论文地址:https://arxiv.org/pdf/2303.14123.pdf
论文代码:https://github.com/WentaoChen0813/SemanticPrompt
目录
- 1、存在的问题
- 2、算法简介
- 3、算法细节
- 3.1、预训练阶段
- 3.2、微调阶段
- 3.3、空间交互机制
- 3.4、通道交互机制
- 4、实验
- 4.1、对比实验
- 4.2、组成模块消融
- 4.3、插入层消融
- 4.4、Backbone和分类器消融
- 4.5、投影函数和池化消融
- 4.6、插入图像大小消融
1、存在的问题
目前,针对小样本问题,有一种比较有效的解决方案:
使用其他模态的辅助信息,例如自然语言,来辅助学习新概念。即根据样本的类名提取出文本特征,将文本特征和视觉特征相结合。
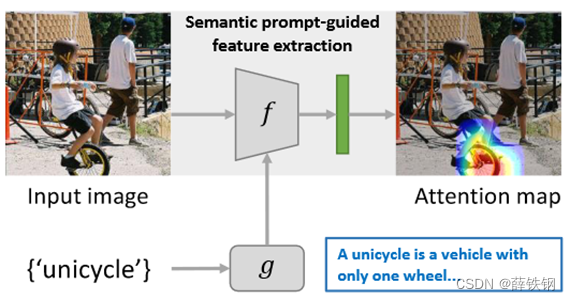
该思路存在的问题:文本特征可能包含了新类与已知类之间的语义联系,但缺少与底层视觉表示的交互。因此在只有有限的支持图像的情况下,直接从文本特征中得到类的原型会使学习到的视觉特征受到虚假特征的影响,例如背景杂乱时,难以产生准确的类原型。
例如,给定一个新类别“独轮车”的支持图像,特征提取器可能捕获包含独轮车和其他干扰物(如骑手和瓦片屋顶)的图像特征,而无法识别其他环境中的独轮车。
2、算法简介
本文提出了一种新颖的语义提示方法,利用类名的文本信息作为语义提示,自适应地调整特征提取网络,使得图像编码器只关注和语义提示相关的视觉特征,忽略其他干扰信息。
本文主要提出了一个语义提示SP模块和模块中两种互补的信息交互机制:
1、SP模块: 可以插入到特征提取器的任何层中,包含空间和通道交互部分。
2、空间交互机制: 将语义提示特征和图像块特征串联在一起,然后送入Transformer层中,通过自注意力层,语义提示可以和每个图像块特征进行信息交互从而使模型关注类别相关的图像区域。
3、通道交互机制: 首先从所有图像块中提取视觉特征,然后将视觉特征和语义提示特征拼接后送入MLP得到调制向量,最后将调制向量加到每个图像块特征上以实现对视觉特征逐通道的调整。
3、算法细节
网络的训练包括两个阶段:
第一阶段,通过对基数据集中的所有图像进行分类来预训练一个特征提取器 f f f。
第二阶段,采用元训练策略,使用语义提示SP对特征提取器 f f f进行微调。
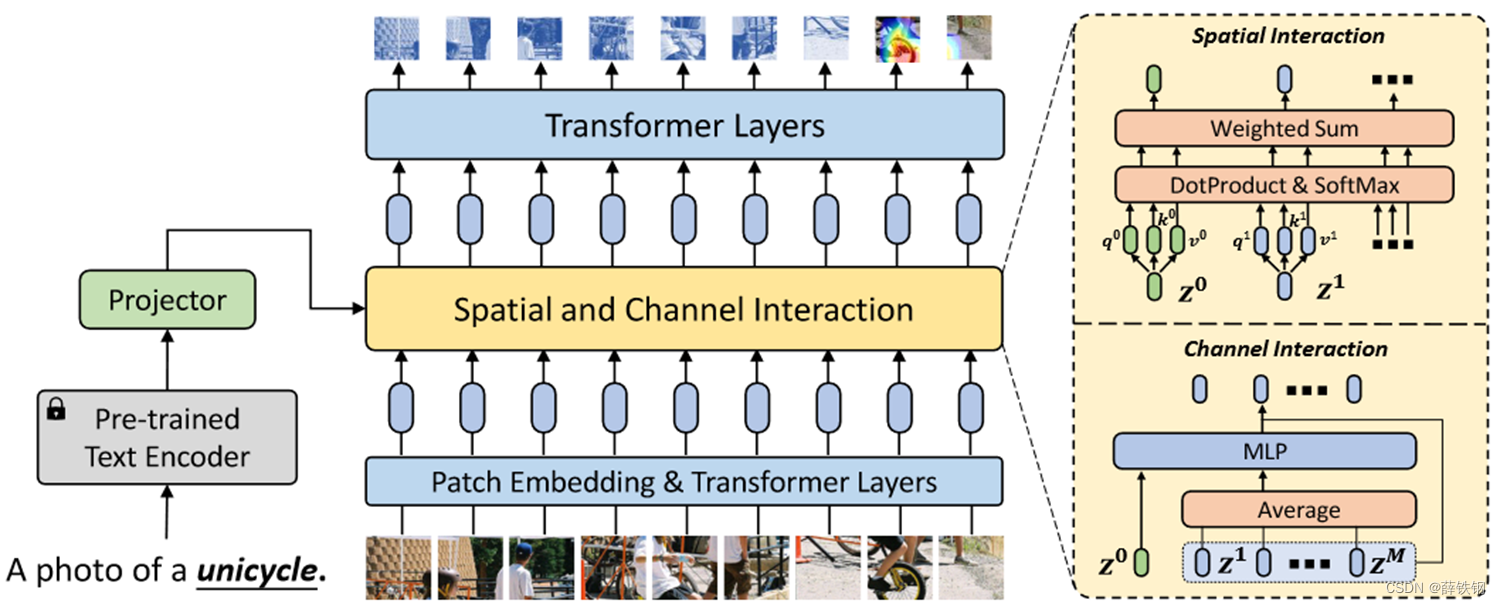
3.1、预训练阶段
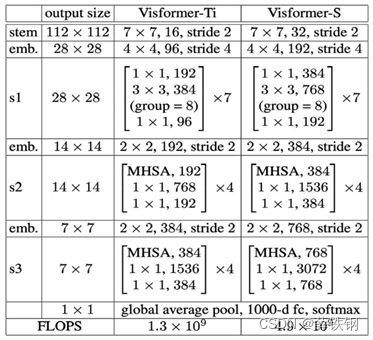
采用Visformer作为特征提取器 f f f,在基类数据集上完成训练。
Visformer是原始ViT的一个变体,用卷积块代替了前7个Transformer层,其网络结构如下图所示:
第一步,将输入图像 x ∈ R H × W × C x\in\mathbb{R}^{H\times W\times C} x∈RH×W×C划分为 M M M个图像块序列:
X = x p 1 , x p 2 , . . . , x p M , x p i ∈ R P × P × C X=x_p^1,x_p^2,...,x_p^M, \quad x_p^i\in\mathbb{R}^{P\times P\times C} X=xp1,xp2,...,xpM,xpi∈RP×P×C
第二步,将每个图像块映射为一个嵌入向量,并加入位置编码:
Z 0 = [ z 0 1 , z 0 2 , . . . , z 0 M ] , z 0 i ∈ R C z Z_0=[z_0^1,z_0^2,...,z_0^M], \quad z_0^i\in\mathbb{R}^{C_z} Z0=[z01,z02,...,z0M],z0i∈RCz
第三步,patch token被送入到 L L L层的Transformer层进行视觉特征的提取。
每层Transformer都由多头自注意力(MSA)模块、MLP 块、归一化层和残差连接组成。
第四步,最后,在第 L L L层,计算所有嵌入向量的平均值作为提取到的图像特征。
作为参考,同时给出Vision Transformer的网络结构:
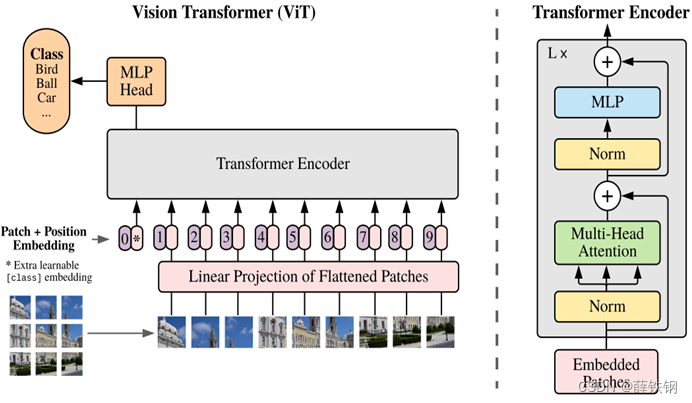
3.2、微调阶段
接下来,使用大规模预训练的NLP模型来从类名中提取文本特征。
采用元训练策略对特征提取器进行微调,使模型适应语义提示。
第一步,针对训练集中的支持图像 x s x^s xs,其类名为 y t e x t y^{text} ytext,将类名输入到预先训练好的文本编码器 g ( ⋅ ) g(\cdot) g(⋅)中,提取得到语义特征 g ( y t e x t ) g(y^{text}) g(ytext);
第二步,语义特征被送入训练好的特征提取器中计算图像的特征:
f g ( x s ) = f ( x s ∣ g ( y t e x t ) ) f_g(x^s)=f(x^s|g(y^{text})) fg(xs)=f(xs∣g(ytext))
第三步,在每个类中,将计算得到的支持图像的特征求平均,从而计算出第 i i i个类的原型:
p i = 1 K ∑ j = 1 K f g ( x j s ) p_i = \frac1K \sum_{j=1}^K f_g (x_j^s ) pi=K1∑j=1Kfg(xjs)
第四步,在元训练期间,冻结文本编码器 g ( ⋅ ) g(\cdot) g(⋅),通过交叉熵损失最大化查询样本 与其原型之间的特征相似性来微调其他参数。
3.3、空间交互机制
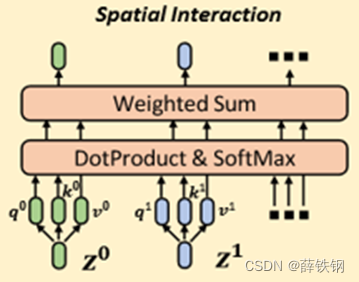
第一步,给定第 l l l层的语义特征 g ( y t e x t ) g(y^{text}) g(ytext)和图像块嵌入序列 Z l − 1 = [ z l − 1 1 , z l − 1 2 , . . . , z l − 1 M ] ∈ R M × C z Z_{l-1}=[z_{l-1}^1,z_{l-1}^2,...,z_{l-1}^M]\in\mathbb{R}^{M\times C_z} Zl−1=[zl−11,zl−12,...,zl−1M]∈RM×Cz,
使用投影函数调整语义特征的维度和图像块嵌入的维度一致 z 0 = h s ( g ( y t e x t ) ) ∈ R C z z^0=h_s\left(g(y^{text})\right)\in\mathbb{R}^{C_z} z0=hs(g(ytext))∈RCz
使用投影后的语义特征与图像块嵌入序列拼接 Z ^ l − 1 = [ z 0 , z l − 1 1 , . . . , z l − 1 M ] \hat{Z}_{l-1}=[z^0,z_{l-1}^1,...,z_{l-1}^M] Z^l−1=[z0,zl−11,...,zl−1M]
第二步,将扩展后的序列输入到Transformer层,其中包含多头自注意力模块MSA;
第三步,MSA将每个图像块嵌入映射为3个向量:
[ q , k , v ] = Z ^ l − 1 W q k v , q , k , v ∈ R N h × ( M + 1 ) × C h [q,k,v]=\hat{Z}_{l-1}W_{qkv},\quad q,k,v\in\mathbb{R}^{N_h\times(M+1)\times C_h} [q,k,v]=Z^l−1Wqkv,q,k,v∈RNh×(M+1)×Ch
第四步,取q和k之间的内积并沿空间维度执行softmax计算注意力权重A,注意力 权重用于选择和聚合来自不同位置的信息:
A = s o f t m a x ( q k T / C h 1 4 ) , A ∈ R N h × ( M + 1 ) × ( M + 1 ) A=softmax(qk^T/C_h^{\frac14}),\quad A\in\mathbb{R}^{N_h\times(M+1)\times(M+1)} A=softmax(qkT/Ch41),A∈RNh×(M+1)×(M+1)
第五步,通过连接所有头输出的注意力权重并通过线性投影得到最终输出:
M S A ( Z l − 1 ^ ) = ( A v ) W o u t MSA(\hat{Z_{l-1}})=(Av)W_{out} MSA(Zl−1^)=(Av)Wout
3.4、通道交互机制
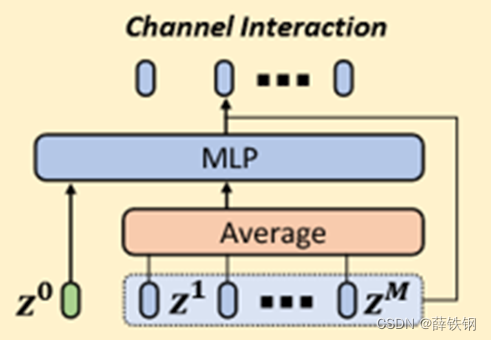
第一步,给定第 l l l层的语义特征 g ( y t e x t ) g(y^{text}) g(ytext)和图像块嵌入序列 Z l − 1 = [ z l − 1 1 , z l − 1 2 , . . . , z l − 1 M ] ∈ R M × C z Z_{l-1}=[z_{l-1}^1,z_{l-1}^2,...,z_{l-1}^M]\in\mathbb{R}^{M\times C_z} Zl−1=[zl−11,zl−12,...,zl−1M]∈RM×Cz,
计算所有的图像块嵌入的平均值,得到一个全局视觉上下文向量:
z l − 1 c = 1 M ∑ i = 1 M z l − 1 i z_{l-1}^c=\frac1M\sum_{i=1}^Mz_{l-1}^i zl−1c=M1∑i=1Mzl−1i
第二步,使用投影函数调整语义特征的维度和图像块嵌入的维度一致 z 0 = h c ( g ( y t e x t ) ) ∈ R C z z^0=h_c(g(y_{text}))\in\mathbb{R}^{C_z} z0=hc(g(ytext))∈RCz
第三步,使用投影后的语义特征与全局视觉上下文向量拼接 [ z 0 ; z l − 1 c ] [z^0;z_{l-1}^c] [z0;zl−1c]
第四步,将拼接后的向量送入两层的MLP得到调制向量:
β l − 1 = σ ( W 2 σ ( W 1 [ z 0 ; z l − 1 c ] + b 1 ) + b 2 ) \beta_{l-1}=\sigma(W_2\sigma(W_1[z^0;z_{l-1}^c]+b_1)+b_2) βl−1=σ(W2σ(W1[z0;zl−1c]+b1)+b2)
第五步,将调制向量添加到所有的图像块嵌入中:
Z ~ l − 1 = [ z l − 1 i + β l − 1 , ] i = 1 , 2 , . . . , M \tilde{Z}_{l-1}=[z_{l-1}^i+\beta_{l-1},]\quad i=1,2,...,M Z~l−1=[zl−1i+βl−1,]i=1,2,...,M
这样就可以在每个通道上调整视觉特征了。
4、实验
4.1、对比实验
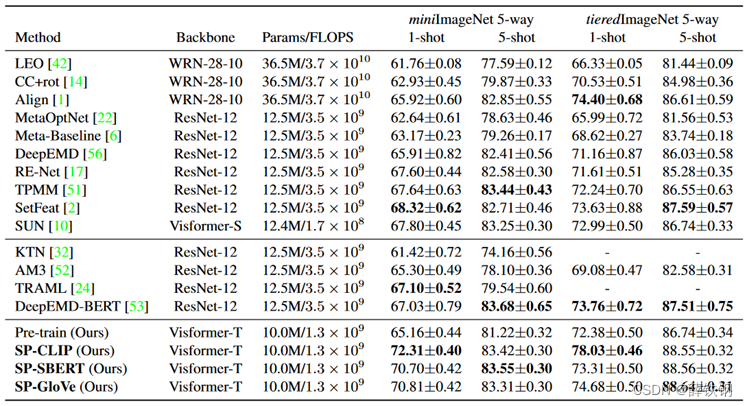
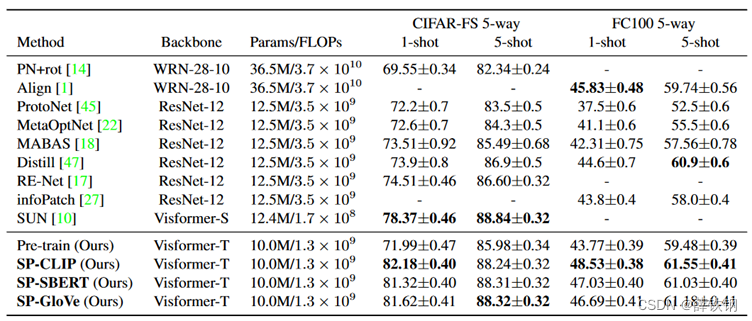
在四个数据集上进行了对比实验,报告准确率
第一部分的信息不使用语义信息,中间的方法利用来自类名的提示信息或描述类语义信息
带有CLIP的SP比SBERT和GloVe在1-shot上取得了更好的效果,这可能是因为CLIP的多模态预训练导致语义嵌入与视觉概念更好的对齐。
4.2、组成模块消融
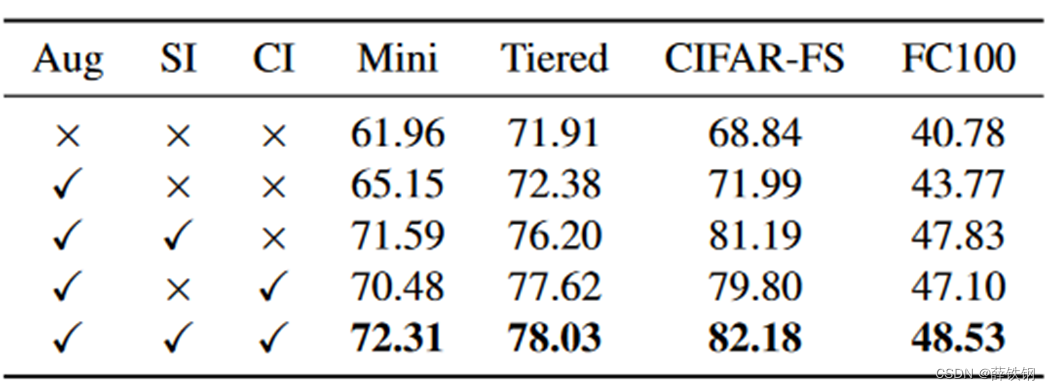
Aug:数据增强
SI:空间交互机制
CI:通道交互机制
4.3、插入层消融
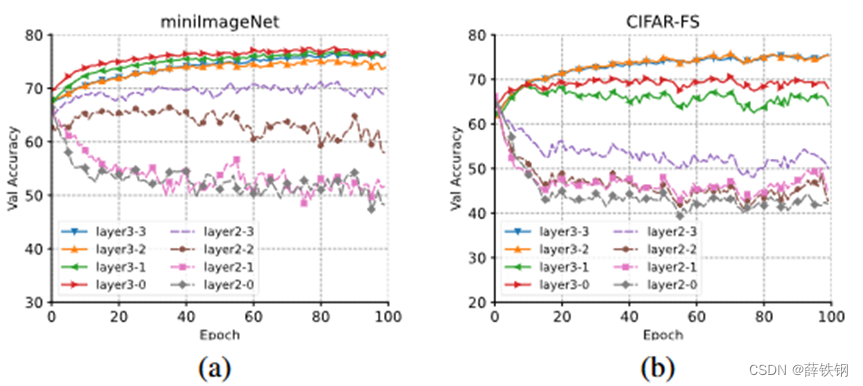
特征提取器有三个阶段,每个阶段含有多个Transformer层。理论上语义提示可以在任意层插入,实验研究了二、三阶段不同层插入语义提示的实验结果。
插入高层时模型的表现较好,插入低层时模型的表现下降。这是因为语义提示向量特定于类,更高层的网络层提取的特征特定于类,而在低层提取的特征会在类间共享。
语义提示插入三阶段的整体表现较好,语义提示默认插入位置为layer3-2(三阶段的第二层)。
4.4、Backbone和分类器消融
简单地用Visformer替换ResNet-12并不能获得显著的提升。
而在本文的网络结构中,即当使用语义提示明显可以提高性能。

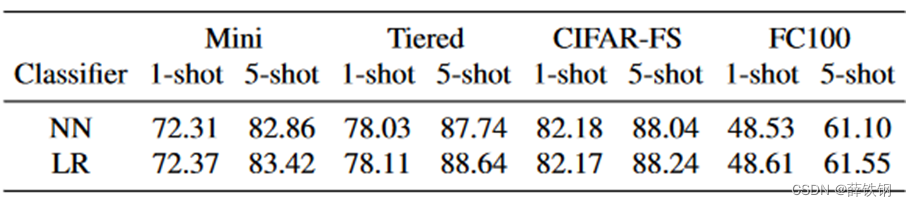
NN:余弦距离最近原型分类器。LR:线性逻辑回归分类器。
对于1-shot,NN分类器表现与LR分类器相当,而对于5-shot,LR从更多的训练样本中获益,性能比NN提高了0.53%。
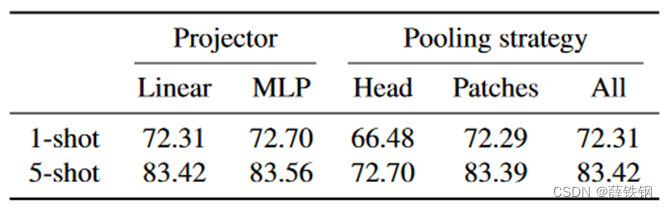
4.5、投影函数和池化消融
线性投影函数和MLP投影函数相比,MLP投影函数略占优势。
相比之下,池化策略对性能的影响要大得多。当采用“Head”策略时,1-shot和5-shot的学习精度都很差。这表明提示向量位置处的输出容易对语义特征过度拟合,忽略图像块中丰富的视觉特征
Head: 选择语义提示向量位置处的输出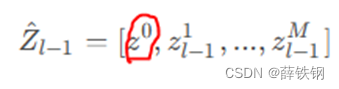
Patch: 对所有图像块的特征取平均
All: 对所有特征向量取平均
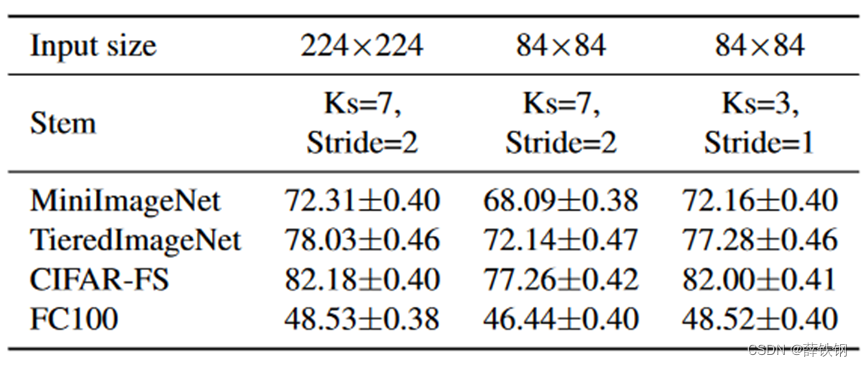
4.6、插入图像大小消融
保持卷积核大小和步长不变的情况下,缩小图像会导致精度下降,这是因为此时卷积核和步长太大不能捕获详细的视觉特征,应该相应地减少卷积核和步长,这样精度会提高。



——实操演示](https://img-blog.csdnimg.cn/direct/742f58c929d8415cb9830b0c829944e4.png)