目录
- 🌈前言
- 🚁1、哈希表的改造
- 🚂2、模拟实现的完整代码
- 🚃3、哈希表的应用
- 🚄3.1、位图的概念
- 🚅3.2、位图的实现
- 🚆3.3、位图完整代码
- 🚇4、位图的变形
- 🚈5、布隆过滤器
🌈前言
本篇文章学习C++STL< unordered_map和unordered_set >的模拟实现!!!
🚁1、哈希表的改造
- 模板参数列表的改造
// 哈希桶节点
template <typename T>
struct HashNode
{
public:HashNode(const T& data): _data(data), _next(nullptr){}
public:T _data;HashNode<T>* _next;
};// Unordered_set -> HashTable<K, Key, KeyOfT, hashF>
// Unordered_map -> HashTable<K, pair<K, V>, KeyOfT, hashF>template <typename K, typename T, typename KeyOfT, typename hashF>
class HashTable
{};
模板参数解析:
-
K:关键码(Key)的类型
-
T:不同的容器,T的类型就不相同。如果是unordered_map,T代表一个键值对,如果是unordered_set,T代表一个关键码(Key)
-
KeyOfT:因为V的类型不同,通过value取key的方式就不同,详细见unordered_map/set的实现
-
hashF: 哈希仿函数,哈希函数使用除留余数法,需要将Key转换为整形数字才能取模
- 增加迭代器操作
迭代器:
-
哈希桶的迭代器是单向的,因为它的底层是一个链表,只有指向下一个节点的指针
-
迭代器需要访问哈希桶中的私有成员,需要将迭代器设置成友元类
-
迭代器需要定义在哈希桶前面,但是迭代器需要访问哈希桶的私有成员,因为程序是从当前位置向上开始找哈希桶在不在,所有我们需要前置声明一下哈希桶类
namespace BUCKetHash
{// 前置声明,迭代器需要访问哈希桶类的私有成员template <typename K, typename T, typename KeyOfT, typename hashF>class HashTable;// 迭代器template <typename K, typename T, typename KeyOfT, typename hashF>class HTIterator{private:typedef HashNode<T> Node; // 哈希表节点typedef HashTable<K, T, KeyOfT, hashF> HT; // 哈希表typedef HTIterator<K, T, KeyOfT, hashF> Self; // 迭代器本身public:HTIterator(Node* _node, HT* _ht): node(_node), ht(_ht){}HTIterator(const HTIterator& hti): node(hti.node), ht(hti.ht){}Self& operator++(){// 如果传过来的节点指针不为空,则直接跳到下一个节点if (node->_next != nullptr){node = node->_next;}// 当前节点为空,找下一个桶else{KeyOfT kot;hashF hf;// 计算这个节点映射到桶的位置size_t hashi = hf(kot(node->_data));hashi %= ht->_tables.size();++hashi; // 当前桶已经遍历完,需要对hashi进行自增// 遍历判断其他哈希桶是否为空,不为空则返回这个桶的指针for (; hashi < ht->_tables.size(); ++hashi){if (ht->_tables[hashi] != nullptr){node = ht->_tables[hashi];break;}}// 映射位置等于有效数据时,说明已经越界(走到尾的情况)if (hashi == ht->_tables.size()){node = nullptr;}}return *this;}// 后置++,先使用后自增Self operator++(int){Self tmp(this);++(*this);return tmp;}T& operator*(){return node->_data;}T* operator->(){return &(node->_data);}bool operator!=(const HTIterator& hti) const{return node != hti.node;}bool operator==(const HTIterator& hti) const{return node == hti.node;}public:Node* node; // 哈希节点指针HT* ht; // 哈希表指针(this)};
}
哈希桶迭代器自增图解:

- 增加通过key获取value操作
-
哈希桶节点的模板类型T是不确定的,是unordered_map的时候是键对值(pair<K, V>),而unordered_set只是一个关键码(Key)
-
所以我们需要建立一个仿函数将它们进行区分(开头有讲到)
unordered_map:
namespace Myself
{template <typename K, typename V, typename hashF = BUCKetHash::HashDF<K>>class unordered_map{private:struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}private:BUCKetHash::HashTable<K, pair<K, V>, MapKeyOfT, hashF> ht;};
}
unordered_set:
namespace Myself
{template <typename K, typename hashF = BUCKetHash::HashDF<K>>class unordered_set{private:struct SetKeyOfT{const K& operator()(const K& key){return key;}private:BUCKetHash::HashTable<K, K, SetKeyOfT, hashF> ht;};
}
- 增加通过哈希函数转换无符号整形操作
对关键码进行转换:
- 因为哈希桶需要对该关键码映射对应的位置,所有需要把该关键码统一修改
namespace BUCKetHash
{// 仿函数:处理特殊的Key值问题 -- 后面需要对数据进行无符号整形转换template <typename K>struct HashDF{size_t operator()(const K& key){return static_cast<size_t>(key);}};template <>struct HashDF<string>{size_t operator()(const string& str){size_t HDS = 0;for (auto& e : str){HDS = HDS * 131 + static_cast<size_t>(e);}return HDS;}};
}
🚂2、模拟实现的完整代码
HashTable.h
#pragma once#include <iostream>
#include <vector>
using namespace std;// 哈希桶(指针数组):哈希表中存储指针,这个指针存储映射的值,映射相同位置时,创建新的节点直接链到这个指针中
namespace BUCKetHash
{// 仿函数:处理特殊的Key值问题 -- 后面需要对数据进行无符号整形转换template <typename K>struct HashDF{size_t operator()(const K& key){return static_cast<size_t>(key);}};template <>struct HashDF<string>{size_t operator()(const string& str){size_t HDS = 0;for (auto& e : str){HDS = HDS * 131 + static_cast<size_t>(e);}return HDS;}};// 哈希表节点template <typename T>struct HashNode{public:HashNode(const T& data): _data(data), _next(nullptr){}public:T _data;HashNode<T>* _next;};// 前置声明,迭代器需要访问哈希桶类的私有成员template <typename K, typename T, typename KeyOfT, typename hashF>class HashTable;// 迭代器template <typename K, typename T, typename KeyOfT, typename hashF>class HTIterator{private:typedef HashNode<T> Node; // 哈希表节点typedef HashTable<K, T, KeyOfT, hashF> HT; // 哈希表typedef HTIterator<K, T, KeyOfT, hashF> Self; // 迭代器本身public:HTIterator(Node* _node, HT* _ht): node(_node), ht(_ht){}HTIterator(const HTIterator& hti): node(hti.node), ht(hti.ht){}Self& operator++(){// 如果传过来的节点指针不为空,则直接跳到下一个节点if (node->_next != nullptr){node = node->_next;}// 当前节点为空,找下一个桶else{KeyOfT kot;hashF hf;// 计算这个节点映射到桶的位置size_t hashi = hf(kot(node->_data));hashi %= ht->_tables.size();++hashi; // 当前桶已经遍历完,需要对hashi进行自增for (; hashi < ht->_tables.size(); ++hashi){if (ht->_tables[hashi] != nullptr){node = ht->_tables[hashi];break;}}// 映射位置等于有效数据时,说明已经越界if (hashi == ht->_tables.size()){node = nullptr;}}return *this;}Self operator++(int){Self tmp(this);++(*this);return tmp;}T& operator*(){return node->_data;}T* operator->(){return &(node->_data);}bool operator!=(const HTIterator& hti) const{return node != hti.node;}bool operator==(const HTIterator& hti) const{return node == hti.node;}public:Node* node; // 哈希节点指针HT* ht; // 哈希表指针(this)};// Unordered_set -> HashTable<K, Key, KeyOfT, hashF>// Unordered_map -> HashTable<K, pair<K, V>, KeyOfT, hashF>template <typename K, typename T, typename KeyOfT, typename hashF>class HashTable{template <typename K, typename T, typename KeyOfT, typename hashF>friend class HTIterator; // 迭代器内部需要访问哈希表的私有成员private:typedef HashNode<T> Node;public:typedef HTIterator<K, T, KeyOfT, hashF> iterator;typedef HTIterator<const K, const T, KeyOfT, hashF> const_iterator;public:iterator begin(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];if (cur != nullptr){return iterator(cur, this);}}return end();}iterator end(){return iterator(nullptr, this);}const_iterator cbegin() const{for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];if (cur != nullptr){return const_iterator(cur, this);}}return cend();}const_iterator cend() const{return const_iterator(nullptr, this);}public:HashTable() = default;HashTable(const HashTable& ht){_tables.resize(ht._tables.size(), nullptr);for (size_t i = 0; i < ht._tables.size(); ++i){Node* cur = ht._tables[i];while (cur != nullptr){this->Insert(kot(cur->_data));cur = cur->_next;}}}HashTable& operator=(const HashTable ht){HashTable tmp(ht);this->_n = tmp._n;tmp._tables.swap(_tables);return *this;}~HashTable(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur != nullptr){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}// 返回值为pair是为了支持unordered_map的[]重载pair<iterator, bool> Insert(const T& data){Node* IfExist = Find(kot(data));if (IfExist != nullptr)return make_pair(iterator(IfExist, this), false); // 插入识别,数据冗余if (_tables.size() == 0 || _tables.size() == _n){size_t NewSize = _tables.size() == 0 ? 10 : _tables.size() * 2;// 把旧哈希桶的节点重新映射到新开辟的哈希桶HashTable newHT;newHT._tables.resize(NewSize, nullptr);for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur != nullptr){// 将旧哈希桶的值挪到新哈希桶中 -- 头插Node* next = cur->_next; // 保存下一个节点,挪动后防止找不到size_t hashi = HashDF(kot(cur->_data)) % NewSize; // 需要重新映射新扩容后的哈希桶,模新长度的哈希桶cur->_next = newHT._tables[hashi];newHT._tables[hashi] = cur;cur = next;}_tables[i] = nullptr;}newHT._tables.swap(_tables);}// 跟闭散列的方法一样需要继续模表大小size_t hashi = HashDF(kot(data));hashi %= _tables.size();// 构造需要插入的键对值,然后插入到映射的位置 -- 画图Node* newNode = new Node(data);newNode->_next = _tables[hashi];_tables[hashi] = newNode;++_n;// 插入成功,返回指向新节点的迭代器return make_pair(iterator(newNode, this), true); }bool erase(const K& key){size_t hashi = HashDF(key);hashi %= _tables.size();Node* cur = _tables[hashi];Node* prev = nullptr;while (cur != nullptr){if (kot(cur->_data) == key){// 删除位置为"头"if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}Node* Find(const K& key){if (_tables.size() == 0)return nullptr;// 查找跟闭散列差不多size_t hashi = HashDF(key);hashi %= _tables.size();// 对映射的位置进行循环遍历查找Node* cur = _tables[hashi];while (cur != nullptr){if (kot(cur->_data) == key)return cur;cur = cur->_next;}return nullptr;}private:vector<Node*> _tables;size_t _n = 0;hashF HashDF;KeyOfT kot;};
}
Unordered_map.h
#pragma once
#include "HashTable.h"namespace Myself
{template <typename K, typename V, typename hashF = BUCKetHash::HashDF<K>>class unordered_map{private:struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};typedef BUCKetHash::HashNode<pair<K, V>> Node;public:// 迭代器和常量迭代器typedef typename BUCKetHash::HashTable<K, pair<K, V>, MapKeyOfT, hashF>::iterator iterator;typedef typename BUCKetHash::HashTable<K, pair<K, V>, MapKeyOfT, hashF>::const_iterator const_iterator;public:iterator begin(){return ht.begin();}iterator end(){return ht.end();}const_iterator cbegin() const{return ht.cbegin();}const_iterator cend() const{return ht.cend();}pair<iterator, bool> insert(const pair<K, V>& kv){return ht.Insert(kv);}bool erase(const K& key){return ht.erase(key);}Node* find(const K& key){return ht.Find(key);}V& operator[](const K& key){pair<iterator, bool> ret = ht.Insert(make_pair(key, V()));return ret.first->second;}private:BUCKetHash::HashTable<K, pair<K, V>, MapKeyOfT, hashF> ht;};
}
Unordered_set
#pragma once
#include "HashTable.h"
namespace Myself
{template <typename K, typename hashF = BUCKetHash::HashDF<K>>class unordered_set{private:struct SetKeyOfT{const K& operator()(const K& key){return key;}};typedef BUCKetHash::HashNode<K> Node;public:typedef typename BUCKetHash::HashTable<K, K, SetKeyOfT, hashF>::iterator iterator;typedef typename BUCKetHash::HashTable<K, K, SetKeyOfT, hashF>::const_iterator const_iterator;public:// 迭代器iterator begin(){return ht.begin();}iterator end(){return ht.end();}const_iterator cbegin() const{return ht.cbegin();}const_iterator cend() const{return ht.cend();}// 其他接口pair<iterator, bool> insert(const K& key){return ht.Insert(key);}bool erase(const K& key){return ht.erase(key);}Node* find(const K& key){return ht.Find(key);}private:BUCKetHash::HashTable<K, K, SetKeyOfT, hashF> ht;};
}
🚃3、哈希表的应用
🚄3.1、位图的概念
概念:
-
所谓位图,就是用每一位(比特位)来存放某种状态
-
适用海量数据,数据无重复的场景。通常用来判断某个数据是否存在

🚅3.2、位图的实现
🌈前言:位图常用的接口只有三个,插入、删除和查找
位图的结构:
-
位图的结构是一个vector,底层是char/int类型,char可以标记8个状态(1字节),而int可以标识32个状态(4字节),模板类型是一个无符号整形
-
位图的基本操作就是存储不重复数据,即可以使用0/1来标识存不存在

- 构造函数:
-
每个char类型可以标识8个状态,如果是80个数据的话,只需要开辟10个空间足以
-
如果是81 - 87的话,那么只需要多开辟一个char类型空间就足够了,也不会浪费很大内存
template <size_t N>
class bitset
{
public:bitset(){// N是数据个数,我们使用比特位来映射,char类型一个字节占八个比特位bit.resize((N / 8) + 1, 0);}
}
- 插入:
-
使用哈希表的直接定址法,用一个比特位标识映射的位置在不在
-
标识状态要注意大小端问题,否则会出错
namespace myself
{// 注意大小端问题template <size_t N>class bitset{public:void set(size_t x){// x映射的位置在第几个char中size_t i = x / 8;// x标识的状态在char中的第几个比特位size_t j = x % 8;// 将映射位置的值(bit[i]) "按位或" 上一个向左移动j位的值bit[i] |= (1 << j);}private:vector<char> bit;};
}

- 删除:
- 删除就是把这个数据映射在char中的位置的状态更改尾0即可
namespace myself
{template <size_t N>class bitset{public:void reset(size_t x){size_t i = x / 8;size_t j = x % 8;bit[i] &= ~(1 << j);}private:vector<char> bit;};
}
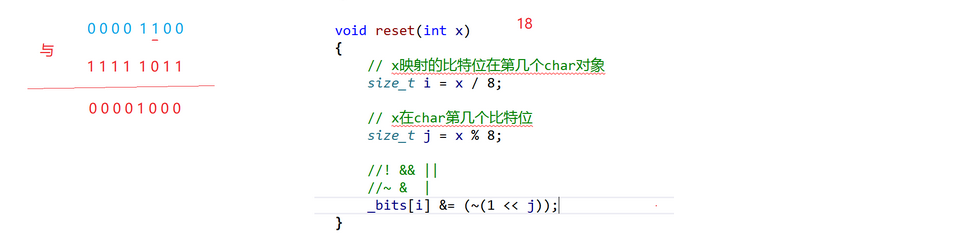
- 查找:
namespace myself
{template <size_t N>class bitset{public:bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return bit[i] & (1 << j);}private:vector<char> bit;};
}

🚆3.3、位图完整代码
// 位图:哈希表的变式,用于处理海量数据
namespace myself
{// 注意大小端问题template <size_t N>class bitset{public:bitset(){// N是数据个数,我们使用比特位来映射,char类型一个字节占八个比特位bit.resize((N / 8) + 1, 0);}void set(size_t x){size_t i = x / 8;size_t j = x % 8;// 将映射位置的值(bit[i]) "按位或" 上一个向左移动j位的值bit[i] |= (1 << j);}void reset(size_t x){size_t i = x / 8;size_t j = x % 8;bit[i] &= ~(1 << j);}bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return bit[i] & (1 << j);}private:vector<char> bit;};
}
🚇4、位图的变形
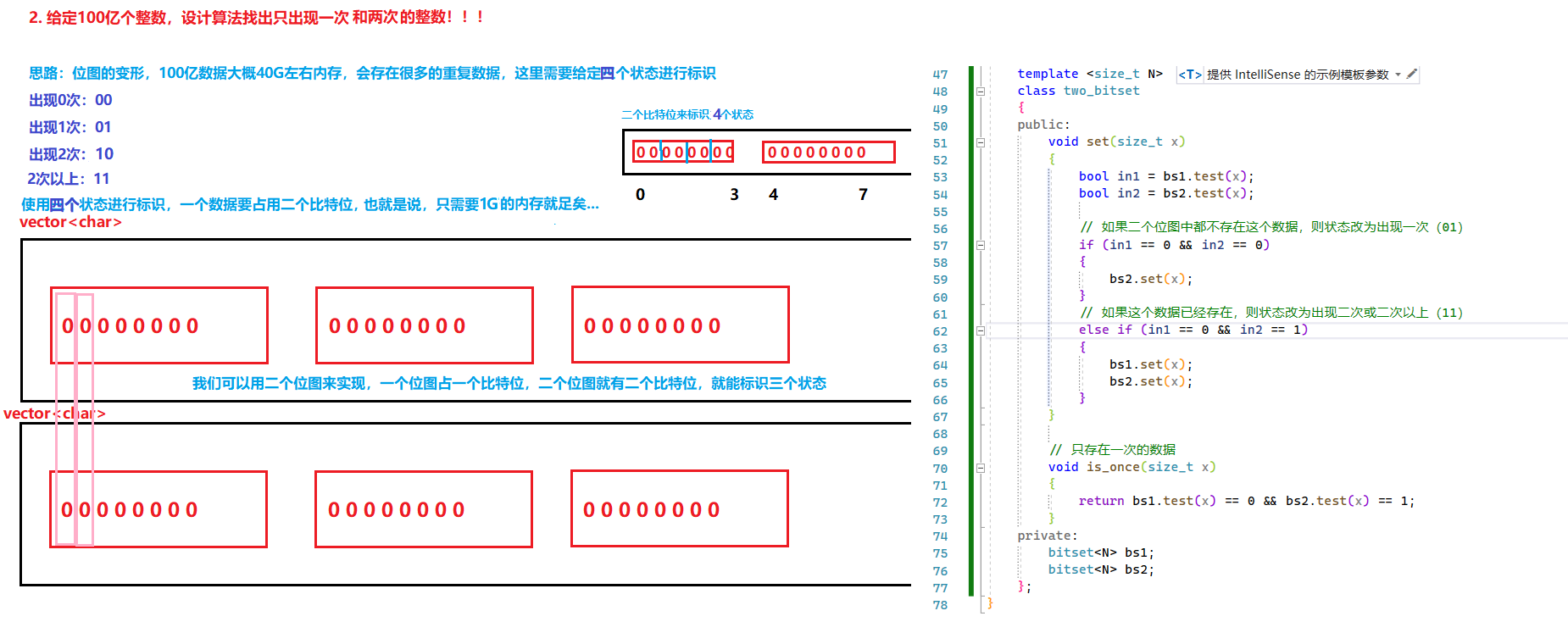
首先抛出一个问题:给定100亿个整数,设计算法找出只出现一次和二次的整数!!!
-
首先,使用位图是解决不了这个问题的,因为位图只能标识两种状态(0/1)
-
这道题需要标识四种状态才能解决问题
思路:
完整代码:
namespace myself
{
template <size_t N>class two_bitset{public:void set(size_t x){bool in1 = bs1.test(x);bool in2 = bs2.test(x);// 如果二个位图中都不存在这个数据,则状态改为出现一次(01)if (in1 == 0 && in2 == 0){bs2.set(x);}// 如果这个数据已经存在,则状态改为出现二次(10)else if (in1 == 0 && in2 == 1){bs1.set(x);bs2.reset(x);}// 如果这个数据已经存在二次以上,则状态改为(11)else{bs1.set(x);}}// 只存在一次的数据bool is_once(size_t x){return bs1.test(x) == 0 && bs2.test(x) == 1;}private:bitset<N> bs1;bitset<N> bs2;};
}










![[CISCN 2019 初赛]Love Math](https://img-blog.csdnimg.cn/2242dc011a4143daa655b86f0b8a645c.png)