本篇笔记是基于一个印度人写的《Pytorch深度学习》一书的第二章,主要用来描述一个麻雀虽小五脏俱全的完整的神经网络,包含了建模、训练等。原书的代码基于较老版本的Pytorch,有多处编译不过,笔者都做了调整,并在文末给出完整的代码和运行结果。
假设我们为一家互联网公司工作,该公司提供在线电影服务。
训练数据集包含了用户在平台上观看电影的平均时间的特征,而神经网络据此预测每个用户下周使用平台的时间。
一个典型的神经网络的构建过程分为以下5个阶段。
- 准备数据
get_data()准备输入输出的张量(数组)
这个神经网络中的get_data()函数创建了2个变量: x和y,尺寸分别为(17,1) 和 (17).
def get_data():train_X = np.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,7.042,10.791,5.313,7.997,5.654,9.27,3.1])train_Y = np.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,2.827,3.465,1.65,2.904,2.42,2.94,1.3])dtype = torch.FloatTensorx = Variable(torch.from_numpy(train_X).type(dtype),requires_grad=False).view(17,1)y = Variable(torch.from_numpy(train_Y).type(dtype),requires_grad=False)return x,y
这里的 x 是一个 17x1 的二维张量;y 是一个一维张量。
加、减和矩阵乘法这些基础运算可以构建复杂运算,如卷积神经网络(CNN)和递归神经网络(RNN)。这些以后再讲。
- 创建学习参数
get_weights()函数提供以随机值初始化的张量。神经网络通过自动优化这些参数来解决问题。
这个例子要构建一个线性的神经网络,即y=wx+b,因此只有2个学习参数:w和b,还有2个不变的参数:x和y .
torch.randn()函数为任意给定形状创建随机值。
def get_weights():w = Variable(torch.randn(1),requires_grad=True)b = Variable(torch.randn(1),requires_grad=True)return w,b
- 构建网络模型
simple_network()函数应用线性规则为输入数据生成输出。计算时,先用权重w乘以输入数据,再加上偏差b,即:y=wx+b
模型是用来学习如何将输入映射到输出的。
在传统编程中,我们手动实现逻辑,将输入映射到输出,是“已知输入和逻辑,求输出”。
在深度学习和机器学习中,是把输入和输出展示给模型,让模型完成对逻辑的学习,是“已知输入和输出,求逻辑”。
这里的网络模型是 y=wx+b, 其中w和b是学习参数,神经网络要学习w和b的值。
网络的实现如下:
def simple_network(x):y_pred = torch.matmul(x,w)+breturn y_pred
torch.nn提供了层(Layer)的高级抽象。
层负责后台的初始化和运算工作,而这些技术是很多常见的技术都需要用到的。
- 评估损失
loss_fn()函数提供了评估模型优劣的信息。
学习参数w和b以随机值开始,产生结果y_pred, 这样必定和真实值y相去甚远。
因此需要定义一个函数,来告知模型预测值和真实值的差距。
我们使用误差平方和(也称为方差,即 SSE)来定义损失函数。
def loss_fn(y,y_pred):loss = (y_pred-y).pow(2).sum()for param in [w,b]:if param.grad is not None: param.grad.data.zero_()loss.backward()if loss.data is None:print("loss.data is None")else:print("loss.data.size = %d" % len(loss.data))return loss.data
(笔者注:原文是return loss.data[0], 这应该是Pytorch早期版本支持的写法,但在笔者的1.12.1版本里,对于0维张量,直接返回loss.data即可。另外,对本函数中的 if 语句略作调整,使其更符合Python编程习惯。)
除了计算损失值,我们还进行了backward操作,计算出学习参数w和b的梯度。
我们会不止一次地使用loss函数,因此需要通过 grad.data.zero_()方法来清除前面计算出的梯度值。
在第一次调用backward函数的时候,梯度是空的; 因此当梯度不为None时,需将梯度值设为0.
- 优化器
optimize()函数用于调整初始随机权重,并帮助模型更准确地计算目标值。
前面使用随机值作为初始权重来预测目标,然后计算损失,再调用loss变量上的backward函数来计算梯度值。每次迭代在整个样例集合上重复整个过程。
损失值计算出来后,用计算出的梯度值进行优化,让损失值降低。
learning_rate = 1e-4def optimize(learning_rate):w.data -= learning_rate * w.grad.datab.data -= learning_rate * b.grad.data
learning_rate是一个超参数,可以让用户通过较小的梯度值的变化来调整变量的值。
梯度值指明了每个变量(w和b)需要调整的方向。
各种优化器,如Adam,RmsProp, SGD等,在 torch.optim包中已经实现好。
- 完整的程序
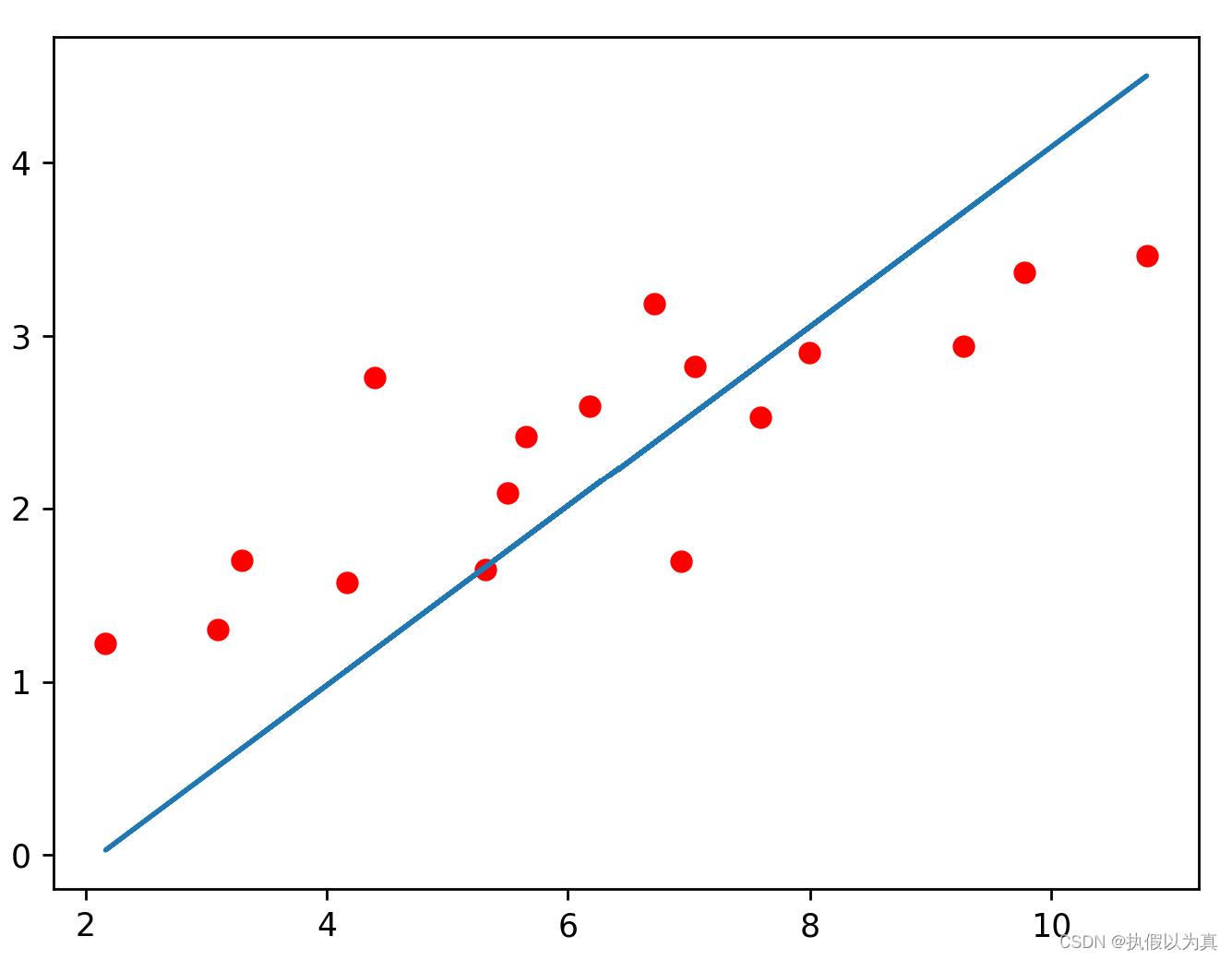
完整的程序如下。在这个程序中,我们最后会调用matplotlib来绘制一幅图。图中的红点的x轴坐标即为上周用户观影时间,y轴坐标为本周用户观影时间,蓝色的线条代表了预测线,即根据 x 坐标,预测 y 坐标。
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.autograd import Variable learning_rate = 1e-4# Training Data
def get_data():train_X = np.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,7.042,10.791,5.313,7.997,5.654,9.27,3.1])train_Y = np.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,2.827,3.465,1.65,2.904,2.42,2.94,1.3])dtype = torch.FloatTensorx = Variable(torch.from_numpy(train_X).type(dtype),requires_grad=False).view(17,1)y = Variable(torch.from_numpy(train_Y).type(dtype),requires_grad=False)return x,ydef get_weights():w = Variable(torch.randn(1),requires_grad=True)b = Variable(torch.randn(1),requires_grad=True)return w,bdef simple_network(x):y_pred = torch.matmul(x,w)+breturn y_preddef loss_fn(y,y_pred):loss = (y_pred-y).pow(2).sum()for param in [w,b]:if param.grad is not None: param.grad.data.zero_()loss.backward()return loss.datadef optimize(learning_rate):w.data -= learning_rate * w.grad.datab.data -= learning_rate * b.grad.datadef plot_variable(x,y,z='',**kwargs):l = []for a in [x,y]:if type(a) == torch.Tensor:l.append(a.data.numpy())# print(l)plt.plot(l[0],l[1],z,**kwargs)return pltx,y = get_data() # x - represents training data,y - represents target variables
w,b = get_weights() # w,b - Learnable parameters
for i in range(500):y_pred = simple_network(x) # function which computes wx + bloss = loss_fn(y,y_pred) # calculates sum of the squared differences of y and y_predif i % 50 == 0: print(loss)optimize(learning_rate) # Adjust w,b to minimize the lossplt1 = plot_variable(x,y,'ro')
plt2 = plot_variable(x,y_pred,label='Fitted line')
plt2.show()
(笔者注:对于plot_variable函数,笔者也略作了修改,否则有语法错误;究其原因,应该也是原来代码是基于较老版本的Pytorch所致。)
运行的截图如下:
(完)