编译原理
在传统编译语言的流程中,程序中的一段源代码在执行之前会经历三个步骤,统称为编译:
1.分词 / 词法分析:将字符串分解成有意义的代码块,这些代码块被称为词法单元(token)
var a = 2; => var、a、=、2、;
2.解析 / 语法分析:将词法单元流转换成抽象语法树(一个由元素逐级嵌套所组成的代表了程序语法结构的树,AST)

3.代码生成:将AST转换为可执行的代码(机器指令)
生成的机器指令,“为一个变量分配内存,将其命名为a,然后将值2保存进这个变量”
理解作用域
作用域与引擎、编译器
- 引擎:从头到尾负责整个 JavaScript 程序的编译及执行过程;
- 编译器 :负责词法分析、语法分析以及代码生成等 ;
- 作用域:负责收集并维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。
var a=1 个简单的赋值操作会执行两个动作
- 编译时声明:首先编译器会在当前作用域下声明一个变量(如果之前没有声明过)
- 运行时赋值:然后在运行时引擎会在作用域中查找该变量,如果找到就会进行赋值操作
引擎查询类型
引擎在作用域中查找变量时,引擎会为变量 a 进行LHS查询,还有另外一个查找的类型叫做RHS
RHS查询:获取某个变量的值LHS查询:查找的目的是对变量进行赋值
function foo(a) {var b = areturn a + b
}
var c=foo(2)来看一段三兄弟的对话把~
- 引擎:我要获取foo执行RHS,作用域你那有没?
- 作用域:有的老哥
- 引擎:谢谢,我执行一下它。好了,我现在还需要赋值a执行LHS。
- 作用域:好,编译器把它作为形参给我了。
- 引擎:好的,我现在就对它赋值2。
- 引擎:我又用到a了,不过这次我要获取下一对它RHS,还是得找你确定一下它的值
- 作用域:没问题,它没变过,它还是2。
- 引擎:非常感谢,下面我需要为b赋值执行一下LHS,我需要把a的值赋给它,你帮我看一下有没有b这个变量。
- 作用域:有的,给你
- 引擎:谢谢,接下来我需要对a和b都执行一下获取RHS,你帮我把它们的值给我好吗
- 作用域:拿去不谢
- 引擎:好的,我拿到了。现在我还有最后一件事要做,那就是c,我得对它进行赋值LHS,你帮我找一下,然后我好对它赋值。
- 作用域:没问题,编译器声明过它
- 引擎:谢谢,那我对它赋值了,大功告成!
作用域嵌套
作用域链
引擎从当前作用域开始查找变量,没有找到就一直往上找知道找到为止,或者找到全局作用域
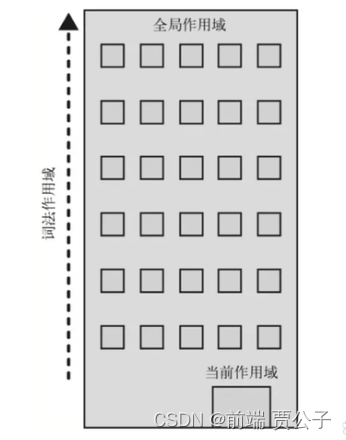
LHS和RHS 引用都会在当前楼层进行查找,如果没有找到,就会坐电梯前往上一层楼,如果还是没有找到就继续向上,以此类推。一旦抵达顶层(全局作用域),可能找到了你所需的变量,也可能没找到,但无论如何查找过程都将停止。
异常
LHS 和 RHS 区别:RHS 查询在所有嵌套的作用域中找不到变量时,则会抛出异常 ReferenceError;而 LRS 在所有嵌套的作用域找不到变量时,在非严格模式下,会在顶层作用域即全局作用域创建该变量,而在严格模式下则会出现同 RHS 一样的情况。
| 查询类型 | 变量还没有声明(普通模式下) | 变量还没有声明(严格模式下) |
|---|---|---|
| RHS | 抛出 ReferenceError 异常 | 抛出 ReferenceError 异常 |
| LHS | 全局作用域中创建一个具有该名称的变量,并返还给引擎 | 抛出 ReferenceError 异常 |
ReferenceError:同作用域判别失败相关; TypeError:作用域判别成功,但是对结果的操作是非法或者不合理的。
总结
查询机制
作用域是一套规则,用于确定在何处以及如何查找变量(标识符)。如果查找的目的是对变量进行赋值,那么就会使用LHS查询;如果目的是获取变量的值,就会使用RHS查询
作用域链
LHS和RHS查询都会在当前执行作用域中开始,如果有需要(也就是说它们没有找到所需的标识符),就会向上级作用域继续查找目标标识符,这样每次上升一级作用域(一层楼),最后抵达全局作用域(顶层),无论找到或没找到都将停止。
异常机制
不成功的RHS引用会导致抛出ReferenceError异常。不成功的LHS引用会导致自动隐式地创建一个全局变量(非严格模式下),该变量使用LHS引用的目标作为标识符,或者抛出ReferenceError异常(严格模式下)