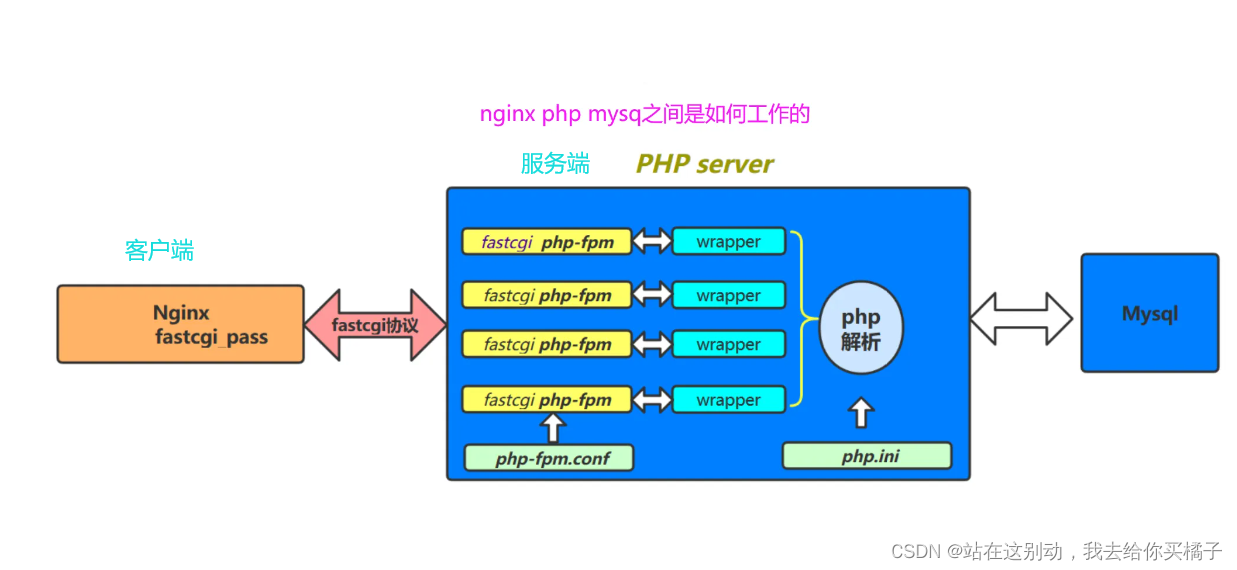
1. Nginx的工作原理
php-fpm.conf 是控制php-fpm守护进程的
php.ini是php解析器
工作进程:
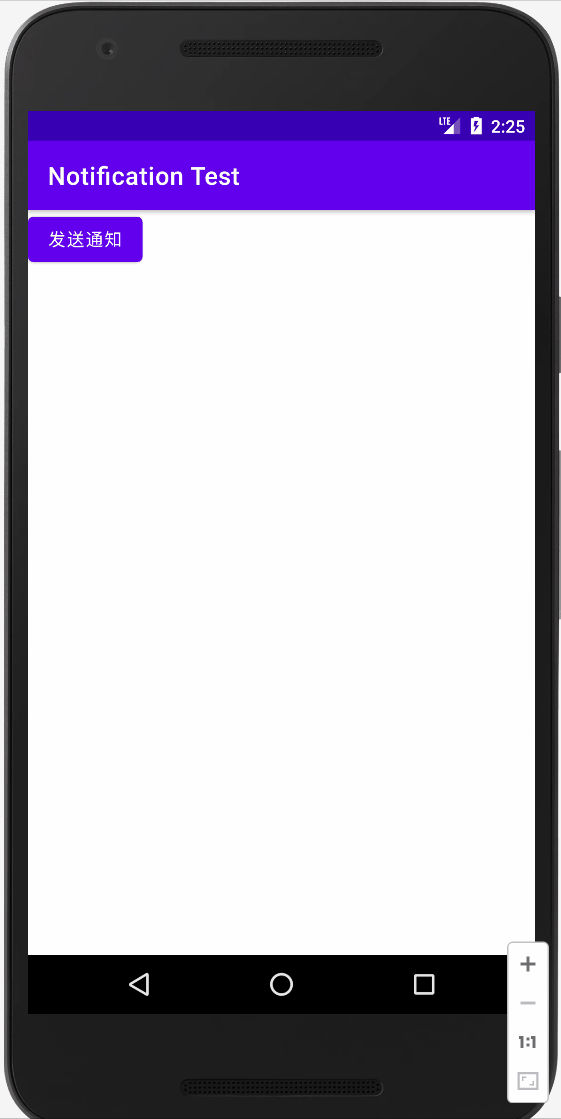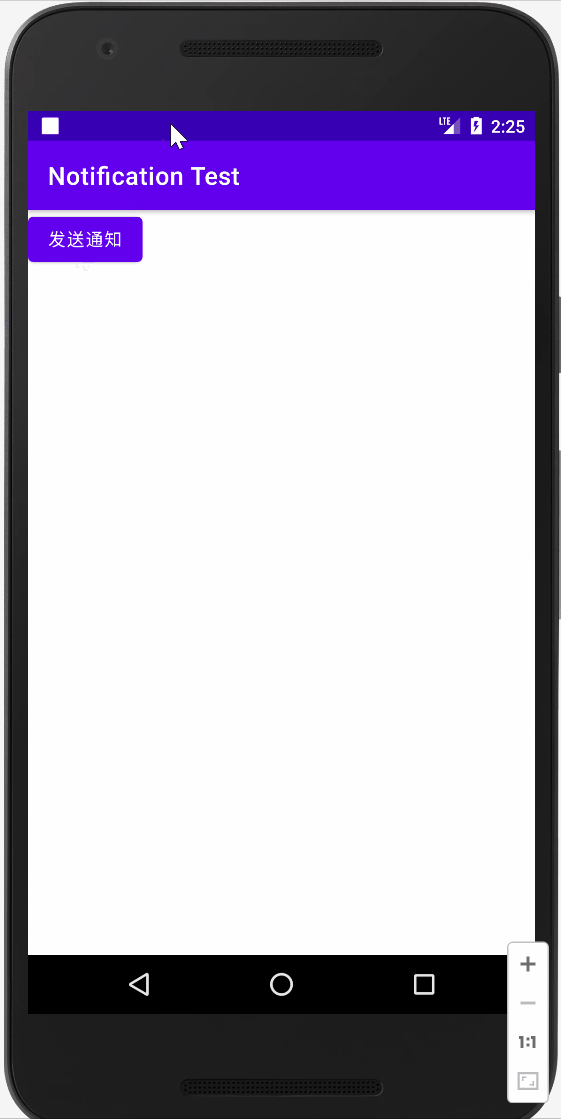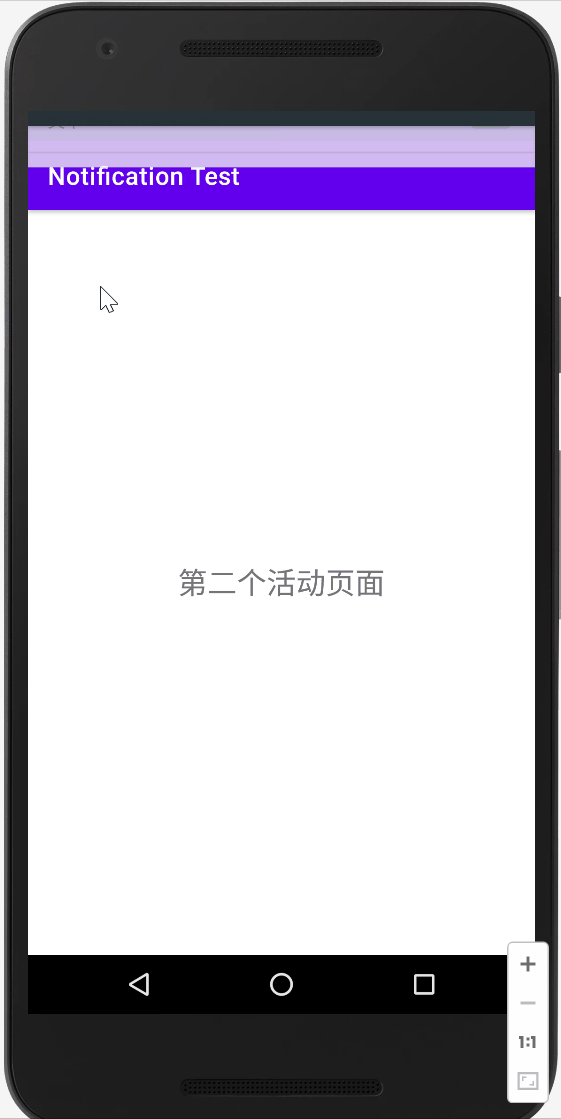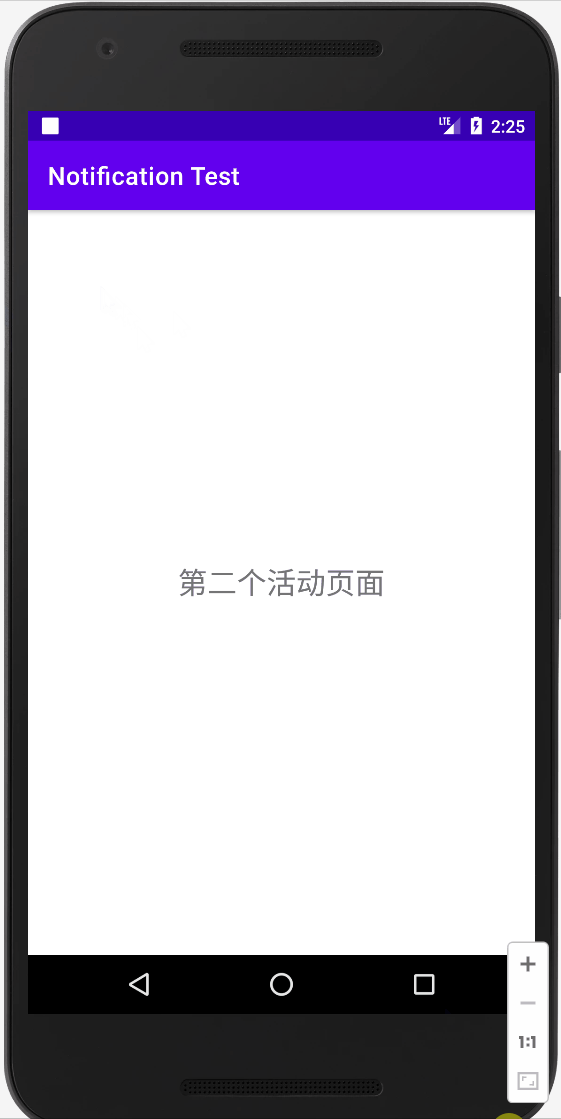
1.客户端通过域名进行请求访问时,会找Nginx对应的虚拟主机
2. Nginx对该请求进行判断,如果是静态请求,Nginx会自行处理,并将处理结果返回给用户浏览器
3. Nginx判断的请求如果为php请求,则调用FastCGI客户端,并且把请求也抛给FastCGI服务器,也就是php-fpm(扩展名是php的往后抛)
4. wapper调用php解析器来解析请求,如果发现这个请求里要连接数据库,就会在数据库中找数据。如果不需要找数据就是正常的动态请求。处理完毕后将数据返回给Nginx即可。
2.Nginx编译安装
上张博客Nginx网站服务详解(主配置-nginx.conf)_小羊吉米的博客-CSDN博客
3.mysql编译安装
1)安装依赖环境、创建运行用户、编译安装、
2)更改mysql的安装目录和配置文件的属组和属主

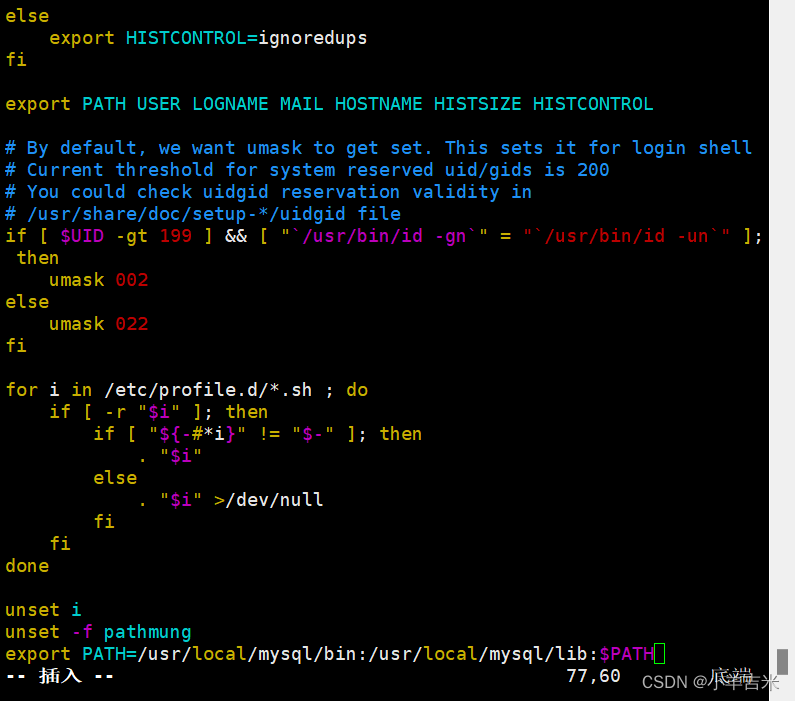
3)设置路径环境
4)初始化数据库

5)添加mysql系统服务

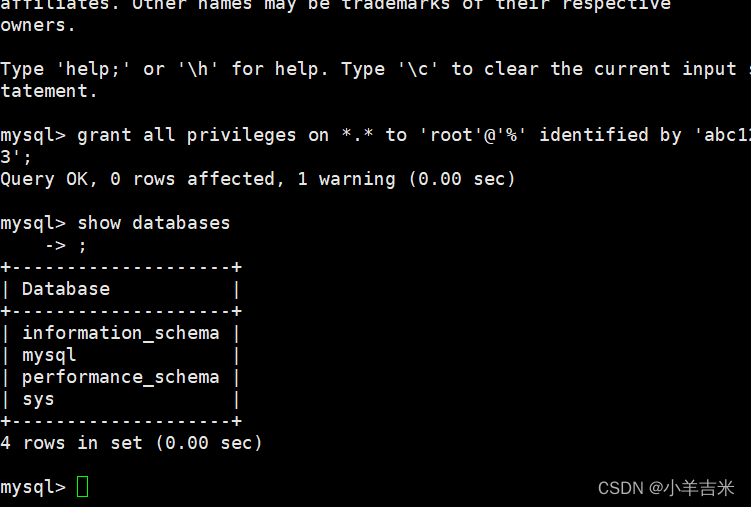
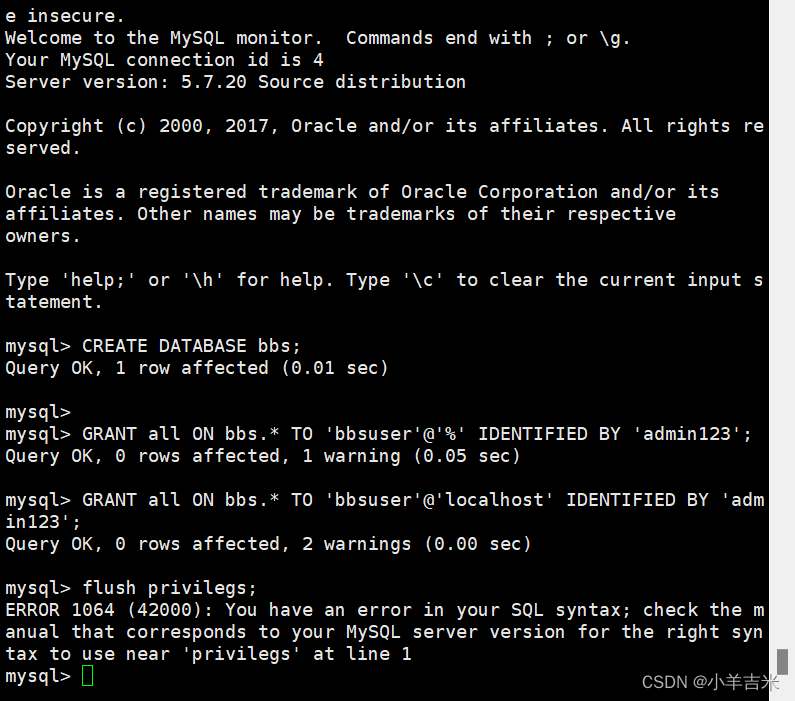
6)修改mysql的登录密码、授权远程登录
4.PHP的编译安装
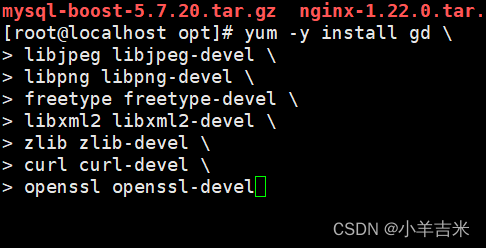
1)安装依赖环境包
2)编译安装


3)优化路径

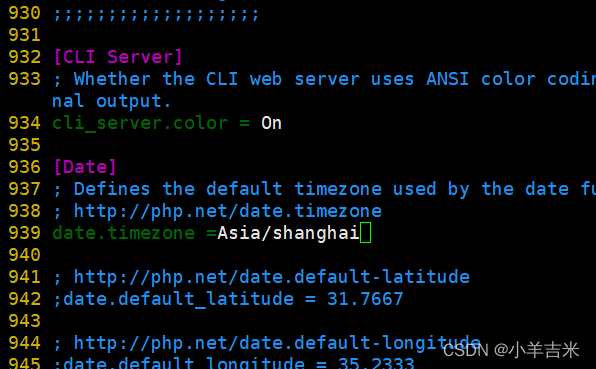
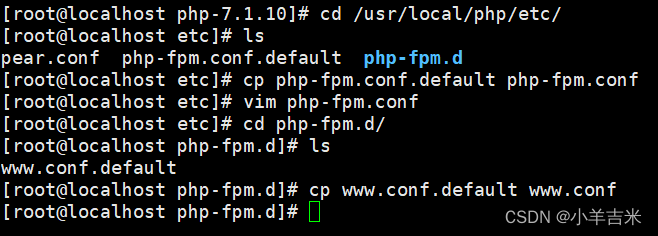
4)调整php配置文件
php有三个配置文件:
php.ini 主配置文件
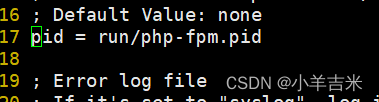
php-fpm.conf 进程服务配置文件
www.conf 扩展配置文件
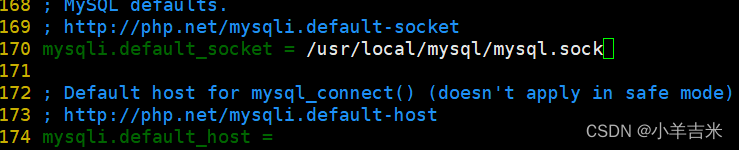
调整进程服务配置文件
调整扩展配置文件
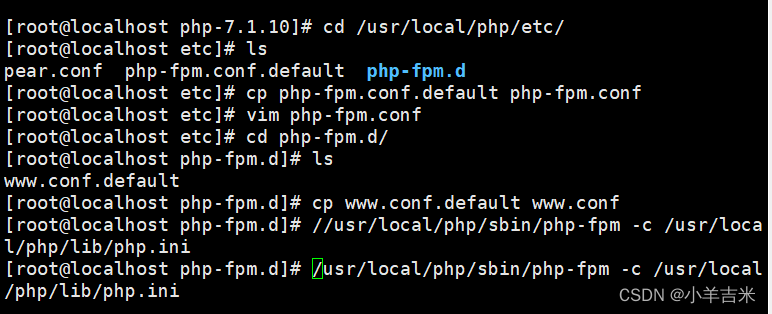
5)启动php-fpm
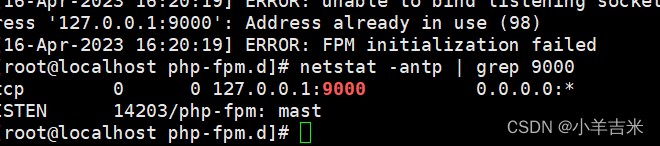

6)配置Nginx支持PHPj解析
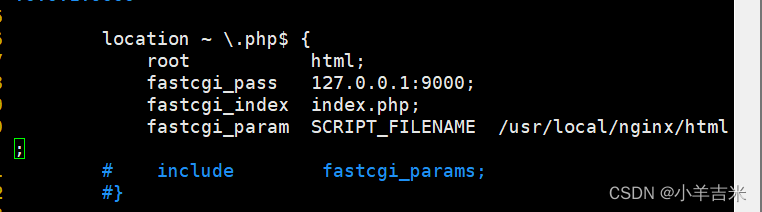
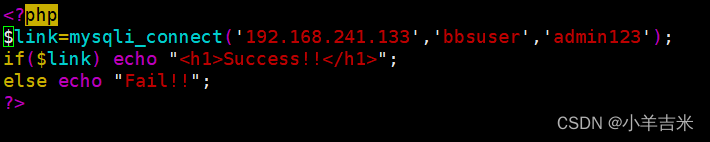
5.验证PHP与nginx是否连接
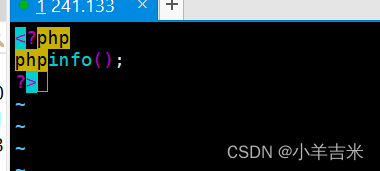
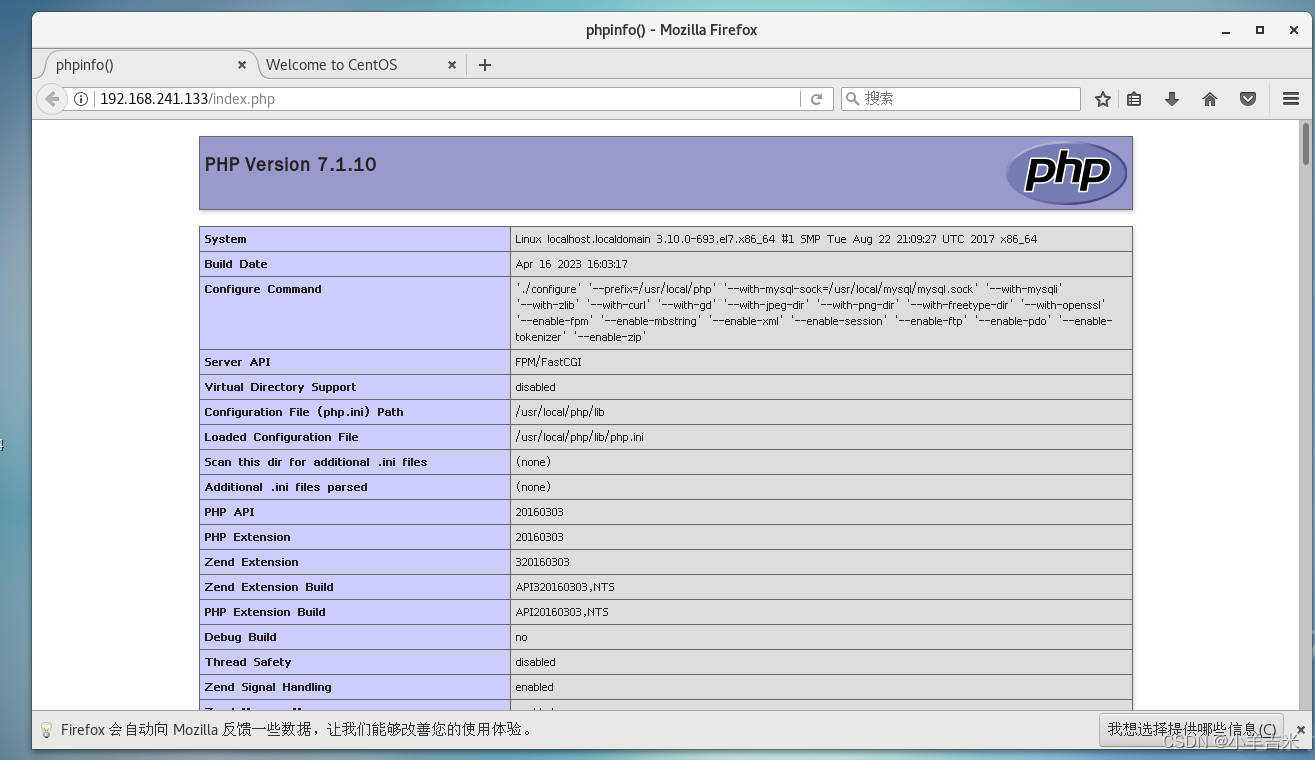
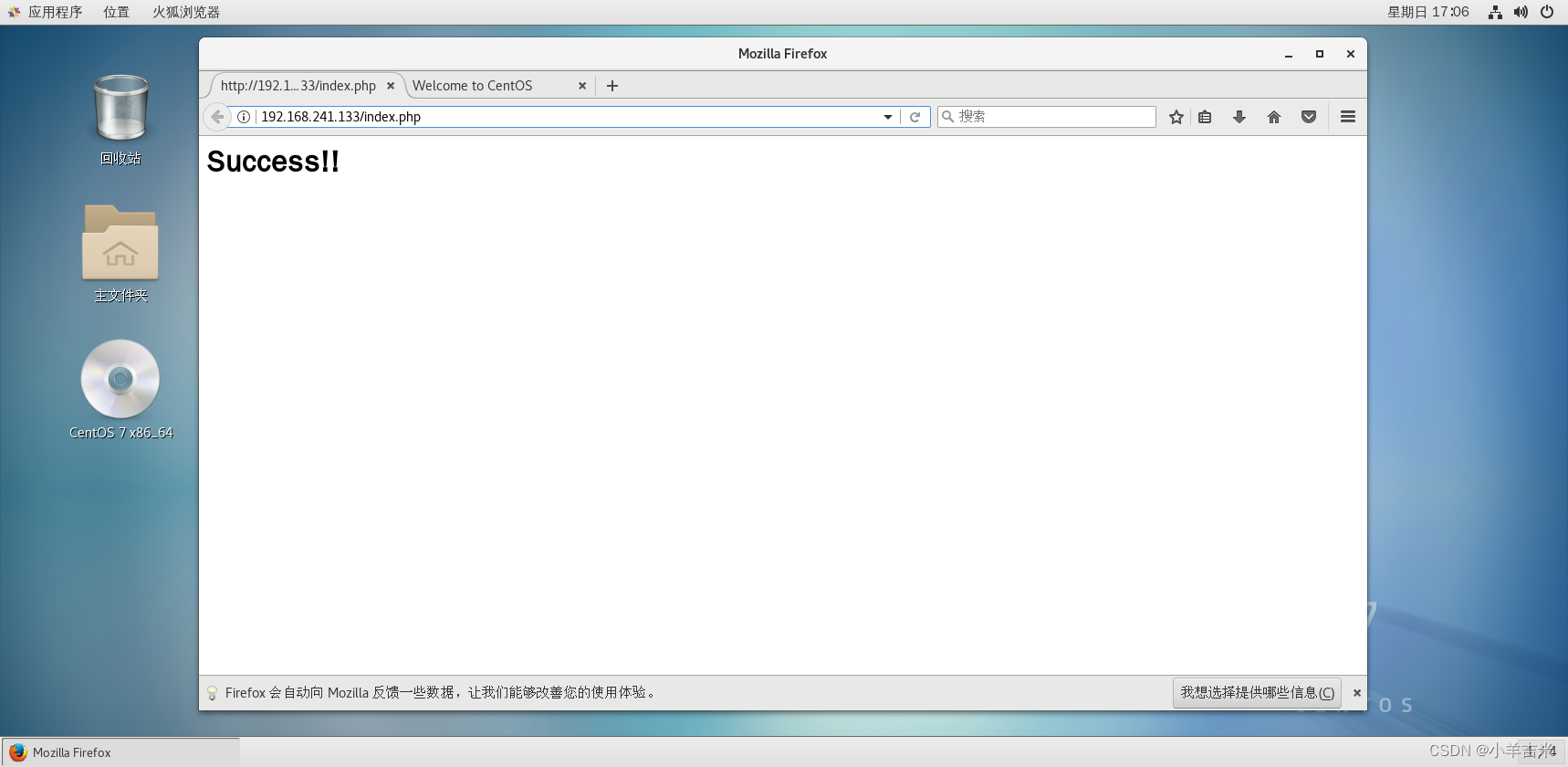
6.验证lnmp搭建是否成功

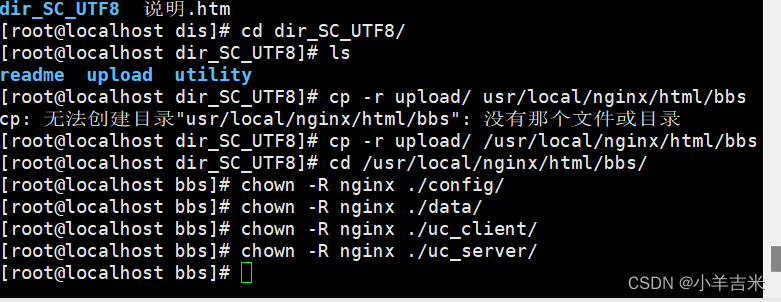
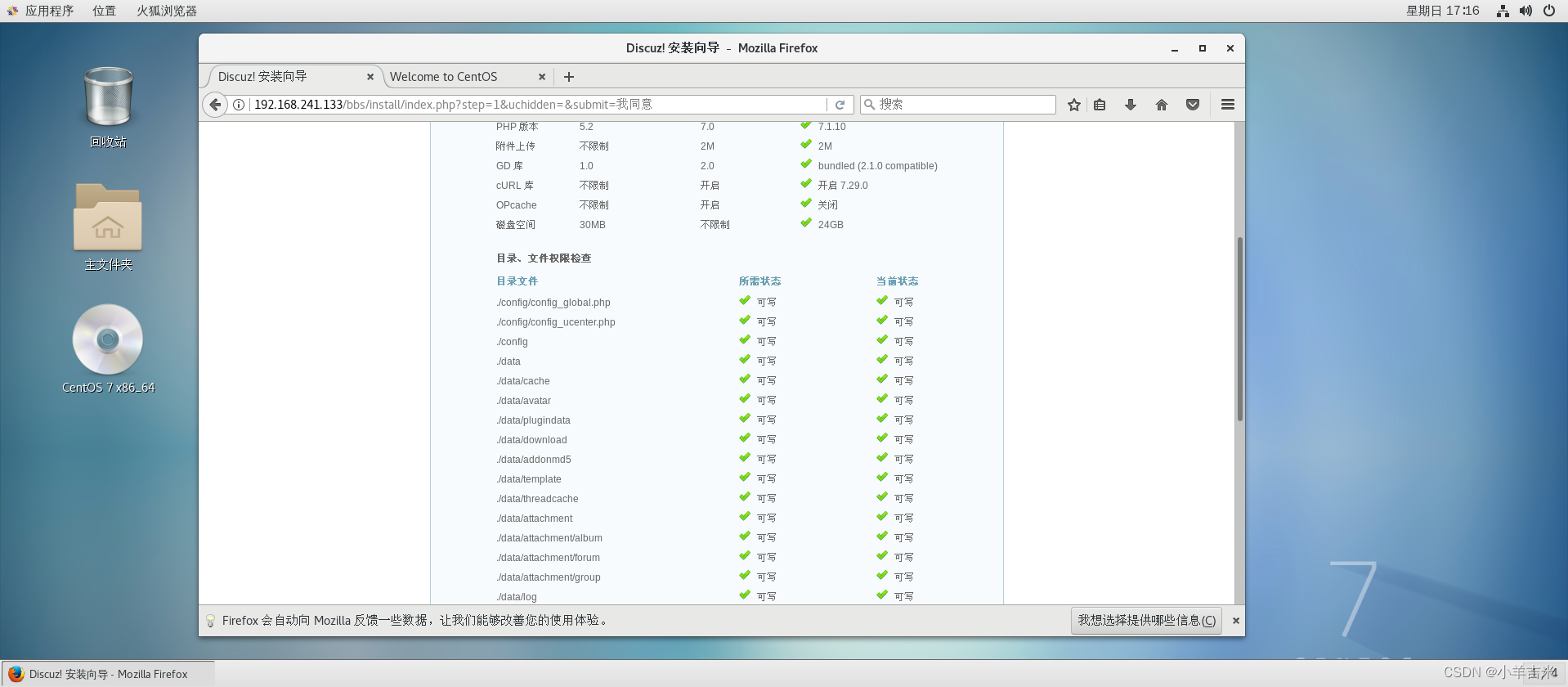
7.搭建Discuz论坛
1)调整论坛权限