作者:王辉 阿里智能互联工程技术团队
近年来人工智能发展迅速,模型参数量随着模型功能的增长而快速增加,对模型推理的计算性能提出了更高的要求,GPU作为一种可以执行高度并行任务的处理器,非常适用于神经网络的推理计算,因此近年来在人工智能领域得到广泛关注与应用。
本文将结合我在阿里智能互联云端模型推理部署方面半年以来的工作学习,对相关的GPU编程与云端模型部署的知识与经验进行总结分享,下文内容为个人学习总结,如有疏漏与错误,还请各位不吝赐教。如有同样对云端模型推理部署、GPU计算优化、大模型推理部署相关技术感兴趣的同学,非常高兴能够进行相互的交流学习。
一、CUDA编程基础
CUDA是一种通用的并行计算平台和编程模型,它可以让用户在NVIDIA的GPU上更好地进行并行计算以解决复杂的计算密集型问题。本章将主要介绍GPU的相关基本知识、编程基础以及相关的部署要点。
1.1 NVIDIA GPU系列与硬件结构简介
NVIDIA的GPU产品主要是根据其应用场景进行划分的,主流的产品主要分为三个系列,分别是用于消费级显示与游戏的GeForce系列显卡(如我们熟悉的RTX 1080、RTX 3090等),用于专业图形化工作站的Quadro系列以及用于数据中心和高性能计算的Tesla系列(如T4、V100等<Ampere之后不再用Tesla>),除此上述三种主流的系列之外,还有用于嵌入式设备的Jetson系列的显卡。
用于企业进行高性能计算的Tesla系列显卡根据其所采用的架构的计算能力由低到高分为Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere以及Hopper。
注:本节图片均来自于nvidia官方网站
https://images.nvidia.cn/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf#cid=_pa-srch-baid_zh-cn
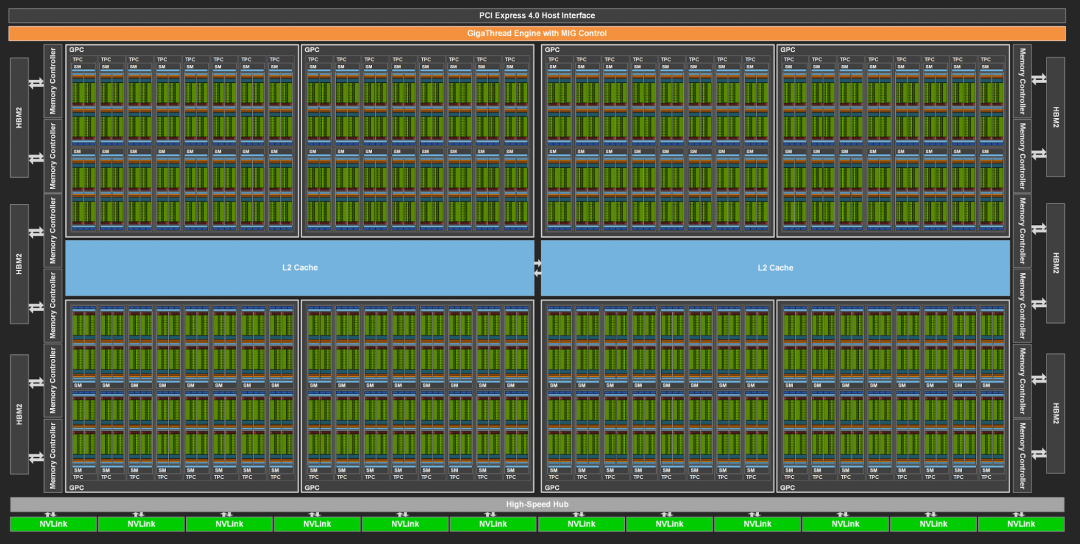
A100硬件架构图
从硬件架构上看,GPU拥有更多的简单计算资源,较少的逻辑控制资源并且单个SM的缓存资源也较小;而CPU片上拥有较少的复杂计算资源,同时拥有较多的逻辑控制资源以及较大的缓存。GPU的计算资源是以SM(Streaming Multiprocessor)划分的,以A100为例,该款GPU拥有108个SM,单个SM中有4个子块,1个线程束调度器,每个子块中拥有16个INT32和FP32核心、8个FP64核心、1个TensorCore、1个SFU(特殊函数单元)以及8个LD/ST(数据加载存储单元)。
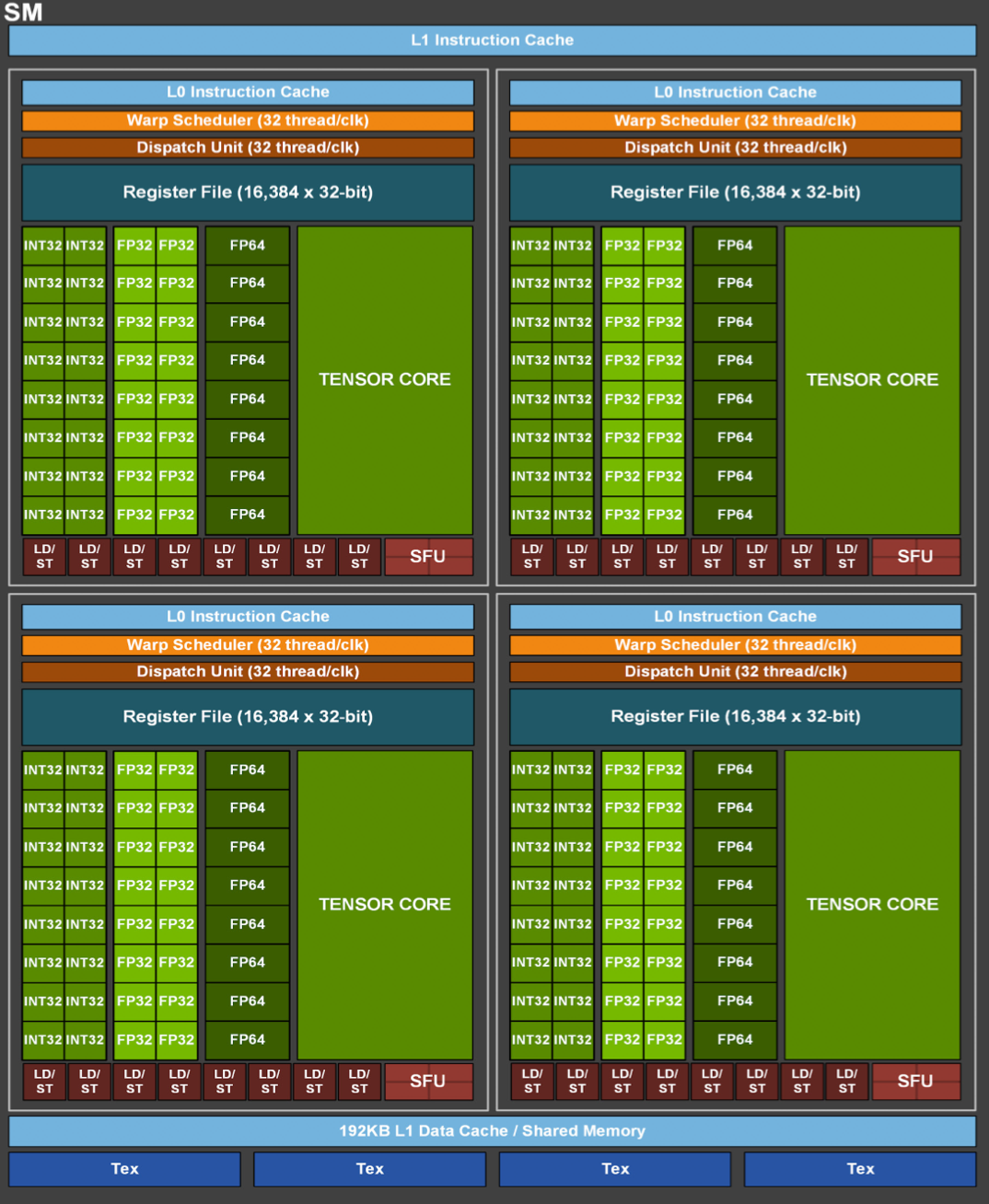
A100单SM示意图
在存储空间方面,GPU片上的内存分为全局内存、常量内存、纹理内存、共享内存、L0/L1/L2缓存以及寄存器。全局内存、常量内存与纹理内存对全局可见,L2缓存对部分SM共有,L1缓存和共享内存对单个SM可见,而L0缓存和寄存器只对单个子块可见,有些GPU的SM中没有子块,即L0缓存和寄存器也对SM可见。
我们为什么要用GPU计算,特别是用于人工智能推理呢?我看过一个很形象的说法,CPU是一个大学数学教授,而GPU的一个核心是一个小学生,当面对一道困难的微积分题目和一万道100以内的加减法时,该怎么做才能既得到正确结果又最短时间获得结果呢?面对复杂的微积分问题(复杂运算与逻辑控制),当然让大学教授(CPU)去解决,而面对简单却数量庞大的问题(计算量很大的加减乘除问题),让很多的小学生(GPU)一起去做才能在最短时间内获得答案。因此如何根据CPU和GPU的特性,去分配不同的计算任务在不同的硬件上执行与调度,以获得最佳的计算性能和资源利用,这是异构计算最主要的目标之一,本章下文将主要针对如何利用CUDA在GPU上编程来进行一些我自己的学习总结与经验分享。
1.2 CUDA编程模型
我们都知道线程是CPU调度的基本单位,而GPU上计算资源是如何调度呢?在CUDA中,线程调度是按照线程束(Warp)去调度的,每个线程束含有32个线程,若干个线程束构成线程块,若干线程块组成一个网格。为便于陈述,通常约定CPU操作为主机端(Host),而GPU操作为设备端(Device)。
当主机端发起一个CUDA kernel时,便在设备端启动一个网格(Grid),一个网格中的不同线程块分布在不同的SM中,但是相同线程块的所有线程束一定在同一个SM中被执行,一个SM可能有多个线程块。可以这样理解硬件与软件概念之间的关系:GPU-网格,SM-线程块,CUDA core-线程。
值得注意的是:
-
线程束在被调度的时候一定是以32为整体进行调度,因此当我们启动60个线程时,在网格内实际存在64个活跃的线程。
-
在大部分型号的GPU上,一个线程块中最多存在1024个线程,而线程块的数量限制一般很大,可以通过cudaGetDeviceProperties进行查询
int dev = 0;
cudaSetDevice(dev);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("Maximum number of threads per multiprocessor: %d\n", deviceProp.maxThreadsPerMultiProcessor);
printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock);
printf("Maximum sizes of each dimension of a block: %d x %d x %d\n",deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]);
printf("Maximum sizes of each dimension of a grid: %d x %d x %d\n",deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);- 如果一个SM中存在多个线程束调度器,则同时一个SM中会有多个线程束被调度。
通常一个GPU并行计算的完整简单流程为:
-
在主机端申请适当大小的显存用于存放输入数据以及接收输出,将主机端的数据拷贝到设备端;
-
在设备端进行计算,得到结果;
-
将输出从设备端拷贝回主机端,销毁显存。
首先介绍第一步和第三步的相关API,相关函数和C语言的相关内存操作非常相似,有不同的是对于设备端之间的内存拷贝,存在异步操作,相关介绍如下:
//在设备端申请显存
cudaMalloc(void** ptr, size_t size);
//设置显存的值
cudaMemset(void* ptr, int value, size_t size);
//内存拷贝,阻塞
//有cudaMemcpyHostToHost、cudaMemcpyHostToDevice、cudaMemcpyDeviceToHost、cudaMemcpyDeviceToDevice
cudaMemcpy(void* dst_ptr, void* src_ptr, size_t count, cudaMemcpyKind kind);
//异步拷贝,不阻塞
cudaMemcpyAsync(void* dst_ptr, void* src_ptr, size_t count, cudaMemcpyKind kind, stream_t stream);
//内存释放
cudaFree(void* ptr);注意:所有的长度都要乘以数据类型的实际字节数。
接下来介绍第二步,启动核函数,通常所有在GPU执行的核函数都要编写在.cu文件中,通过对外提供C接口被调用。而核函数之前通常要添加函数类型限定符__global__,device,host,分别代表该核函数可以从全局被调用在设备端执行、只能从设备端被调用只设备端执行、只能从主机端被调用只能在主机端执行(通常省略)。而__device__,__host__可以一齐使用代表该核函数即可同时在主机端和设备端被编译。
值得注意的是:
-
所有核函数返回值必须是void
-
不支持静态变量
-
只能访问设备空间
-
不支持可变数量参数
在启动核函数时,我们需要在函数调用名字之后添加三个尖括号<<<>>>,需指定启动网格大小(多少个线程块)和线程块(多少个线程)大小,第三个参数为动态分配的共享存储器大小,通常为0,第四个参数为stream,在同步操作时也默认为0。而网格和线程块的大小,也需要通常需要根据下式或者别的方式计算得到。
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void helloworld_kernel()
{printf("hello world!\n");
}
void helloworld(int len)
{int ilen = 64;dim3 block(ilen);dim3 grid((len+block.x-1)/block.x);helloworld_kernel<<<grid,block>>>();
}
int main()
{int thread = 100helloworld(thread);return 0;
}我们编写的核函数,在设备端会存在非常多的线程执行,那核函数怎么知道自己在全局的位置呢?在每个核函数的内部,存在四个自建变量,gridDim,blockDim,blockIdx,threadIdx,分别代表网格维度,线程块维度,当前线程所在线程块在网格中的索引,当前线程在当前线程块中的线程索引,每个变量都具有三维x、y、z,可以通过这四个变量的转换得到该线程在全局的位置。
int idx = blockIdx.x * blockDim.x + threadIdx.x;
//假设网格和线程块都是一维启动启动kernel时,设定的grid和block大小会对函数的性能产生一定影响,通常需要对这两个变量进行一定的调试,以获得较好的性能,而产生影响的原因,主要是根据每个函数所占用的资源以及cuda的执行模型决定,不同的启动参数会由于不同的寄存器占用等而导致不同的线程调度以及内存访问的延迟隐藏。
1.3 CUDA执行模型
与我们熟知的SIMD(单指令多数据)相似,GPU中每个SM中采用SIMT(单指令多线程)的架构进行线程的管理与执行,以线程束32个线程为单位进行调度与执行。
当CPU发起一个cuda kernel的时候,每个线程在哪个SM上所执行已经被确定,线程块一旦被调度到某个SM上,该线程块会在该SM上并发执行直到执行完毕。线程块被分配到哪个SM是由每个SM空闲的资源(寄存器、共享内存和剩余活跃线程数等)决定,一个SM可以同时执行多个线程块,这些线程块既可以来自于同一个kernel所发起,也可以来自于不同kernel所发起。
从SM之间的层次来看,不同SM之间的线程束确实从物理层面可能在并行执行,但是在单个SM内,每个线程束只是逻辑层面的并行执行,但从物理层面所有的线程束并不是同时进行,它们是并发地被SM中的线程束调度器调度执行。与CPU的线程切换不同,在GPU内,活跃的线程束切换并不会引起上下文切换的开销,因为在线程束被某个SM执行时,所有的共享内存和寄存器资源已经被分配完成,因此线程束的切换并不需要像CPU那样进行寄存器等上下文的切换。
然而SM内的资源是有限的,因此SM内的活跃线程束的数量是有限制的,它受到SM内资源限制以及硬件上最大活跃线程束数量的限制,不同硬件的SM最大活跃线程束的数量同样可以通过cudaGetDeviceProperties进行查询(查询到线程数量,线程束=线程数量/32)。如上文提及,线程束的调度一定是以32为整数进行调度,即使某个线程束中的实际kernel所需的线程数量不足32,但也会实际占用32个线程的硬件和内存资源。
每个被分配到资源的线程束被称为活跃的线程束,所有活跃的线程束有三种状态:选定的线程束,阻塞的线程束,符合条件的线程束。正在被执行的线程束称为选定的线程束,由于等待某种条件而等待的线程束称为阻塞的线程束,已经准备就绪等待执行的线程束称为符合条件的线程束。
下面针对CUDA执行模型的几个要点进行总结。
1.3.1 延迟隐藏
通常GPU具有比CPU片上更少的缓存资源,因此通常CUDA kernel会从全局内存中读取数据,但这会导致GPU上函数相比于CPU函数具有更长的访存延迟(通常为400-800个左右的时钟周期)。为了隐藏这种延迟通常使每个SM上不止执行一个线程束,通过多个线程束交替执行,从宏观上让SM一直处于运行状态,以达到延迟隐藏的目的。
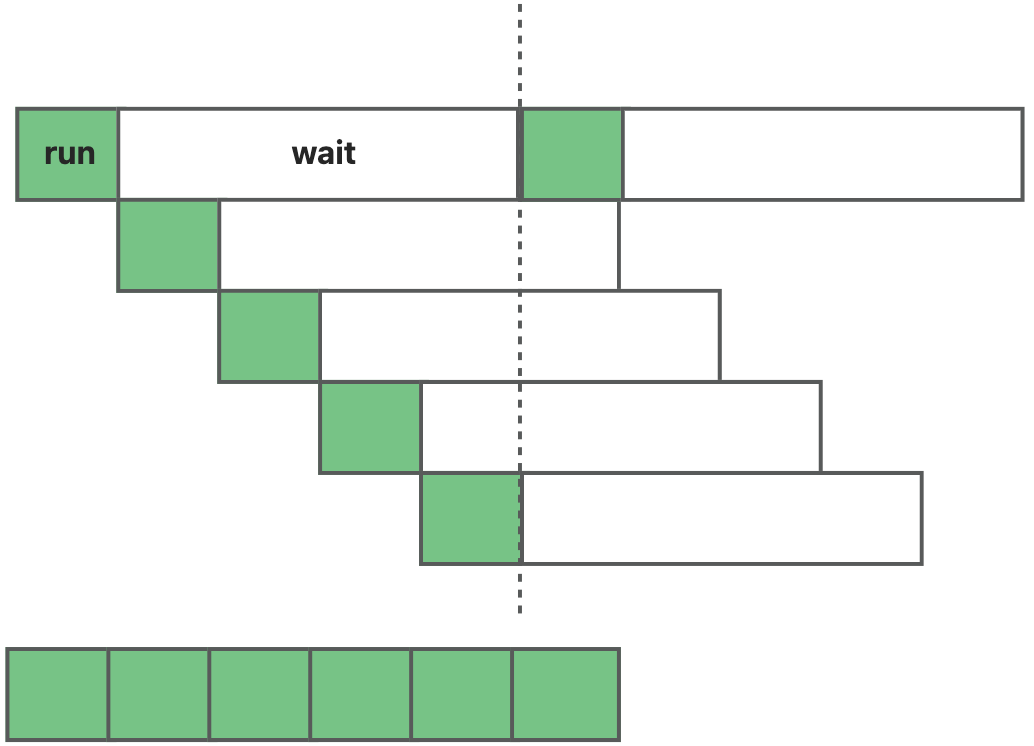
为更好地说明延迟隐藏的效果,在A10卡(72个SM)上进行elementwise_add的操作,每个线程执行三个读操作,一次写操作和一次加法操作,采用不同大小的grid和block进行实验,每次运算迭代100次测得总时间,实验结果如下表。

从实验结果中看,当线程束的数量大于SM数量,但是不算很大时,算子的RT几乎相近,因为每个线程的访存延迟相比于计算时间长的多,所以延迟隐藏之后,对整体的计算延迟没有太大的影响,但是当线程数量过大时,一个访存延迟时间不足以完成所有的线程发出访存指令,因此计算延迟会受到影响。但我们也可以看到不同的grid和block大小对性能也是有影响的,在kernel开发时,需要通过调节相应的grid和block大小获得最佳性能。
1.3.2 避免分支分化
由于GPU的SM是按照SIMT的方式执行,因此在一个线程束执行时,会执行相同的指令,如果kernel中存在if···else···语句,那么GPU会执行两个分支的代码,只是最终隐藏不符合条件的结果,这样会导致执行的指令数量变多,导致性能下降,因此在一个线程束内,应尽量避免出现分支分化。这样的限制存在于单个线程束内,在不同的线程束之间出现分支分化,一般来说对性能的影响会比较小。
但是有一种特例,当kernel中只存在if语句而不存在else时,对整体的性能影响较小。
相关实验网络上较多,不再展示实验结果。
1.3.3 并行规约
在向量中满足分配律和结合律的运算称为规约(reduce)。与elementwise运算不同,reduce会根据线程索引发生分支分化,严重影响性能,如何增加并行性是规约问题的主要优化方向。下文展示两种并行规约的代码,并分析影响其性能的因素。
unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
// convert global data pointer to the local pointer of this blockint *idata = g_idata + blockIdx.x * blockDim.x * 8;
// unrolling 8if (idx + 7 * blockDim.x < n){int a1 = g_idata[idx];int a2 = g_idata[idx + blockDim.x];int a3 = g_idata[idx + 2 * blockDim.x];int a4 = g_idata[idx + 3 * blockDim.x];int b1 = g_idata[idx + 4 * blockDim.x];int b2 = g_idata[idx + 5 * blockDim.x];int b3 = g_idata[idx + 6 * blockDim.x];int b4 = g_idata[idx + 7 * blockDim.x];g_idata[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;}
__syncthreads();
// in-place reduction and complete unrollif (blockDim.x >= 1024 && tid < 512) idata[tid] += idata[tid + 512];
__syncthreads();
if (blockDim.x >= 512 && tid < 256) idata[tid] += idata[tid + 256];
__syncthreads();
if (blockDim.x >= 256 && tid < 128) idata[tid] += idata[tid + 128];
__syncthreads();
if (blockDim.x >= 128 && tid < 64) idata[tid] += idata[tid + 64];
__syncthreads();
// unrolling warpif (tid < 32){volatile int *vsmem = idata;vsmem[tid] += vsmem[tid + 32];vsmem[tid] += vsmem[tid + 16];vsmem[tid] += vsmem[tid + 8];vsmem[tid] += vsmem[tid + 4];vsmem[tid] += vsmem[tid + 2];vsmem[tid] += vsmem[tid + 1];}
// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = idata[0];
}上述两种方法将长度为16777216的整数进行求和规约,第一种方法在A10卡上0.574ms,第二种方法0.179ms,性能快了3倍。
规约问题通常涉及到循环与同步,CUDA的线程采用__syncthreads()进行同步,并且只能在同一个线程块内同步,不同线程块无法同步,因此每个线程块内求和得到的结果需要最终在cpu中或者再次起kernel求得。
两种方案的差别导致性能差异的分析如下:
-
前者在一个线程块内的显存范围进行求和,后者在8个线程块内的显存范围进行求和,降低了得到结果后在cpu进行求和的计算量,提高了kernel计算的并行度;
-
前者采用相邻配对,而后者采用交错配对,虽然交错配对不会对分支分化产生影响,但是对全局内存的访问方法存在差异,对性能产生一定的优化;
-
后者在与不同位置的值求和时,没有采用循环,而是直接将循环展开,这样做省略了for循环时进行的条件判断等操作耗时;
-
当最终活跃的线程数量小于32时,没有在每次加法后进行同步,而是在一个线程束里面直接展开循环,因为CUDA执行是SIMT的方式,从指令层隐式同步了每一次加法,从而可以省略掉最后6的加法后同步,但此时要注意局部求和的结果用volatile进行修饰,以保证每次的结果直接写入全局内存,而不是暂存在缓存中从而导致运算结果不同步。
1.4 CUDA内存模型
CUDA的内存模型较为复杂,笔者也在逐渐摸索,所以在此仅介绍一些基本的性能概念。
GPU上的内存分为全局内存、常量内存、纹理内存、共享内存、L0/L1/L2缓存以及寄存器。
-
全局内存是GPU上面最大的内存,但是读取速度也是最慢的,通常在不进行运算时,数据都存在于全局内存,用户可编程进行读写。
-
常量内存也是GPU上一块对所有线程可见的内存,里面存的数据只能由主机编程写,对核函数只能读取,除此之外在GPU上还有一块常量内存缓存,读取速度比全局的内存较快。
-
纹理内存也是一种存放常量的内存,以前是用于图形处理,由于其存储地方处于片上,因此读取速度比全局内存快。
-
共享内存位于SM中,对每个线程块可见,读取速度较快,通常这里的数据用于线程块内的数据交换,是用户可编程读写内存。
-
L0/L1/L2不同级别的缓存存储的位置由小到大,但其读取速度由快到慢,是不可编程缓存。
-
寄存器是GPU上面读取速度最快的内存,但也是空间最小的内存,它与共享内存一样是GPU上最稀缺的资源,通常也是制约活跃线程束的重要因素之一,用户可编程读写,通常核函数内的自变量存在于寄存器中。
对于频繁进行D2H和H2D内存拷贝操作时,通常我们可以将CPU内存固定页面在内存中,以防止页面切换导致的开销,可以通过cudaMallocHost进行申请,这样当数据进行传输时,可以直接利用主机DMA进行数据拷贝。但是过多的固定页面内存会导致主机性能的下降,需要根据性能结果进行微调。
1.5 多流
多流在GPU编程中是一个非常重要的特性,对于充分利用GPU计算资源以及提高程序的并行度具有重要意义。流是指一连串有先后顺序的异步操作,按照顺序在设备上执行。一般在多线程程序中,可以通过多流,使多线程中不相关的操作堆叠执行,提高GPU计算的并行度,实现网格级并发。
前面提到过,通常最简单的CUDA程序有三步,先将数据从主机拷贝到设备,在设备上进行计算,将数据从设备拷到主机。通过多流技术,既可以让同一个流上的异步操作按顺序执行,也可以让不同流上的操作重叠执行。
之前我们所使用的同步cuda操作,都是使用系统的默认流,而默认流通常认为和其他用户自定义的流是冲突的,即默认流不能和用户自定义的流重叠执行。
在使用用户自定义的流之前,需要先对流进行初始化:
cudaStream_t stream;
cudaStreamCreate(&stream);
cudaStreamDestory(stream);通常使用的异步cuda操作有两种,kernel和memcpy,对kernel使用多流时,只需要在启动kernel的<<<>>>中的第四个参数传入流即可,通常kernel只要在GPU计算资源充足的情况下,即可实现多流重叠执行,但当GPU相关计算或者寄存器等资源不足时,也会存在等待的情况。
···
kernel<<<grid, block, 0, stream>>>(···);
···memcpy的异步操作需要使用异步的API,可以实现H2D、D2H、D2D的重叠执行,其中D2D之间也可以实现重叠执行,由于PCIE接口是全双工通信,H2D和D2H之间可以重叠执行,但是多个H2D或者多个D2H之间由于抢占PCIE的接口资源,不能重叠执行。
cudaMemcpyAsync(void *dst, void *src, size_t size, cudaMemcpyKind kind, cudaStream_t stream);
对于主机和设备之间的memcpy,当cpu内存是malloc申请的,这一块内存可能会因为分页导致需要先加载数据到内存,再进行拷贝,因此通常会把cpu内存注册为pinned内存,这样在memcpy的时候可以利用DMA直接进行拷贝,提高拷贝性能。
cudaError_t cudaMallocHost(void** ptr, size_t size);
cudaError_t cudaHostAlloc(void** pHost, size_t size, unsigned int flags);当我们的程序需要在某个操作之后等待GPU完成所有计算,再执行一下步操作时,需要对流进行同步。
cudaStreamSynchronize(stream);1.6 GPU性能profile工具Nsight System简介
Nsight System是一款用于GPU性能profile的工具,通常从nsight上可以直观看到CPU和GPU执行的情况,并由此分析计算性能瓶颈,并且可以查看线程情况,CUDA api以及cpu程序api等,同时也可以查看更加详细的gpu占用情况,网卡情况以及tensorrt,cudnn等调用情况。
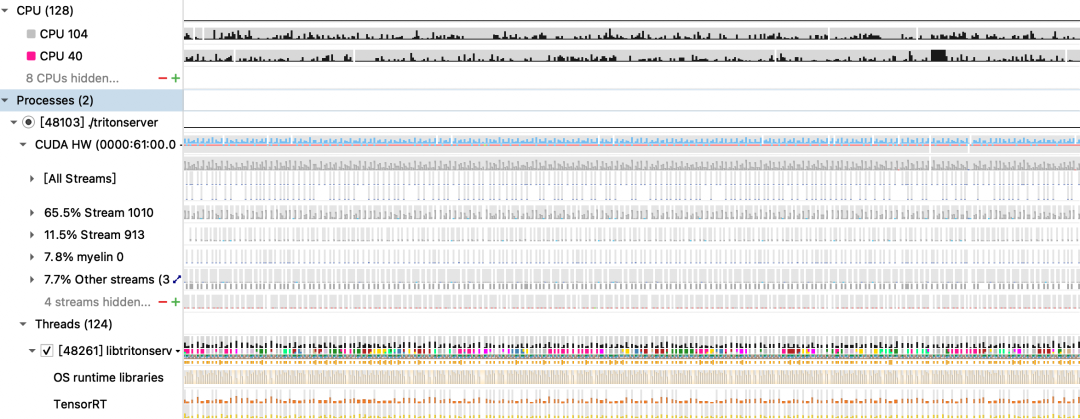
上图是一张nsight的性能测试结果,从途中我们可以很轻松看到cpu占用情况,gpu在某个时刻是在memcpy还是执行kernel,每个流的占用,每个线程的api调用等。
调用nsight的命令非常简单,并且可以通过--trace指定需要生成哪些信息的报告(比如cuda、cudnn、cublas、nvtx,在较新版本中还可以查看nccl),--duration可以指定抓多长时间的包,--sampling-frequency可以指定采样频率(100~8000),其他的选项可以查看下方链接中的官方使用文档。
nsys profile [option] [exec]当我们需要profile的程序启动时间比较久时,我们希望nsight延迟启动抓包,可以先nsys launch [exec]再通过nsys start和nsys stop来启动和停止抓包
https://developer.nvidia.com/nsight-systems
https://docs.nvidia.com/nsight-systems/UserGuide/index.html
1.7 编程小经验
1.7.1 cuda版本兼容性
做GPU、TensorRT应用部署的小伙伴经常为版本问题烦恼,比如trt8.2要求cuda版本一般为11.4,这时要求GPU驱动至少为470.57.02,而对于企业来讲,通常cuda版本可以通过改变容器镜像来升级,但GPU驱动版本是由宿主机决定,对于云端部署的应用来讲,GPU驱动版本是不易修改的,那我们怎么部署依赖较新cuda版本的应用呢?
在谈论这个问题之前,我们首先了解两个概念Driver API(驱动API)和Runtime API(运行时API),驱动API存在与libcuda.so中,而运行时API存在与libcudart.so中,通常我们在读取驱动信息时,会访问驱动API,通常我们熟悉的nvidia-smi就是访问这里的信息。当我们访问nvidia-smi时,显示的GPU驱动是宿主机的驱动版本,而显示的cuda版本,并不是我们容器内安装的cuda版本,而是该GPU驱动版本下允许安装的最高cuda版本。在我们实际进行GPU计算时,会调用运行时API,也就是通过libcudart.so进行调用。
在cuda10.x及以前,我们要求cudnn,cublas等GPU应用与库必须依赖对应的cuda版本,且必须有足够高的GPU版本,如果版本不对应则会出现不能正常运行的问题。在cuda11.x之后,NVIDIA对cuda提供了次级版本兼容性,使用相同cuda主要版本的 cuda工具包版本编译的应用程序可以在至少具有最低要求驱动程序版本的系统上运行,但是其功能可能会被限制。下图是NVIDIA官方文档提供的cuda11.x和12.x最低驱动版本限制的表格。

所以当我们宿主机版本在450.80.02+时,我们可以安装cuda11.x版本的工具包,并直接运行仅依赖cuda的应用。但当依赖cudnn和cublas时,我们仍然要考虑他们之间版本的对应,但是通常这些库版本升级较为容易。值得注意的是当我们的应用程序依赖了ptx优化时,需要通过后面的前向兼容来解决兼容性问题。以下是我在cuda11.2的系统内使用trt8.4(依赖cuda11.6)编译的引擎模型时,运行tritonserver时报的错误,通过前向兼容可以解决这个问题。那么要怎么使用前向兼容呢?
UNAVAILABLE: Internal: unable to create stream: the provided PTX was compiled with an unsupported toolchain
虽然一直以来cuda11.x的应用可以直接在低版本的驱动环境内运行,但是一些有别的依赖的应用仍需要较高的驱动版本才能运行,此时可以通过安装NV的前向驱动包解决这个问题。例如当我们在460版本的驱动环境中使用cuda11.6时,且依赖与cuda11.6对应的ptx工具时,可以通过下述命令(alios7)安装兼容包。
sudo yum install -y cuda-compat-11-6安装之后通常会存在/usr/local/cuda-11.6/compat目录,将该目录override系统的库目录LD_LIBRARY_PATH,此时大家可以nvidia-smi看一下,是不是惊喜发现允许的最高cuda版本变高了(但驱动版本是没有变的哦)。该目录下存在以下四个文件:
-
libcuda.so.* 驱动程序
-
libnvidia-nvvm.so.* JIT-LTO(cuda11.5以上)
-
libnvidia-ptxjitcompiler.so.* PTX的实时编译器
-
libcudadebugger.so.* 调试程序(cuda11.8以上)
以下是NVIDIA官方文档中的兼容性支持表格。
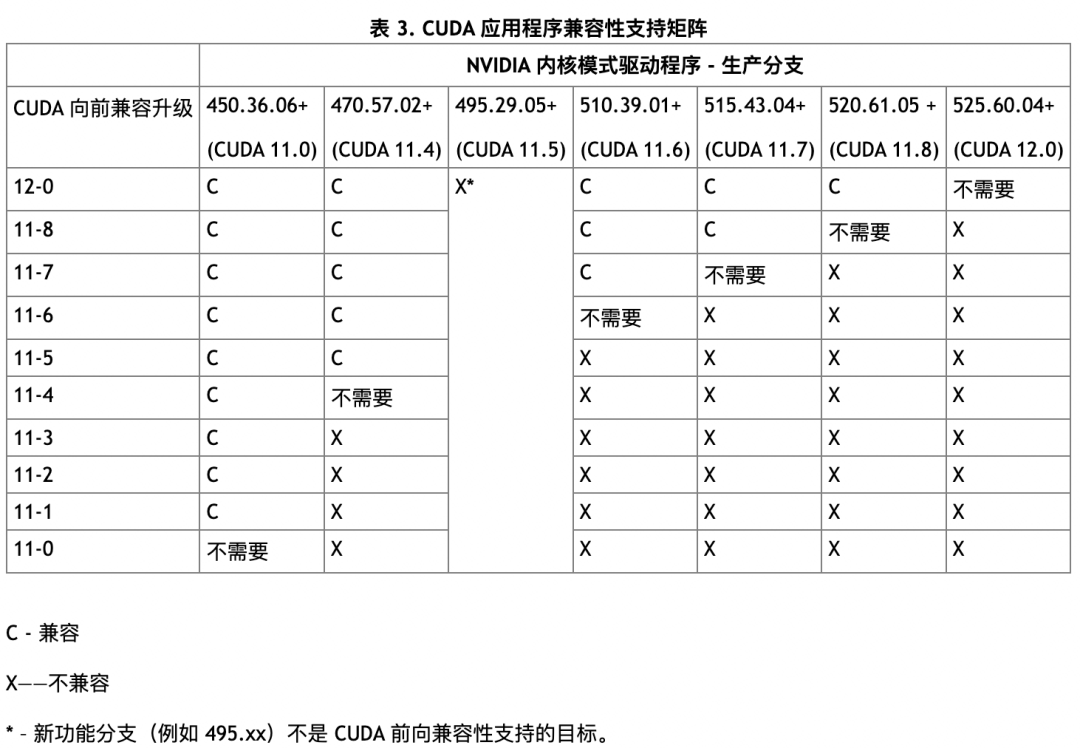
https://docs.nvidia.com/deploy/cuda-compatibility/index.html
1.7.2 避免多次D2D内存拷贝
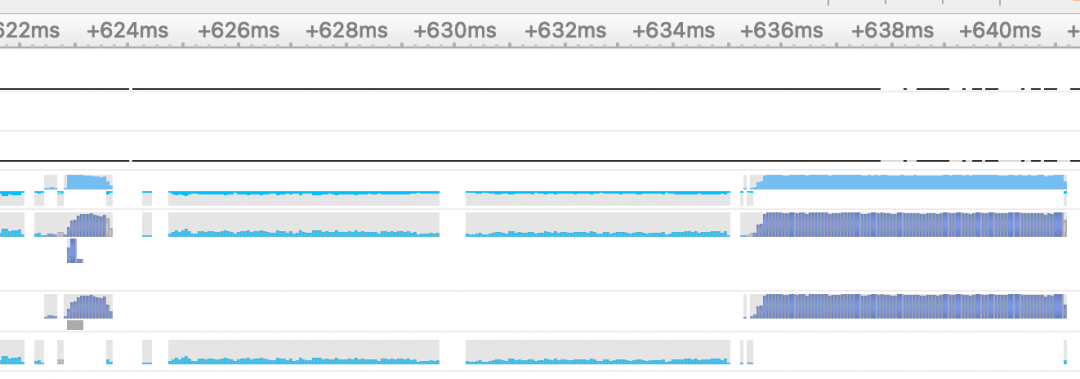
GPU通常用于处理大规模并行计算,特别是在人工智能领域,我们通常通过组batch的方式提高并行度,可能某个逻辑处理原因,我们会在GPU内多次D2D的进行显存拷贝。由于每次显存拷贝需要CPU发送指令,即使采用流的方式,也会导致每次cpy之间存在空隙,且无法有效利用显存带宽,导致GPU利用率较低,虽然可以通过多流的方式隐藏延迟,但是从一个请求的角度看,RT仍然较高。如下图是一个多次拷贝的profile结果,从图中可以看到D2D的memcpy(浅蓝色),持续时间较长。
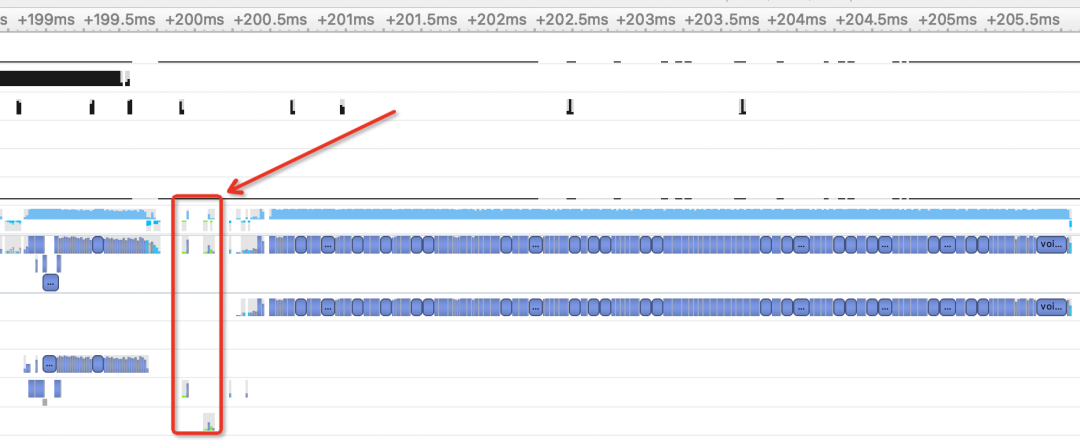
对于D2D的内存拷贝,我们为解决这种问题,自己写了一个kernel手动进行赋值操作,一般这种情况下是多组空间不连续的显存进行拷贝,所以我们先存储每块显存的首地址和数据长度以及目标地址在cpu上进行存储,然后拷贝到GPU上,通过起一个kernel的当时进行一对一的赋值,这样可以在高并发的情况下,将起cpy或者kernel的次数从N次变为4次,这样可以缩短很多时间(当然,并发比较低时候,两种方式的rt都不高)。以下是优化之后的同样并发下,Nsight profile之后的结果,可以看到非模型推理时间大幅度降低,甚至之前需要将近10ms才能完成的cpy操作变得连1ms都不到。
二、TritonServer模型部署与业务实践
2.1 Triton功能简介
TritonServer是NVIDIA发布一款开源的推理服务软件,可以简化AI推理的部署复杂度,提高AI开发人员的开发效率,使用Triton可以部署多种机器学习框架的AI模型,比如pytorch、tensorflow、TensorRT、ONNX以及FasterTransformer等,当然也可以用户自定义编写backend用于推理。
Triton服务器在模型推理部署方面拥有非常多的便利特点,大家可以在官方github上查看,笔者在此以常用的一些特性功能进行介绍(以TensorRT模型为例)。大家尝试使用的话,可以直接下载nv的NGC容器进行尝试(自己编译tritonserver非常痛苦)。
https://github.com/triton-inference-server/server
2.1.1 模型配置
笔者认为triton最方便的一点便是自动化的多模型部署,想一下如果我们一张GPU上只部署一个普通的模型,会不会存在GPU利用率很低的情况呢,这样肯定会导致成本的增长与资源的浪费;如果我们一张GPU上部署多个模型,那么对于每种框架,我们需要编写复杂的业务和工程代码以使多个模型在同一个镜像内运行起来,并对外提供服务,这样极大影响了AI工程师的开发效率,并且稳定性也需要验证。通过利用triton,我们可以很方便将目前通用框架的模型不用编写工程代码很方便的部署起来,并且一台机器上可以部署多个模型,以及一个模型的多种版本。
当然,我们在部署模型的时候需要为triton提供一份模型的配置文件,对于同一种模型,通常只需要提供一份配置文件即可(config.pbtxt),然后将模型文件按照版本一起提供给triton,即可开启triton进行服务。以下列出tirton模型仓库的目录结构。
model_repo|-model_1|-config.pbtxt|- 1|-model_1.plan|- 2|-model_1.plan|-model_2|-config.pbtxt|- 1|-model_2.plan#启动命令
tritonserver --model-repository model_repo以下给出最简单的配置文件,并对里面的模块进行介绍。根据triton的介绍,对于使用最简单的模型配置,可以不需要用户显式提供配置文件,但是目前笔者还没有尝试过,因为一般都会在基础配置上添加一些额外配置,所以还是提供一份配置文件放心一点。
-
name:模型名字,需要和该模型的根目录名字一样;
-
backend:用于执行模型的后端,可以是tensorrt、tensorflow、python、pytorch以及用户自定义后端;
-
max_batch_size:最大batch_size(用于输入输出不包含batch,且支持动态批处理的模型,对于不支持动态批处理的模型,只能设置为0);
-
input、output:内含模型的每个输入、输出;
-
input-name:输入的名字,一半可以通过在onnx状态模型去查看;
-
input-data_type:类型,有TYPE_FP32、TYPE_INT8、TYPE_FP16、TYPE_STRING等类型;
-
input-dims:维度,可以包含或者不包含批处理维度,对于不支持批处理的模型,需要完全按照实际模型的输入维度提供(包括batch),对于支持批处理的模型,第一维可以省略,写-1均可。
name: "model"
backend: "tensorrt"
max_batch_size: 8
input [{name: "input0"data_type: TYPE_FP32dims: [ 16 ]},{name: "input1"data_type: TYPE_FP32dims: [ 16 ]}
]
output [{name: "output0"data_type: TYPE_FP32dims: [ 16 ]}
]2.1.2 动态形状与动态批处理
当我们部署模型时,我们不仅希望模型可以组batch增大模型的并行性,也希望模型的并行度可以随着流量而变化,而像pytorch、Tensorrt等推理引擎都支持动态形状推理,因此triton服务器在接受推理请求时,也需要支持动态形状。
对于非batch维度,我们需要在配置文件对应输入输出dims的对应位置写为-1,这代表的该tensor的该维度接收动态形状。而对于batch维度,上小节已介绍了配置的方法,这里提一点,当多个请求在短时间内被发送到triton时,服务器应该是对每个请求执行一次推理?还是等待请求数到达最大batch再进行推理?或者是别的调度方法?
前两种方案很明显存在很严重的问题,会导致某些请求的等待时间过长,triton提供了动态batch的调度方法,只需要在配置文件中添加下述的配置即可。其中preferred_batch_size指尽可能让组batch的数量为以下值(不能大于max_batch_size),而max_queue_delay_microseconds指当无法到达最大batchsize或者倾向的batchsize时,最长的超时时间,例子中设置为1000微秒。
dynamic_batching {preferred_batch_size: [16, 32, 64, 128]max_queue_delay_microseconds: 1000
}2.1.3 多实例部署
除了多模型多版本部署以提高GPU利用率之外,triton还支持通过配置文件进行模型的多实例部署,当一个模型在GPU中存在多个实例时,triton将自动为每个(批)请求分配空闲的实例进行推理,以提高GPU的利用率,同时triton还支持在单机多卡的节点中,在不同的GPU中部署不同数量的实例。
# 为每个GPU上分配2个实例
instance_group [{count: 2kind: KIND_GPU}
]
# 为0号GPU分配1个实例,为1、2号GPU分配2个实例
instance_group [{count: 1kind: KIND_GPUgpus: [ 0 ]},{count: 2kind: KIND_GPUgpus: [ 1, 2 ]}
]2.1.4 客户端调用方式与监控
在triton的github仓库中,nvidia提供了与tritonserver相对应的client sdk以及示例代码,大家可以通过GRPC(8001端口)或者HTTP(8000端口)协议与tritonserver进行请求与获得响应。同时,tritonserver通过8002端口以http协议提供监控功能,可以对外提供GPU和CPU的相关指标,便于服务端开发者建设稳定性系统。
在示例中,主要根据其应用场景分为多种客户端,有针对单次推理的普通客户端,也有针对流式的客户端,也有针对不同数据类型的客户端。
https://github.com/triton-inference-server/client
然而我们在实际实践过程中,特别是对于自定义backend,经常需要进行压测与疲劳测试以确定用户代码没有内存问题和线程安全等问题,对于客户端的敏捷开发非常不便,这一点笔者目前正在开发简单易用的基于GRPC的多功能测试客户端,支持QPS和并发两种模式,同时具有性能测试和疲劳稳定性测试以及回归测试三种测试方式,后续功能完善稳定之后,会逐步对开放对外使用,敬请期待。
2.1.5 ensemble编排
对于绝大部分AI应用场景,我们通常需要部署多个模型以满足业务功能的需要,假如我们分多次发送请求,必定会存在大量的通信开销,如果能够一次请求就按照顺序完成所有的模型推理,那岂不是很好?
在triton里面提供了ensemble功能,可以对多个模型进行编排,通过一个虚拟的编排模型,将多个模型进行串联,并完成数据的传递。
以下是来自triton github上面的一个例子,定义ensemble的模型名字是“ensemble_model”,即客户端在发送请求时,应该请求“ensemble_model”,而input和output则应该与模型的输入输出区分开来,因为triton认为ensemble也是一个模型,同时在部署的时候,在模型仓库中,该配置脚本也应该放在一个叫“ensemble_model”的文件夹下,并且也存在一个名为“1”的空白文件夹,以代表该模型存在版本-1。
在“ensemble_scheduling”中,每个step代表一次模型推理,分别填入模型名字与版本(-1代表最新版本),在map中key中指代模型实际输入输出的名字,而value指代在ensemble中的形参。注意一点,如果模型有的输出不会被其他模型所使用,那么需要将这一对map删除,即ensemble的配置中,并不需要强制指定所有输入输出的映射关系,只需要完成对应的数据传输流即可。
name: "ensemble_model"
platform: "ensemble"
max_batch_size: 1
input [{name: "IMAGE"data_type: TYPE_STRINGdims: [ 1 ]}
]
output [{name: "CLASSIFICATION"data_type: TYPE_FP32dims: [ 1000 ]},{name: "SEGMENTATION"data_type: TYPE_FP32dims: [ 3, 224, 224 ]}
]
ensemble_scheduling {step [{model_name: "image_preprocess_model"model_version: -1input_map {key: "RAW_IMAGE"value: "IMAGE"}output_map {key: "PREPROCESSED_OUTPUT"value: "preprocessed_image"}},{model_name: "classification_model"model_version: -1input_map {key: "FORMATTED_IMAGE"value: "preprocessed_image"}output_map {key: "CLASSIFICATION_OUTPUT"value: "CLASSIFICATION"}},{model_name: "segmentation_model"model_version: -1input_map {key: "FORMATTED_IMAGE"value: "preprocessed_image"}output_map {key: "SEGMENTATION_OUTPUT"value: "SEGMENTATION"}}]
}2.1.6 自定义backend
ensemble可以解决大部分简单的模型串行关系,但是对于有复杂前后处理或者复杂链接关系的业务模型,使用ensemble则可能不能完全满足需要,这个时候需要我们用户自己写backend,类似于trt或者pytorch,triton将我们写的代码也认为是一个backend,可以将业务代码直接写进去,也可以作为一种通用的backend进行多模型复用。
在triton的github官网上,nvidia提供了用户自定义backend的示例,用户编写代码好,经过编译,生成一个libtriton_[name].so,将该so文件可以放在与模型一样的文件夹结构,也可以放在与trt相同的backend目录中。custom backend为用户提供了极高的自由度,用户只需要实现相应的triton接口,即可完全自由地进行业务逻辑的实现。
需要实现的接口有以下:
//初始化backend
TRITONSERVER_Error* TRITONBACKEND_Initialize(TRITONBACKEND_Backend* backend);
//销毁backend
TRITONSERVER_Error* TRITONBACKEND_Finalize(TRITONBACKEND_Backend* backend);
//初始化模型
TRITONSERVER_Error* TRITONBACKEND_ModelInitialize(TRITONBACKEND_Model* model);
//销毁模型
TRITONSERVER_Error* TRITONBACKEND_ModelFinalize(TRITONBACKEND_Model* model);
//初始化实例
TRITONSERVER_Error* TRITONBACKEND_ModelInstanceInitialize(TRITONBACKEND_ModelInstance* instance);
//销毁实例
TRITONSERVER_Error* TRITONBACKEND_ModelInstanceFinalize(TRITONBACKEND_ModelInstance* instance);
//单个示例接收请求
TRITONSERVER_Error* TRITONBACKEND_ModelInstanceExecute(TRITONBACKEND_ModelInstance* instance, TRITONBACKEND_Request** requests,const uint32_t request_count);https://github.com/triton-inference-server/backend
2.2 Triton部署TTS模型实践
2.2.1 TTS业务概述
文本转语音(text to speech,TTS)是AI语音领域非常重要的应用方向。
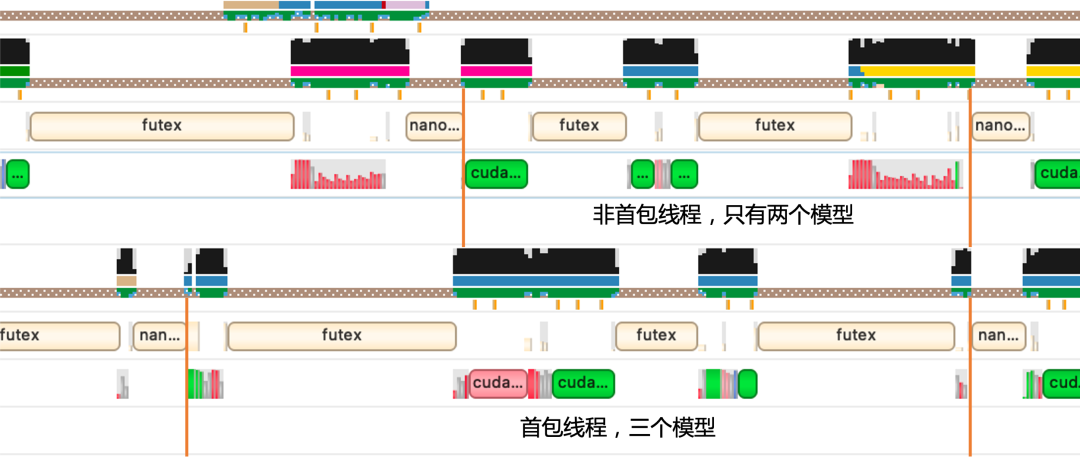
云端tts业务整体有encoder、decoder和vocoder三个模型,他们的串联顺序如下图,由于文本转语音是一个流式任务,一次请求需要多次返回结果,所以一次请求需要重复调用多次模型推理,其中encoder模型仅在收到推理请求时执行一次,而decoder和vocoder需要根据划分块的数量推理相应的次数,并且在每次模型推理后还包括一些后处理的任务。

业务有以下几个特点:
-
首先是对首包延时敏感,tts业务的结果由多个块组成,而客户端只要收到首包即可以播放给用户,因此相比于非首包的计算时间,首包的计算时间更加关键,直接关系到用户的体验;
-
第二个是非首包时间不敏感,在正常情况下,处理一包的时间小于一包的播放时间;
-
第三个是一次请求会计算得到十数甚至数十包;
-
第四个是encoder模型只参与第一包的计算,而decoder和vocoder模型参与了所有包的计算,使得在正常情况下,decoder和vocoder的组batch数会远远大于encoder;
-
第五个是性能评价指标有首包延时,可承载并发量以及吞吐量;
-
第六个是云端业务共同的特点,由于云端业务具有并发特性,所有在一些预处理和后处理的过程中,每个请求需要等待所有请求均完成之后才能共同进入下一步,这会导致单请求视角的等待时间较长。
我们的tts部署在nvidia语音解决方案团队的帮助下,在他们提供的tts部署方案基础上,成功在triton server上完成部署,通过自定义的backend,完成了整套的流程,但是初期的backend延迟性能和并发性能都较差,GPU利用率较低,笔者对这部分进行了一部分优化,在此记录所优化的过程。下文的实验与优化,都在A10卡上进行。
2.2.2 性能瓶颈分析
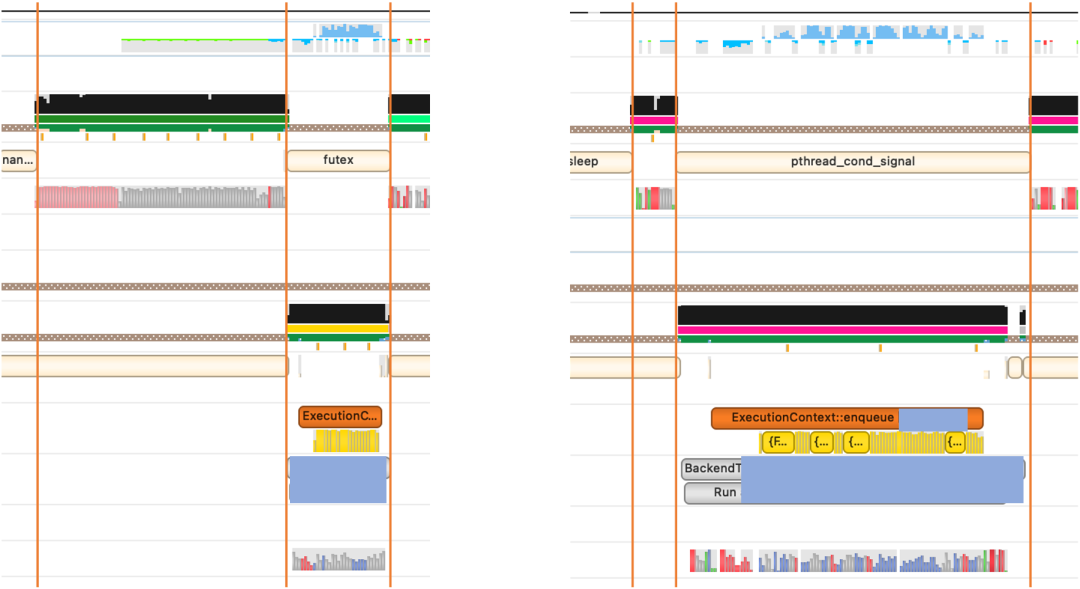
先用nsys对计算时的计算资源进行分析,得到如下图,并根据代码逻辑,分析得到有如下的性能瓶颈:

1)首先从整体上分析,一次包含encoder的模型推理耗时在整个流程中仅占42%(以下实验除标注外,都在100并发下进行),除计算耗时外,大部分时间消耗在资源的申请释放、内存拷贝、后处理三个阶段中。
2)一次循环的开头,线程接收到新的请求,为其新开辟所需要的内存与显存,待推理结束后又将所有资源释放掉,这部分耗时严重,并且随着请求量的增加,其耗时也随之增加,而其他每个请求均需要等待所有请求的资源申请之后才能进行下一步,增加等待时间。(重复申请释放资源)
3)在组、拆Batch时,对每个请求的每个tensor都单独执行cudamemcpy,使得启动cudamemcpy的次数过多,导致时间累积过长,并且性能分析图里出现许多的断块,说明没有充分利用显存的带宽,上次的拷贝已经结束,下次的拷贝仍未启动,像encoder和decoder的输入均有5个tensor,这样无疑成倍增加memcpy的时间开销。(多次、离散进行cudamemcpy)
4)存在不必要的深拷贝,在encoder的后处理和decoder->vocoder的数据过程中,存在了不必要的深拷贝,并且均为离散的cudamemcpy操作,这部分会增加时间开销。(过多深拷贝)
5)首包与非首包存在相互制约,由于首包需要进行encoder的推理,而非首包不需要,因此会导致非首包数据等待一次encoder过程;而由于非首包的请求量远大于首包的请求量,导致首包数据需要拼很大的batch,会增加前后处理、组拆batch以及推理耗时。(任务线程组织不合理)
6)后处理过程耗时较长,在tts业务中,encoder和vocoder的输出数据具有后处理过程,而后处理将数据拷贝回cpu进行处理,再拷贝回gpu,无疑增加时间消耗。(后处理设计不合理)
2.2.3 优化工作
2.2.3.1 重复申请释放资源-管理资源池
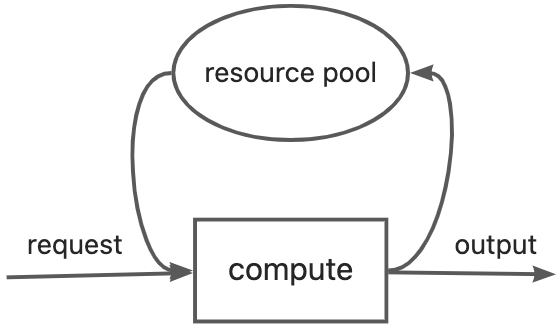
在程序启动时,一次性创建一定数量的InferenceItem实例存放于资源池中,每次收到推理实例时,从资源池中取出,进行状态量与表征状态的内存初始化,节省了很多时间开销。当遇到资源池中无实例时,采用的策略是已经获得实例的请求开始首包推理,而其他请求则等待下次首包推理获取实例。目前资源池的大小设定为模型max_batch的两倍,主要是依据后续的线程组织结构设定。
2.2.3.2 多次、离散进行cudamemcpy-对D2D使用cudakernel进行并行拷贝
在gpu中的数据传递可以使用cudakernel进行一次性操作,以实现batch之间memcpy的并行,减小了cudamemcpy启动的次数。
第一次优化:在cpu中记录每组拷贝的源地址(src_ptr),目标地址(dst_ptr)以及拷贝长度(src_len),在程序启动时,管理一片用于存储这三组数据的显存,然后三次将拷贝信息拷贝到显存中,可以启动相应组数的cudakernel,每个kernel进行memcpy操作。这样将原先的多次启动cudamemcpy操作缩短为三次cudamemcpy+一次cudakernel的时间开销。
第二次优化:同样记录上述三种信息,但同时记录所有拷贝长度中的最大值,在启动kernel时,启动 组数*最大值 数量的kernel,根据索引判断是否在有效的数据范围内,直接进行赋值操作,以进一步压缩拷贝时间开销。
2.2.3.3 多次、离散进行cudamemcpy-对H2D、D2H使用连续内存进行拷贝
由于D2H和H2D的数据操作不能在cudakernel中并行执行,因此想要降低启动cudamemcpy的开销,只能将数据存储于一片内存中,然后一次性进行拷贝操作,然后在cpu或者gpu中进行拆分等操作。
由于encoder的数据拷贝量很少,目前的时间开销不多,因此没有针对H2D进行优化;针对vocoder的输出数据,则是将其输出先直接拷贝回cpu中,然后直接将cpu中的内存首地址给各个实例存储以进行发送,由于每个线程的vocoder推理和发送结果是顺序进行的,因此不会存在后来数据覆盖未处理数据的风险。
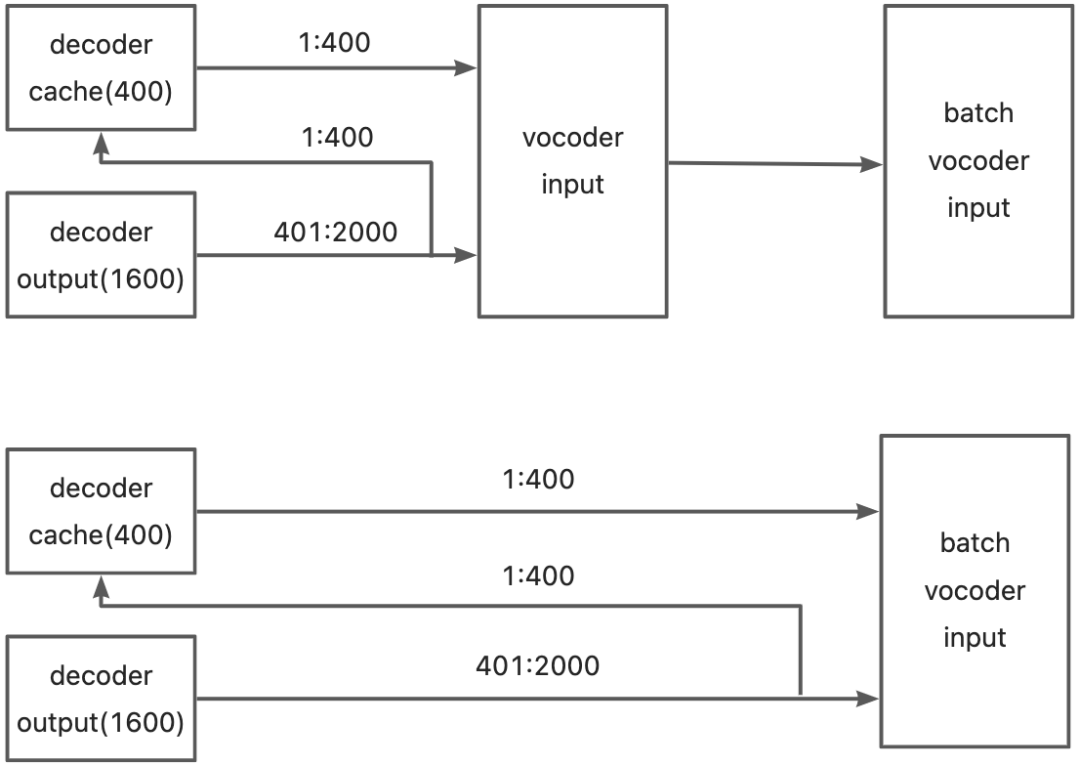
2.2.3.4 过多深拷贝-改用地址拷贝、减少中间环节
原先由于decoder->vocoder的数据传输较为复杂,出现了需要多次拷贝decoderOutput不同片断的情况,所以出现了多次内存深拷贝,但增加了很多的时间开销。通过梳理数据流,将深拷贝更改为地址拷贝,有效降低了时间开销,具体数据流见下图。由于业务逻辑的多样性和复杂性,这部分在后续其他业务的开发中,需要提前进行梳理,以避免后续二次优化。
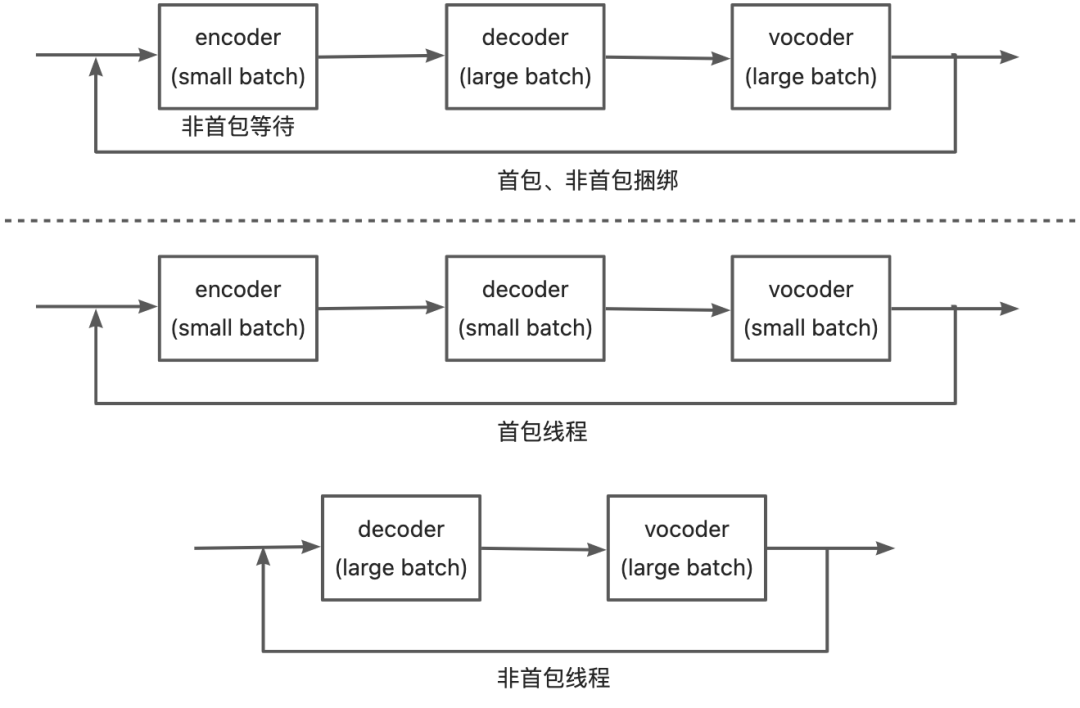
2.2.3.5 任务线程组织不合理-避免将不需要的任务放入线程
将原先的一个线程拆分为两个线程,一个线程用于处理首包请求,包含三个模型encoder、decoder与vocoder,此时的decoder和vocoder的请求batch数相比于原来相同并发下能保持在一个相对较小的水平,可以降低这两个模型的耗时;另外一个线程用于处理非首包请求,只包含两个模型decoder和vocoder,此时非首包请求不需要在encoder模型处进行等待,很有效地增加了系统的吞吐量。
2.2.3.6 后处理设计不合理-将后处理放入gpu以获得并行加速
原先的后处理过程中,整体思路都是先拷回cpu,进行处理之后再进行下一步操作,而组batch的目的是利用gpu的并行运算加快计算时间。
针对encoder的后处理,原先的方案是将output与duration都拷贝回cpu,由duration计算得到实际的帧数之后,将output进行拷贝与扩展,再拷贝回gpu。优化后的方案是只将duration拷贝回cpu,计算得到帧数后,在gpu中进行output的拷贝,而显存空间的扩展也不再进行,改为在程序启动时,预先预留好最长可能的数据长度,避免重复的malloc与free,在目前显存空间充足的前提下,是较优的方案。
针对vocoder的后处理,需要进行四步,lfilter、crossfade、memcpy以及quantize,其中lfilter不能在一个请求的数据之间并行进行,因此只能在batch之间并行运算,而另外三个任务都是可以在请求内的数据之间并行运行,并且这三个任务是相邻,可以进行任务的融合。

2.2.4 优化总体效果
2.2.4.1 管理资源池
在100并发下首包延时降低约15%,吞吐量增加21.7%。
2.2.4.2 对D2D使用cudakernel进行并行拷贝+改用地址拷贝、减少中间环节
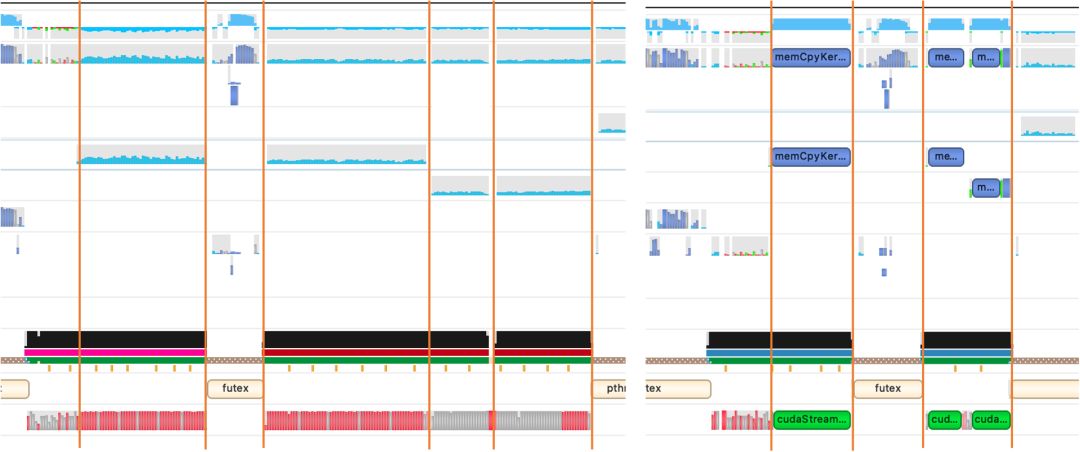
在100并发下首包延时降低约24%,吞吐量增加10%
第二期优化:将memcpy展平
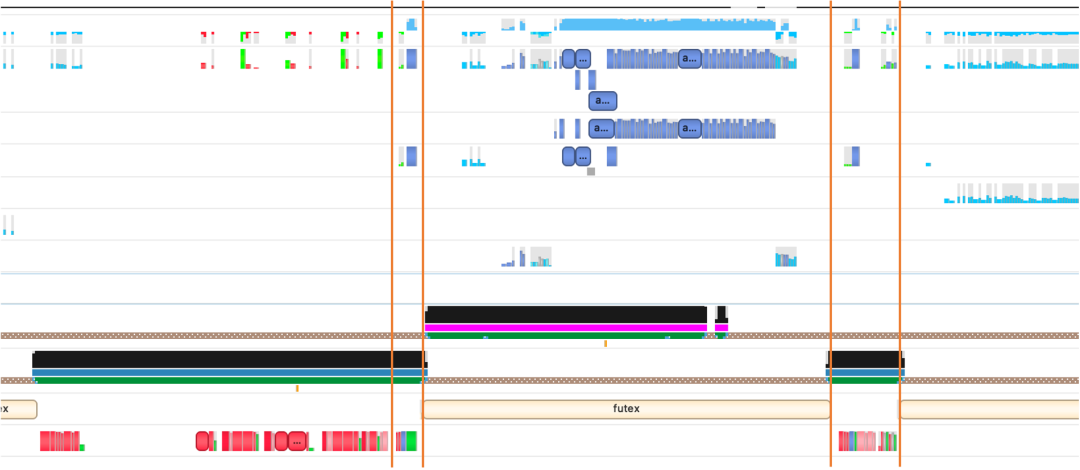
2.2.4.3 对H2D、D2H使用连续内存进行拷贝+优化vocoder后处理
在100并发下首包延时降低约9%左右。
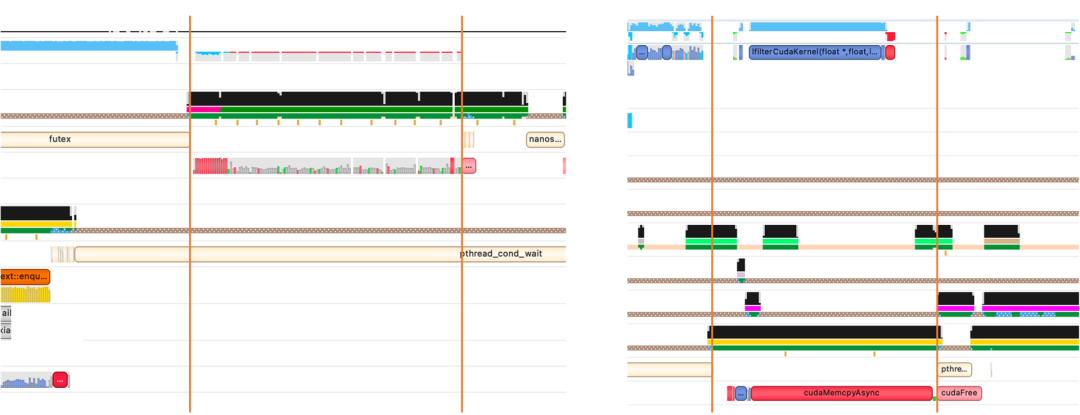
2.2.4.4 避免将不需要的任务放入线程
在100并发下首包延时降低约13%,吞吐量增加12.7%。
2.2.4.5 优化encoder后处理
由于encoder的batch数较小,这一部分与batch正相关,所以加速效果较小。
2.2.4.6 优化总体效果
经过优化后,TTS整体的性能得到了极大的提升,以天猫精灵高峰期的常规文本作为测试集,在128并发下A10卡进行测试,首包延时平均下降约60%,非首包延时平均下降约40%,文本级单卡吞吐量上升50%,相较于原先的性能得到了大幅提升。
我们与NVIDIA解决方案架构团队合作的前期在T4GPU上的相关成果也在NVIDIA的官网进行介绍。
https://blogs.nvidia.cn/2022/07/19/alibaba-tmall-genie-accelerated-deep-learning-models-text-to-speech-with-nvidia-tensorrt-triton/ 。
三、写在最后
在半年以来一直围绕云端模型的部署和计算开展学习和工作,利用NVIDIA的TensorRT、Triton和Nsight等工具进行天猫精灵在线TTS推理服务相关工作,并以此业务为基石,拓展云端GPU相关技术能力。本文主要对我半年以来主要从事的triton部署以及学习的cuda相关知识进行了一些总结,可能由于学习的还不够全面,文中仅总结了一些常用的功能和知识点,并且可能会有一些疏漏,如果大家发现有错误的地方,望不吝赐教。
后续我们还将对于云端语音相关技术的模型部署,基于cuda的相关高性能计算库以及大模型的推理部署等相关技术进行分。如果阿里的同学们也有对相关技术感兴趣的,欢迎随时和我们联系交流,一起进步推动AI工程化的发展。在此感谢智能互联-工程技术-智能引擎团队所有师兄同学的帮助,感谢与我合作的算法同学的倾力配合,同时感谢NVIDIA语音解决方案团队对我们在相关工具使用上的支持与帮助。