问题定义
召回操作通常作为搜索/推荐/广告的第一个阶段,主要目的是从巨大的候选集中选出相对合适的条目,交由后链路的排序等流程进行进一步的择优。因此,召回问题本质上就是一个大规模的最值的搜索问题:
对于评分 和候选集 ,给定输入 ,寻找固定大小的 的子集 ,使得 { , } 在 {, }尽可能靠前。
这个问题本身非常简单直接,而其核心在于其巨大的规模。通常,在阿里妈妈广告场景中,召回的候选集规模能达到千万甚至是上亿的数量级。受在线系统较为严格的延时约束,在这样规模的候选集上通过暴力搜索找出最优解显然是不现实的。
因此,我们会对候选集Z构建索引,从而对搜索过程进行剪枝。尽管某些索引会导致检索出的结果并非最优解,但好在召回问题本身对精确度的trade off容忍度较大。首先,搜索/推荐/广告本身就是非确定性的,其最优解并不能严格定义;其次,后链路还会进行进一步择优,召回结果只要做到尽可能包含后链路的最优解,也就是保证召回率即可。
本文将介绍阿里妈妈广告召回索引的演进过程,以及在这一过程中的工程解决方案。
1.分区索引(量化索引)
这种构建索引的方式是最直接的。简单来说,就是在每个维度上进行量化,从而把整个向量空间划分成若干个不同的分区。这样可以将向量划归到不同的分区,在需要进行剪枝时,可以先根据分区进行筛选:首先粗略地挑选出若干分区,再将归属于这几个分区的向量挑选出来进行详细的计算与排序。由此可以避免计算候选集中的全部向量。
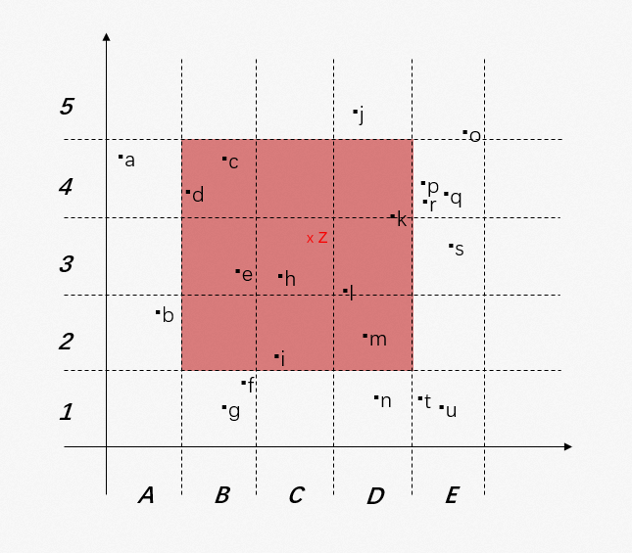
如下图所示:对于寻找最近欧几里得距离向量的问题,在一个二维的向量空间上,我们对每个维度量进行5等分的量化,从而将整个空间划分成25个分区。对于输入向量 z,我们可以首先筛选出分区{B2, B3, B4, C2, C3, C4, D2, D3, D4},然后对这几个分区中的{c, d, e, h, i, k, l, m}这8个向量进行距离计算和排序,相比于全局的比较搜索的21个向量,计算量缩小了2.6倍。
这种量化索引被广泛运用于传统的向量检索引擎,例如faiss/proxima。这种索引对于平均分布的低维向量上针对距离的检索效果很好,但同时存在几个问题。首先是对于非平均分布的向量集,可能需要非均匀的量化策略,一方面增加了复杂性,一方面也未必有很好的效果;其次,对于比距离函数更复杂的评分函数,很难找到分区于函数结果之间的相关关系,很难做剪枝算法;最后,对于高维的向量,还存在高维稀疏的问题,导致分区数量远远大于实际向量的个数。举个例子,我们NANN模型中广告向量位128维,即使我们每个维度只进行2分,就有2^128个分区,远大于数百万的向量个数,导致其实很多分区里是没有向量的。为了解决这个问题需要对向量空间进行降秩,而降秩算法本身又引入了新的更复杂的问题。
2.树状索引
为了规避量化索引的种种弊端,我们在TDM模型中采取用了树状索引。量化方法最主要的思想是要分类(分治),而它的弊端主要是来自于天然向量空间的限制。为了突破这些限制,我们可以更加“人工”的进行分类,而不是单纯以空间相对位置作为分类基准。这里我们就可以引入各种聚类算法,对向量进行聚类,并且可以在此基础上对聚类进行聚类(类似linkage算法)。由此,我们会获得一个树结构的索引。这棵树上,叶子节点代表向量,上层节点表示聚类(或聚类的聚类etc)。而检索的过程,就是在这颗索引树上从上到下进行beam search。这种类型的索引,我们最早是在TDM 模型中进行了运用,参考论文《Learning Tree-based Deep Model for Recommender Systems》。如下图所示,图中节点5~12表示向量本身,节点1~4则表示聚类。
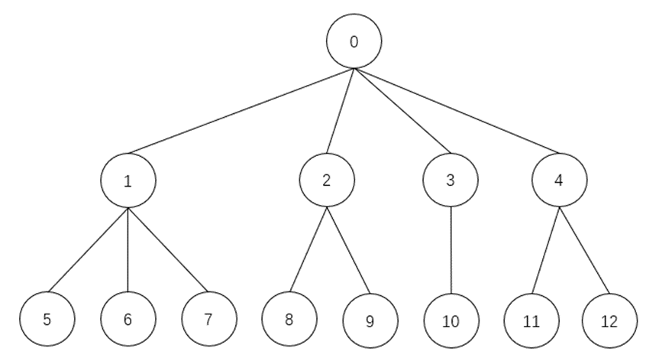
在工程实践中,最早的TDM采用的“二叉树”的索引结构,深度大约6~7层(最上层数千个节点),且这个索引结构维护在引擎端,每一次inference都将导致若干次的RPC,导致RT压力很大。后期改进中,我们首先将二叉树变成了多叉树,减少了树的深度。其次将索引结构用tf的splits结构表达,放到了模型中,在模型中计算,避免RPC开销,为模型增加的数倍的RT空间。这部分的详细叙述可以参考我们之前的文章 《广告深度学习计算:召回算法和工程协同优化的若干经验》。
这种树结构的索引有一个弊端:它的不同分类之间是互斥的,也就是说它能表达的向量之间关系比较单一。对于电商,每个商品可能会有不同的属性,每种属性都可能和别的商品产生某种关联关系。对于多种关联关系的表达,树结构索引就显得有些力不从心了。
3.图索引(HNSW)
为了解决树结构索引聚类之间互斥带来的问题,我们引入了图结构的索引HNSW。与树结构索引用父节点表示聚类不同,HNSW中每个节点都表示向量,而用编来表示向量间的关联。与树结构索引类似,在HNSW索引上的检索也是一个beam search的过程,不同的树结构索引通常是从第一层开始检索,而HNSW上会随机选取节点作为检索的起点。此类索引我们运用在了NANN模型中,参考论文《Approximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation》。
在TF中表达图的结构比树的结构更为复杂,这里我们采用了ragged tensor数据结构。ragged tensor 是TF原生支持的,可以表示一个行之间不等长的矩阵,我们用它来表达HNSW的邻接表,在上面执行gather+unique操作就可以表示beam search中expand的操作。例子如下:
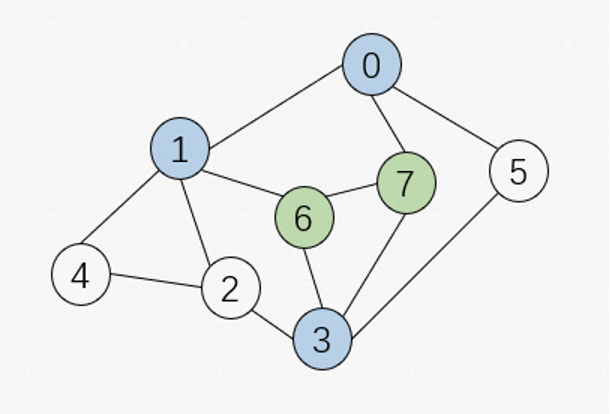
对于这张图的结构,它的邻接表:
0: 1,5,7 1: 0,2,4,6 2: 1,3,4 3: 2,5,6,7 4: 1,2 5: 0,3 6: 1,3,7 7: 0,3,6 |
相比于树,图结构的索引由于并没有互斥关系,导致在beam search的过程中我们可能会重复访问某些节点,造成了计算资源和召回配额的浪费。因此我们在beam search检索过程中需要排除掉已访问节点,也就是维护一个访问节点的集合,通过set difference操作来进行去重/剪枝。对于上述的例子,这个操作意味着 {0,1,3,6,7}-{6,7} = {0,1,3}。
由于naive的set difference计算效率不高,我们采用了在全集上建立一个bitmap的做法:每个节点用一个bit标志是否被访问过,并在整个beam search的过程中都维护这一个bitmap,将集合操作转变成简单的位操作。同时,为了避免op内input/output时的memcpy,我们用tf里的ref tensor(即variable)来存储这个bitmap,同时通过temporary_variable中step_container的机制来规避多并发时线程不安全的问题。

4.多类目+多层次的HNSW图索引
随着hnsw图结构索引推广到更多的业务,我们也遇到了新的问题。在搜索广告场景中,业务上需要对商品类目进行强感知,这些类目之间并非互斥而还存在层级关系,而且大小分布极不均衡。算法在建模的过程中需要对每个类目单独构建hnsw索引,每次请求需要在若干被选中的类目上都进行beam search的检索。这对我们的系统提出的挑战是:如果我们在这些类目上依次进行独立的beam search,整个检索过程将被重复数次,延时上必然满足不了要求。因此,我们需要某种形式的并行化,进行缩短整个检索的流程。
我们采用了indirect(间接)的思想来处理这个问题。我们将多个类目上的hnsw图都统合起来,包括多层级的类目,都视作同一张hnsw大图,在这张大图上进行整体的计算。不同于上一节中的hnsw图,这张大图并不是完全联通的,而是由几个互相隔离的子图组成。而且在这张大图上,节点和广告并不是一对一的关系,而是多对一,即若干不同的节点会对应同一个广告,因此我们还会维护节点到广告的映射关系。对于每一次请求,我们会将beam search的起始点定在那些被选中类目对应的子图上,子图间的隔离将保证一个类目上的检索不会串到别的类目上。同时在每一轮topk的过程中我们会维护访问节点与不同子图计算结果的隔离关系,从而确保每个类目上的配额足够,保证类目的完整性。而这种隔离关系正好也可用通过ragged tensor来进行表达。
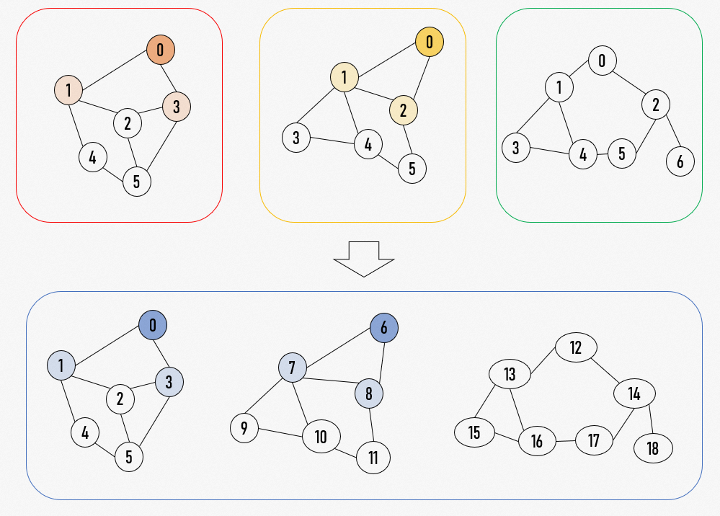
如图,我们通过对节点重新编号,将3个互相独立的图结构索引整合进同一张大图,三个子图仍然互不连通。对于其中独立索引上的两个独立的beam search过程:[0]->[1,3] 和 [0]->[1,2] ,而在新的大图上,就被整合进了同一个beam search流程:[[0],[6]]->[[1,3],[7,8]]。图中的3和7尽管是不同节点,但仍然可能表示同一个商品/广告/创意之类的对象,从而映射到同一个向量上。
5.结合图化的创新
我们在图化模型服务引擎中提供了BlazeOp的抽象,将tf session run的整个过程封装进了BlazeOp中。由此,我们可以将模型运算图的一部分子图打包进BlazeOp所持有的独立session中。结合这一特性,我们对树结构索引和图结构索引这类beam search的模型进行了升级改造,将打分函数部分打包进BlazeOp,从而实现了模型计算与检索过程分离。
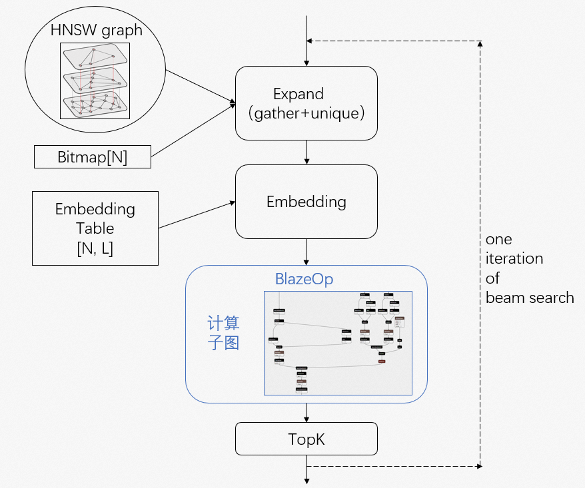
这样做带来了以下优势:
形成固定范式,方便算法迭代。算法在更新打分模型的时候不需要去考虑索引结构,可以直接复用索引部分的代码,反之亦然。例如,可以直接通过替换BlazeOp中子图的方式将A模型中的打分函数运用到B模型中去。
更易于进行打分模型的交付和优化。首先,打分部分模型可以直接复用离线训练的图结构进行原生交付;其次,由于打分模型走独立的session,避免beam search带来的dynamic shape的问题,采用传统的padding方案即可开启xla,不依赖auto_padding。最后,由于摘除了巨大embedding table const和复杂的beam search逻辑,打分的子图相对全图简化了很多,因此能很方便的开启const-folding之类的图优化。
可以绕开含光npu系统对于图中只能存在一个engine op的限制:由于对engine op进行编译时采用了静态的内存地址分配策略,同一个图中如果包含多个engine op会导致内存地址冲突。而将engine op置于blaze op的session中,则可以保证每个session中只存在唯一的engine op,避免了内存地址冲突。通过beam search中对这个session的多次调用,实现了在一次图执行过程中执行多次engine op的目的。
此外,图化模型服务引擎也便于我们为索引升级新的特性。例如,通过对索引部分的embedding table定制动态的数据结构以及实现相对应的功能op,配合swift流等中间件,我们可以实现embedding table以及hnsw图结构的实时化。这部分内容,我们将在后续的文章中详细介绍。欢迎感兴趣的同学关注及留言讨论。
引用
[1] Zhu H, Li X, Zhang P, et al. Learning tree-based deep model for recommender systems[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1079-1088.
[2] Chen R, Liu B, Zhu H, et al. Approximate nearest neighbor search under neural similarity metric for large-scale recommendation[C]//Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022: 3013-3022.
END

也许你还想看
丨广告深度学习计算:异构硬件加速实践
丨广告深度学习计算:召回算法和工程协同优化的若干经验
丨广告深度学习计算:阿里妈妈智能创意服务优化
丨新时期的阿里妈妈广告引擎
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓

![自定义input[type=file]上传按钮样式的四种方案,你知道几种?](https://img-blog.csdnimg.cn/img_convert/d2e9ec2ddd6953b966b3c5a01d1c03b2.png)