OceanBase数据库中可使用Hash Join联接算法,这种算法可以依据某些字段对两个表进行等值匹配连接。然而,当涉及连接的表(特别是作为Probe Table的表)数据量较大时,Hash Join的性能会显著下降。针对这一问题,通常采取的方法是运用Runtime Filter来提升查询效率。
本文将详细阐述OceanBase中的Runtime Filter功能,并探讨在4.2版本中该功能的优化细节。
OceanBase中的Runtime Filter能力
Runtime Filter是一种用于优化Hash Join性能的技术,它可以通过减少Hash Join需要Probe的数据量来提高查询的效率。比如,在星形连接的多张维度表和事实表Join的场景中,Runtime Filter是一个非常有效的优化手段。本质上,Runtime Filter是一类过滤器,它可以利用Hash Join的Build过程构建一个轻量的Filter,然后将Filter广播发送给参与Probe的大表,Probe Table可以使用多个Runtime Filter提前在存储层过滤数据,减少真正参与Hash Join及网络传输的数据,从而提高查询效率。
Runtime Filter的数据结构有Bloom Filter、In Filter、Range Filter三种,始终贯穿Runtime Filter的使用类别。下面通过Runtime Filter的各类别来说明Runtime Filter的作用是使用场景。
1、Runtime Filter跨机传输需求场景
首先,按照是否需要跨机传输来看,Runtime Filter可以分为Local和Global两类,无论是Local还是Global,都可以使用这三种结构的Runtime Filter。我们通过explain可以显示当前计划中的Runtime Filter。计划中和Runtime Filter相关的算子有:
JOIN FILTER CREATE: 表示创建 Runtime Filter 的算子,其后面的NAME区分了同一个计划中的多个Runtime Filter
JOIN FILTER USE: 表示使用 Runtime Filter 的算子,拥有相同NAME的JOIN FILTER CREATE和JOIN FILTER USE是一对。由于filter下推逻辑的存在,真正使用Runtime Filter算子一般是其下方的Table Scan算子。PART JOIN FILTER CREATE:表示创建 Part Join Filter 的算子, 其后面的NAME区分了同一个计划中的多个Runtime Filter
PX PARTITION HASH JOIN-FILTER: 表示使用 Part Join Filter 的算子,拥有相同NAME的PART JOIN FILTER CREATE和PX PARTITION HASH JOIN-FILTER是一对。(1)Local Runtime Filter
Local Runtime Filter意味着Runtime Filter无需经历网络传输,构建的Filter只需要在本地节点计算过滤,这通常适用于Hash Join Probe侧没有Shuffle的场景。下面为Local Runtime Filter计划:
obclient> create table tt1(v1 int, v2 int) partition by hash(v1) partitions 5;
obclient> create table tt2(v1 int, v2 int) partition by hash(v1) partitions 5;
obclient> explain select /*+ px_join_filter(tt2) parallel(4) */ * from tt1 join tt2 on tt1.v1=tt2.v1;
+------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------------------------------------+
| ============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |7 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000|1 |6 | |
| |2 | └─PX PARTITION ITERATOR | |1 |6 | |
| |3 | └─HASH JOIN | |1 |6 | |
| |4 | ├─JOIN FILTER CREATE|:RF0000 |1 |3 | |
| |5 | │ └─TABLE FULL SCAN |tt2 |1 |3 | |
| |6 | └─JOIN FILTER USE |:RF0000 |1 |4 | |
| |7 | └─TABLE FULL SCAN |tt1 |1 |4 | |
| ============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(tt1.v1, tt1.v2, tt2.v1, tt2.v2)]), filter(nil), rowset=256 |
| 1 - output([INTERNAL_FUNCTION(tt1.v1, tt1.v2, tt2.v1, tt2.v2)]), filter(nil), rowset=256 |
| dop=4 |
| 2 - output([tt1.v1], [tt2.v1], [tt2.v2], [tt1.v2]), filter(nil), rowset=256 |
| partition wise, force partition granule |
| 3 - output([tt1.v1], [tt2.v1], [tt2.v2], [tt1.v2]), filter(nil), rowset=256 |
| equal_conds([tt1.v1 = tt2.v1]), other_conds(nil) |
| 4 - output([tt2.v1], [tt2.v2]), filter(nil), rowset=256 |
| RF_TYPE(in, range, bloom), RF_EXPR[tt2.v1] |
| 5 - output([tt2.v1], [tt2.v2]), filter(nil), rowset=256 |
| access([tt2.v1], [tt2.v2]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, |
| range_key([tt2.__pk_increment]), range(MIN ; MAX)always true |
| 6 - output([tt1.v1], [tt1.v2]), filter(nil), rowset=256 |
| 7 - output([tt1.v1], [tt1.v2]), filter([RF_IN_FILTER(tt1.v1)], [RF_RANGE_FILTER(tt1.v1)], [RF_BLOOM_FILTER(tt1.v1)]), rowset=256 |
| access([tt1.v1], [tt1.v2]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false,false,false], |
| range_key([tt1.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------------------------------------------------------+
32 rows in set (0.045 sec)在计划中显示为JOIN FILTER CREATE 和 JOIN FILTER USE的这一对算子就是Runtime Filter。Name为RF0000的4号和6号算子在该计划中构建了一个Local Runtime FIlter,该Filter无需网络传播,仅在本机使用。
(2)Global Runtime FIlter
Global Runtime Filter意味着该Filter需要广播传输给多个执行节点,并且在计划形态中可以按需将Runtime Filter嵌套下压至计划中的任意位置完成过滤。相比Local Runtime Filter,由于节省的代价不仅包括SQL层投影及计算开销,还包括了网络传输,因此往往能获得不错的执行性能提升。下面为Global Runtime Filter计划:
obclient> create table t1 (C1_RAND int, C2_RAND int, C3_RAND int, C4_RAND int, C5_RAND int) partition by hash(C5_RAND) partitions 5;
obclient> create table t2 (C1_RAND int, C2_RAND int, C3_RAND int, C4_RAND int, C5_RAND int) partition by hash(C5_RAND) partitions 5;
obclient> create table t3 (C1_RAND int, C2_RAND int, C3_RAND int, C4_RAND int, C5_RAND int) partition by hash(C5_RAND) partitions 5;
obclient> explain basic select /*+ leading(a (b c)) parallel(3) use_hash(b) use_hash(c) pq_distribute(c hash hash) px_join_filter(c a) px_join_filter(c b) */ count(*) from t1 a, t2 b, t3 c where a.C1_RAND=b.C1_RAND and a.C2_RAND = c.C2_RAND and b.C3_RAND = c.C3_RAND;
+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ======================================================== |
| |ID|OPERATOR |NAME | |
| -------------------------------------------------------- |
| |0 |SCALAR GROUP BY | | |
| |1 |└─PX COORDINATOR | | |
| |2 | └─EXCHANGE OUT DISTR |:EX10003| |
| |3 | └─MERGE GROUP BY | | |
| |4 | └─SHARED HASH JOIN | | |
| |5 | ├─JOIN FILTER CREATE |:RF0001 | |
| |6 | │ └─EXCHANGE IN DISTR | | |
| |7 | │ └─EXCHANGE OUT DISTR (BC2HOST)|:EX10000| |
| |8 | │ └─PX BLOCK ITERATOR | | |
| |9 | │ └─TABLE FULL SCAN |a | |
| |10| └─HASH JOIN | | |
| |11| ├─JOIN FILTER CREATE |:RF0000 | |
| |12| │ └─EXCHANGE IN DISTR | | |
| |13| │ └─EXCHANGE OUT DISTR (HASH) |:EX10001| |
| |14| │ └─PX BLOCK ITERATOR | | |
| |15| │ └─TABLE FULL SCAN |b | |
| |16| └─EXCHANGE IN DISTR | | |
| |17| └─EXCHANGE OUT DISTR (HASH) |:EX10002| |
| |18| └─JOIN FILTER USE |:RF0000 | |
| |19| └─JOIN FILTER USE |:RF0001 | |
| |20| └─PX BLOCK ITERATOR | | |
| |21| └─TABLE FULL SCAN |c | |
| ======================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([T_FUN_COUNT_SUM(T_FUN_COUNT(*))]), filter(nil), rowset=256 |
| group(nil), agg_func([T_FUN_COUNT_SUM(T_FUN_COUNT(*))]) |
| 1 - output([T_FUN_COUNT(*)]), filter(nil), rowset=256 |
| 2 - output([T_FUN_COUNT(*)]), filter(nil), rowset=256 |
| dop=3 |
| 3 - output([T_FUN_COUNT(*)]), filter(nil), rowset=256 |
| group(nil), agg_func([T_FUN_COUNT(*)]) |
| 4 - output(nil), filter(nil), rowset=256 |
| equal_conds([a.C1_RAND = b.C1_RAND], [a.C2_RAND = c.C2_RAND]), other_conds(nil) |
| 5 - output([a.C2_RAND], [a.C1_RAND]), filter(nil), rowset=256 |
| RF_TYPE(in, range, bloom), RF_EXPR[a.C2_RAND] |
| 6 - output([a.C2_RAND], [a.C1_RAND]), filter(nil), rowset=256 |
| 7 - output([a.C2_RAND], [a.C1_RAND]), filter(nil), rowset=256 |
| dop=3 |
| 8 - output([a.C1_RAND], [a.C2_RAND]), filter(nil), rowset=256 |
| 9 - output([a.C1_RAND], [a.C2_RAND]), filter(nil), rowset=256 |
| access([a.C1_RAND], [a.C2_RAND]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, |
| range_key([a.__pk_increment]), range(MIN ; MAX)always true |
| 10 - output([b.C1_RAND], [c.C2_RAND]), filter(nil), rowset=256 |
| equal_conds([b.C3_RAND = c.C3_RAND]), other_conds(nil) |
| 11 - output([b.C3_RAND], [b.C1_RAND]), filter(nil), rowset=256 |
| RF_TYPE(in, range, bloom), RF_EXPR[b.C3_RAND] |
| 12 - output([b.C3_RAND], [b.C1_RAND]), filter(nil), rowset=256 |
| 13 - output([b.C3_RAND], [b.C1_RAND]), filter(nil), rowset=256 |
| (#keys=1, [b.C3_RAND]), dop=3 |
| 14 - output([b.C1_RAND], [b.C3_RAND]), filter(nil), rowset=256 |
| 15 - output([b.C1_RAND], [b.C3_RAND]), filter(nil), rowset=256 |
| access([b.C1_RAND], [b.C3_RAND]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, |
| range_key([b.__pk_increment]), range(MIN ; MAX)always true |
| 16 - output([c.C3_RAND], [c.C2_RAND]), filter(nil), rowset=256 |
| 17 - output([c.C3_RAND], [c.C2_RAND]), filter(nil), rowset=256 |
| (#keys=1, [c.C3_RAND]), dop=3 |
| 18 - output([c.C3_RAND], [c.C2_RAND]), filter(nil), rowset=256 |
| 19 - output([c.C3_RAND], [c.C2_RAND]), filter(nil), rowset=256 |
| 20 - output([c.C2_RAND], [c.C3_RAND]), filter(nil), rowset=256 |
| 21 - output([c.C2_RAND], [c.C3_RAND]), filter([RF_IN_FILTER(c.C3_RAND)], [RF_RANGE_FILTER(c.C3_RAND)], [RF_BLOOM_FILTER(c.C3_RAND)], [RF_IN_FILTER(c.C2_RAND)], |
| [RF_RANGE_FILTER(c.C2_RAND)], [RF_BLOOM_FILTER(c.C2_RAND)]), rowset=256 |
| access([c.C2_RAND], [c.C3_RAND]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false,false,false,false,false,false], |
| range_key([c.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
70 rows in set (0.103 sec)5号算子对应RF0001,11号算子对应RF000,均下推到21号table full scan算子上进行过滤,此过程横跨了多个DFO,需要通过网络传输,属于Global Runtime Filter。
2、Runtime Filter生效功能场景
其次,从Runtime Filter生效的功能而言,Runtime Filter可以分为过滤连接数据的Filter和过滤分区的Filter两类。第一类为普通Runtime Filter,支持三种数据结构;第二类为Part Join Filter,当前仅支持Bloom Filter。下面重点介绍Part Join Filter。
Hash Join的执行流程是左侧数据阻塞建哈希表, 右侧逐行匹配数据。左侧建哈希表会获取左侧所有数据。如果可以获取左侧所有数据关于右侧某表的分区分布特征(按照右表的分区方式计算出左表关于右表的分区id), 那么在右侧扫描该表数据时,可以根据已统计的分区分布特征提前过滤掉不必要的分区,从而提升性能,Part Bloom Filter的引入正是为了优化这一场景。
想要在Hash Join左侧计算出按照右侧某表分区方式的具体分区,Join的连接键必须包含右侧该表的分区键,这是生成Part Bloom Filter的前提。
obclient [mysql]> create table t1(v1 int);
obclient [mysql]> create table t2(v1 int) partition by hash(v1) partitions 5;
obclient [mysql]> explain select /*+ parallel(3) leading(t1 t2) px_part_join_filter(t2)*/ * from t1 join t2 on t1.v1=t2.v1;
+-------------------------------------------------------------------------------+
| Query Plan |
+-------------------------------------------------------------------------------+
| ======================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |5 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10001|1 |4 | |
| |2 | └─HASH JOIN | |1 |4 | |
| |3 | ├─PART JOIN FILTER CREATE |:RF0000 |1 |1 | |
| |4 | │ └─EXCHANGE IN DISTR | |1 |1 | |
| |5 | │ └─EXCHANGE OUT DISTR (PKEY)|:EX10000|1 |1 | |
| |6 | │ └─PX BLOCK ITERATOR | |1 |1 | |
| |7 | │ └─TABLE FULL SCAN |t1 |1 |1 | |
| |8 | └─PX PARTITION HASH JOIN-FILTER|:RF0000 |1 |3 | |
| |9 | └─TABLE FULL SCAN |t2 |1 |3 | |
| ======================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.v1, t2.v1)]), filter(nil), rowset=256 |
| 1 - output([INTERNAL_FUNCTION(t1.v1, t2.v1)]), filter(nil), rowset=256 |
| dop=3 |
| 2 - output([t1.v1], [t2.v1]), filter(nil), rowset=256 |
| equal_conds([t1.v1 = t2.v1]), other_conds(nil) |
| 3 - output([t1.v1]), filter(nil), rowset=256 |
| RF_TYPE(bloom), RF_EXPR[t1.v1] |
| 4 - output([t1.v1]), filter(nil), rowset=256 |
| 5 - output([t1.v1]), filter(nil), rowset=256 |
| (#keys=1, [t1.v1]), dop=3 |
| 6 - output([t1.v1]), filter(nil), rowset=256 |
| 7 - output([t1.v1]), filter(nil), rowset=256 |
| access([t1.v1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 8 - output([t2.v1]), filter(nil), rowset=256 |
| affinitize |
| 9 - output([t2.v1]), filter(nil), rowset=256 |
| access([t2.v1]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
+-------------------------------------------------------------------------------+在计划中显示为 PART JOIN FILTER CREATE 的3号算子和 PX PARTITION HASH JOIN-FILTER的8号算子就是一对Part Join Filter,3号算子创建Part Join Filter,他会应用到8号算子中对t2表的分区进行过滤。
手动分配Runtime Filter
在默认配置下,当Join基于连接键的过滤性高于一定条件时(目前约为60%)会默认创建三种Runtime Filter数据结构:
- In Filter,内部使用hash表进行过滤判定;
- Range Filter,内部使用最大最小值进行过滤判定;
- Bloom Filter,自身就是一种过滤器。
在过滤优先级上,由于In Filter具有最准的过滤性,执行器当In Filter被启用时,其他两种Filter会被自适应关闭,在执行器根据实际NDV值确定是否使用In Filter。此外,每种Filter在实际计算中会根据实时过滤性自适应Disable Filter以及重新Enable Filter。
Runtime Filter的使用场景仅限于Hash Join,当连接类型不为Hash Join时,优化器将不会分配Runtime Filter。一般情况下,优化器会自动分配Runtime Filter,如果优化器并未分配Runtime Filter,大家也可以通过hint手动分配Runtime Filter。
我们可以通过px_join_fitler以及px_part_join_filter来手动打开runtime filter/part join filter。
/*+ px_join_filter(join_right_table_name)*/
/*+ px_part_join_filter(join_right_table_name)*/也可以通过no_px_join_filter以及px_part_join_filter来手动关闭runtime filter/part join filter。
/*+ no_px_join_filter(join_right_table_name)*/
/*+ no_px_part_join_filter(join_right_table_name)*/需要注意的是,在并行度为1的场景下,不会分配Runtime Filter,我们需要至少指定并行度为2。
/*+ parallel(2) */在手动分配Runtime Filter的过程中,会涉及一些系统变量,以下提供了4个系统变量用于在需要场景下调整Runtime Filter执行相关策略。
系统变量1:runtime_filter_type。
-- oracle模式
alter system set runtime_filter_type = 'BLOOM_FILTER,RANGE,IN';
-- mysql模式
set runtime_filter_type = 'BLOOM_FILTER,RANGE,IN';runtime_filter_type的默认值为'BLOOM_FILTER,RANGE,IN',表示启用三种类型的Runtime Filter,当runtime_filter_type='' 时,表示不启用任何类型的Runtime Filter。一般情况下,不需要特别指定runtime_filter_type类型,使用默认值即可,OceanBase会在优化和执行阶段选择最优的Runtime Filter类型进行过滤。
系统变量2:runtime_filter_max_in_num。
默认为1024,代表In Filter使用的默认NDV为1024。若执行时NDV > runtime_filter_max_in_num,则将在执行器自动关闭In filter。一般情况下,不建议用户将该值设置过大,因为在Build表NDV很大的情况下,In Filter的效果不如Bloom Filter。
系统变量3:runtime_filter_wait_time_ms。
Probe端等待Runtime Filter到达的最大等待时间默认10ms,当Runtime Filter到达后,Probe再吐数据。如果超过runtime_filter_wait_time_ms还未到达,则进入by pass阶段,此时不经Runtime Filter过滤直接开始吐数据;当某个时刻Runtime Filter达到后,Runtime Filter仍然会被启用并执行过滤。一般情况下,该值不需要调整,当实际使用Bloom Filter数据很大,且如果知道过滤性比较好的情况下,可以适当调大该值。
系统变量4:runtime_bloom_filter_max_size。
限制Bloom Filter的最大长度默认2048MB。当用户实际使用中build表的数据过多时,默认的Bloom Filter的最大长度将不能容纳数据,会导致Bloom Filter误判率增加,此时需要调大runtime_bloom_filter_max_size以降低其误判率,提高其过滤性。
OceanBasev4.2 Runtime Filter特性
OceanBase自3.1版本以来,支持了Join Bloom Filter用于在Join中执行器扫描数据时快速过滤数据,在4.0版本中,对于Join键为分区列或者分区列前缀场景支持了Partition Bloom FIlter动态过滤分区,之后又在4.1版本支持了多发Bloom Filter使相邻DFO和单个DFO内部均可生成多对Bloom Filter。
在OceanBase的4.2版本中,Join Filter能力再次扩充,在TPCH/TPCDS等场景中进一步获得性能提升,并将其统一称为Runtime Filter(RF)。具体来说,OceanBase的4.2版本新增了以下能力:
- Global Runtime Filter,支持跨DFO计划中任意位置下压Runtime Filter。区别于之前版本中只能支持相邻DFO和DFO内部传输Runtime Filter,Global Runtime Filter可以在复杂的星形连接中完成横跨CTE及多个DFO下压。
- 新增In、Range类型的Runtime Filter。在Join左表Join列NDV较小的情况下, 使用In Filter可以精确过滤右侧大表数据,对于数据为数值类型且连续分布通过构建MIN/MAX的Range Filter能够在存储层尤其是列式存储结构中快速过滤数据。
注意事项
以上就是OceanBase中的Runtime Filter能力及其在4.2版本的优化细节。需要注意的是,当Hash Join的过滤性不足时,使用Runtime Filter并不能解决问题,反而可能会导致轻微性能下降。因此,在选择手动开启Runtime Filter的时候,需要对查询场景进行仔细评估,以确定Runtime Filter是否适用。




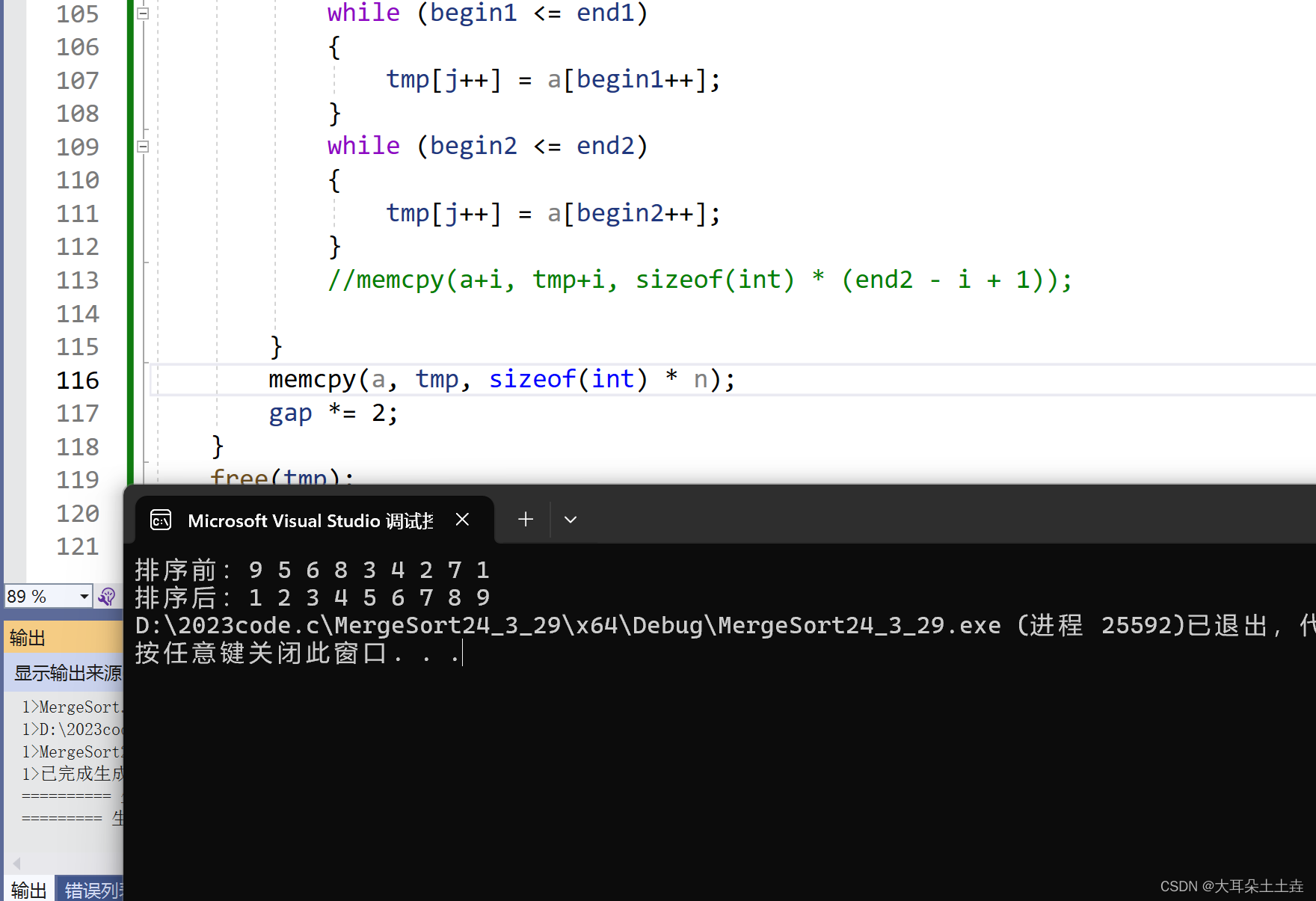


![[蓝桥杯嵌入式]hal库 stm32 (DMA串口1收发,采用空闲中断方法)](https://img-blog.csdnimg.cn/direct/1cff8adac53d461c9fba70c0cdc6cecd.png)