目录
一、信息熵
① 基本概念
② 计算公式
二、决策树中的信息熵
三、计算数据集样本分类的香农熵的源代码
说明:由于对这部分的知识有所遗忘,因此翻阅资料进行温习,写下本文。
需要注意的是,在本文中,所有中括号里边的内容,纯属个人理解,望读者包涵。
一、信息熵
① 基本概念
用来衡量一个随机变量出现的期望值【一个决策由很多随机向量共同决定,这些随机向量就是人决定每一件事中考虑的各个因素】。一个变量的信息熵越大,那么它蕴含的情况就越多【即这个因素还和其他许多因素关联,越早处理这个因素越好决断,否则最后处理,照样会让你头疼,因为你已经把其他因素决断完了,当考虑到这个因素时,又不得不重新考虑其他因素,这样大概率会导致你决断上的失误】,也就是需要更多的信息才能完全确定它。
香农这样认为:信息就是对不确定性得消除,一般而言,当某种信息出现更高概率时,表明它被传播得更广泛,或者说被引用的程度更高。
香农第一次提出信息熵的概念,所以信息熵和香农熵的表达一毛一样...
② 计算公式

对于多分类问题,延申一下得出公式了。在如下的决策树中,还可以用某类特征的数据的长度/总数据的长度代表发生的概率,即频率代表概率,p 这个概念具体场景下含义不同,可以灵活使用。
注意:本文提到的一个特征或一个分类也可以叫做一个随机变量(收入),这个随机变量可以有不同的取值(高低);一个随机变量通俗来说,就是决策一个事物需要考虑的一个因素。
二、决策树中的信息熵
在决策树中,信息熵不仅能用来度量类别的不确定性,还可以用来度量包含不同特征的数据样本与类别的不确定性。某个特征列向量的信息熵越大,则该向量的不确定性就越大【这里就很好理解了,特征列向量就是我们提到的影响人考虑的决策的各个因素】,也就是其混乱程度越大,越应该优先考虑从该特征向量入手进行划分【我的理解,因为构造决策树的关键是在于分裂属性,其中,分裂属性就是在某个节点(节点是所有数据在此处的分类依据,这个依据就是某一特征)处按照某一特征的不同划分(流到这里的数据集根据节点上的特征进行划分,如年龄特征,继而裂变为各个子集,如青年集、中年集和老年集,这些集合流向下一个特征节点,反复按这个逻辑进行)构造不同的分支,它的目标是让各个裂变子集尽可能的纯(属于同一类,比如今中午都决定买海鲜吃的人群,或都不买海鲜吃的人群),也就是属于同一类,因此,最先划分信息熵大的特征向量做出决策的效率更高】。
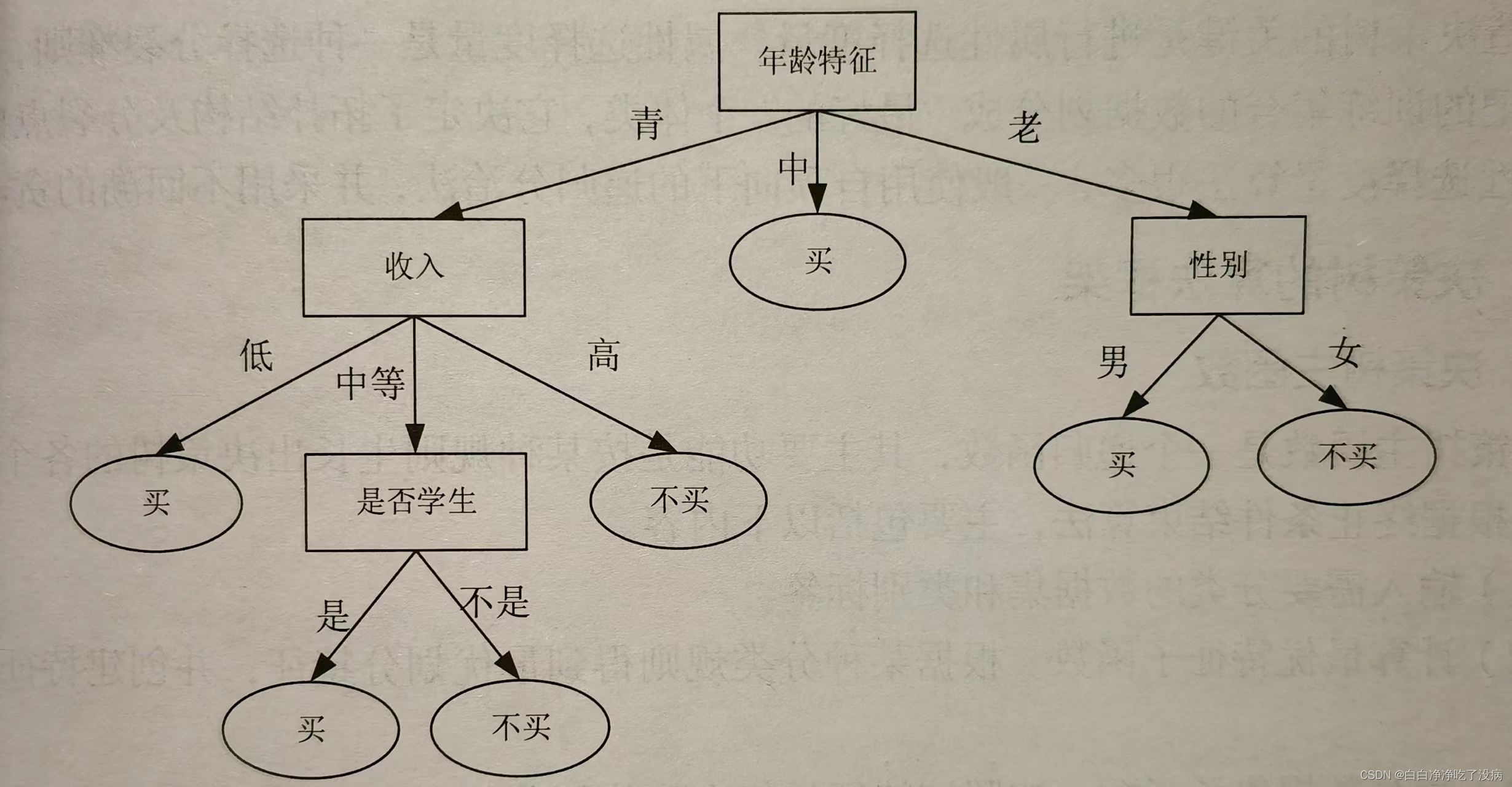
举个例子:如果预测某客户中午买不买海鲜吃,[年龄] 这个变量蕴含的情况就特别多(当然实际多不多,得靠计算信息熵计算),年龄分为青年、中年、老年,某个年龄段的人吃不吃或许要看收入的高低,每个收入的人群或许要看是否是学生,学生中又要看性别来决策,太多信息了。如果直接按 [收入] 这个变量划分,可能就会好一点。信息熵就是为我们选取决策树中最适合最先划分的特征。
三、计算数据集样本分类的香农熵的源代码
说明:
1、求解各个分类特征的信息熵,比如收入,它分为高和低,但收入高的不是全都吃海鲜的,收入低的不是全不吃海鲜的,在编码上更加复杂,我将在下篇文章中详述。
2、以下源码和注解为原创,如有不当或疑惑之处,可在评论区留言告知。
源代码:
from numpy import *# 本文源码只求样本分类的信息熵,仅为了说明信息熵的求解方法
# 对于如何求解各个类别特征的信息熵和如何构造决策树,将在后续文章详述def calculate_xns(dataset, n):"""计算给定数据集的香农熵(信息熵):param dataset:数据集:param n:数据集的第n个特征,默认取-1,即数据集中每个样本的标签:return:数据集的香农熵"""xns = 0.0 # 香农熵num = len(dataset) # 样本集的总数,用于计算分类标签出现的概率# 1、将数据集样本标签的特征值(分类值)放入列表all_labels = [c[n] for c in dataset] # c[-1]:即取数据集中的每条数据的标签:吃或不吃# print(all_labels) # 得到 [吃,吃,不吃,不吃,不吃,不吃] 的结果# 2、按标签的种类进行统计,吃这一类2个;不吃这一类4个every_label = {} # 以词典形式存储每个类别(键)及个数(值), 如{吃:2,不吃:4}for item in set(all_labels): # 对每个类别计数,并放入词典, 其中set(all_labels) = [吃,不吃]every_label[item] = all_labels.count(item)# 计算样本标签的香农熵,即数据集的香农熵for item2 in every_label:prob = every_label[item2] / num # 每个特征值出现的概率xns -= prob * log2(prob) # xns是全局变量,这样就可以计算关于决策的要考虑的某个随机变量(如收入特征)的香农熵return xns# 问题描述:如何求解数据集样本分类的信息熵?# 如下列是已知的统计数据(如果有大数据更好):
# 第一列特征是学生(Yes:是,No:不是)
# 第二列特征是性别(Yes:男,No:女)
# 第三列特征是收入(Yes:高,No:低)
# 第四列是每个样本最终的分类标签(吃海鲜或不吃海鲜)data = [['Yes', 'Yes', 'Yes', "吃"],['No', 'No', 'Yes', "吃"],['No', 'Yes', 'No', "不吃"],['No', 'No', 'No', "不吃"],['No', 'Yes', 'No', "不吃"],['No', 'No', 'No', "不吃"]]# 打印数据集样本分类的信息熵
print("数据集样本分类的信息熵%s" % (calculate_xns(data, -1))) # 0.9182958340544896运行结果: