损失或者评估指标表现异常,通常需要打印模型每一层的输入和输出来定位问题,以及每层网络的参数,分析每一层的内容来获取错误的原因。
使用check_shape变量控制是否打印“尺寸”,验证网络结构是否正确。
使用check_content变量控制是否打印“内容值”,验证数据分布是否合理。
假如在训练中发现中间层的部分输出持续为0,说明该部分的网络结构设计存在问题,没有充分利用。
8.3 加入校验或测试,更好评价模型效果
- 校验集:用于对模型超参数的选择,比如网络结构的调整、正则化项权重的选择等。
8.4 加入正则化项,避免模型过拟合
过拟合现象:在训练集上的损失小,在验证集或测试集上的损失较大。反之,如果模型在训练集和测试集上均损失较大,则称为欠拟合。
导致过拟合原因:过拟合表示模型过于敏感,学习到了训练数据中的一些误差,而这些误差并不是真实的泛化规律,主要是训练数据量太少或其中的噪音太多。
过拟合的成因与防控:
情况1:训练数据存在噪音,导致模型学到了噪音,而不是真实规律。——使用数据清洗和修正来解决。
情况2:使用强大模型(表示空间大)的同时训练数据太少,导致在训练数据上表现良好的候选假设太多,锁定了一个“虚假正确”的假设。——限制模型表示能力,或者收集更多的训练数据。
正则化项:
为了防止模型过拟合,在没有扩充样本量的可能下,只能降低模型的复杂度,可以通过限制参数的数量或可能取值(参数值尽量小)实现。
具体来说,在模型的优化目标(损失)中人为加入对参数规模的惩罚项。当参数越多或取值越大时,该惩罚项就越大。通过调整惩罚项的权重系数,可以使模型在“尽量减少训练损失”和“保持模型的泛化能力”之间取得平衡。泛化能力表示模型在没有见过的样本上依然有效。正则化项的存在,增加了模型在训练集上的损失。
飞桨支持为所有参数加上统一的正则化项,也支持为特定的参数添加正则化项。前者的实现如下代码所示,仅在优化器中设置weight_decay参数即可实现。使用参数coeff调节正则化项的权重,权重越大时,对模型复杂度的惩罚越高。
8.5 可视化分析
- Matplotlib库:Matplotlib库是Python中使用的最多的2D图形绘图库,它有一套完全仿照MATLAB的函数形式的绘图接口,使用轻量级的PLT库(Matplotlib)作图是非常简单的。
- VisualDL:如果期望使用更加专业的作图工具,可以尝试VisualDL,飞桨可视化分析工具。VisualDL能够有效地展示飞桨在运行过程中的计算图、各种指标变化趋势和数据信息。
9【手写数字识别】之恢复训练
只要随时保存训练过程中的模型状态,即使训练过程主动或被动中断,也不用从初始状态重新训练。
模型恢复训练,需要重新组网,所以需要重启AIStudio,运行MnistDataset数据读取和MNIST网络定义、Trainer部分代码,再执行模型恢复代码
-
使用
model.state_dict()获取模型参数。 -
使用
opt.state_dict获取优化器和学习率相关的参数。 -
调用
paddle.save将参数保存到本地。何判断模型是否准确的恢复训练呢?理想的恢复训练是模型状态回到训练中断的时刻,恢复训练之后的梯度更新走向是和恢复训练前的梯度走向完全相同的。基于此,我们可以通过恢复训练后的损失变化,判断上述方法是否能准确的恢复训练。即从epoch 0结束时保存的模型参数和优化器状态恢复训练,校验其后训练的损失变化(epoch 1)是否和不中断时的训练相差不多。
总结一下:
- 保存模型时同时保存模型参数和优化器参数;
paddle.save(opt.state_dict(), 'model.pdopt')
paddle.save(model.state_dict(), 'model.pdparams')
- 恢复参数时同时恢复模型参数和优化器参数。
model_dict = paddle.load("model.pdparams")
opt_dict = paddle.load("model.pdopt")model.set_state_dict(model_dict)
opt.set_state_dict(opt_dict)
10 【手写数字识别】之动转静部署
动态图 交互式编程
静态图 C++提速 性能优势
动态图转静态图训练
动态图转静态图训练其原理是通过分析Python代码,将动态图代码转写为静态图代码,并在底层自动使用静态图执行器运行。
使用方法:在要转化的函数(该函数也可以是用户自定义动态图Layer的forward函数)前添加一个装饰器 @paddle.jit.to_static,使动态图网络结构在静态图模式下运行。
动态图转静态图模型保存
动态图是即时执行即时得到结果,并不会记录模型的结构信息。需要先将动态图模型转换为静态图写法,编译得到对应的模型结构再保存
paddle.jit.save和paddle.jit.load接口
三种文件:保存模型结构的.pdmodel文件;保存推理用参数的.pdiparams文件和保存兼容变量信息的.pdiparams.info文件*
paddle.jit.save API 将输入的网络存储为 paddle.jit.TranslatedLayer 格式的模型
it.to_static,使动态图网络结构在静态图模式下运行。
动态图转静态图模型保存
动态图是即时执行即时得到结果,并不会记录模型的结构信息。需要先将动态图模型转换为静态图写法,编译得到对应的模型结构再保存
paddle.jit.save和paddle.jit.load接口
三种文件:保存模型结构的.pdmodel文件;保存推理用参数的.pdiparams文件和保存兼容变量信息的.pdiparams.info文件*
paddle.jit.save API 将输入的网络存储为 paddle.jit.TranslatedLayer 格式的模型
paddle.jit.load接口,可以把存储的模型载入为 paddle.jit.TranslatedLayer格式
paddlespeech体验
1.流式语音识别服务
服务端使用方法
在 PaddleSpeech/demos/streaming_asr_server 目录启动服务
paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application.yaml
使用方法:
paddlespeech_server start --help
参数:
config_file: 服务的配置文件,默认: ./conf/application.yaml
log_file: log 文件. 默认:./log/paddlespeech.log
注意:
默认部署在 cpu 设备上,可以通过修改服务配置文件中 device 参数部署在 gpu 上。
ASR 客户端使用方法
paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
paddlespeech_client asr_online --help
参数:
server_ip: 服务端ip地址,默认: 127.0.0.1。
port: 服务端口,默认: 8090。
input(必须输入): 用于识别的音频文件。
sample_rate: 音频采样率,默认值:16000。
lang: 模型语言,默认值:zh_cn。
audio_format: 音频格式,默认值:wav。
punc.server_ip 标点预测服务的ip。默认是None。
punc.server_port 标点预测服务的端口port。默认是None。
2.流式语音合成服务
使用http协议的流式语音合成服务端及客户端使用方法
服務端:
paddlespeech_server start --config_file ./conf/tts_online_application.yaml
客戶端:
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input “您好,欢迎使用百度飞桨语音合成服务。” --output output.wav
使用websocket协议的流式语音合成服务端及客户端使用方法
首先修改配置文件 conf/tts_online_application.yaml, 将 protocol 设置为 websocket。
paddlespeech_server start --config_file ./conf/tts_online_application.yaml
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input “您好,欢迎使用百度飞桨语音合成服务。” --output output.wav






![[Java]快速入门二叉树,手撕相关面试题](https://img-blog.csdnimg.cn/79a615f6390b4c358ee4402f94b819ae.jpeg)
