面试 JVM 八股文十问十答第三期
作者:程序员小白条,个人博客
相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新!
⭐点赞⭐收藏⭐不迷路!⭐
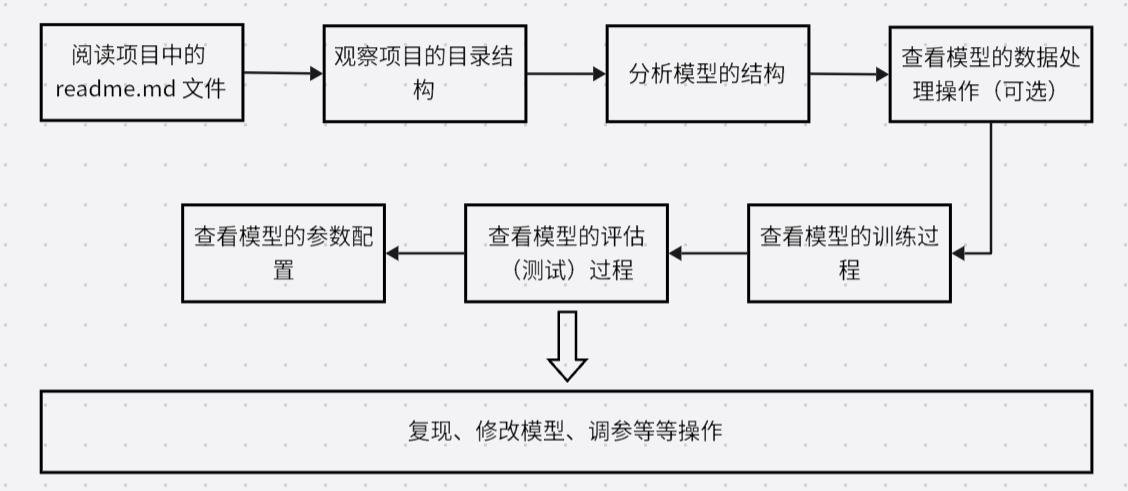
1)说一下 JVM 的主要组成部分及其作用?
- 类加载器(ClassLoader):负责将字节码文件加载到内存中,并生成对应的Class对象。
- 运行时数据区(Runtime Data Area):包括方法区、堆、虚拟机栈、本地方法栈和程序计数器等。
- 执行引擎(Execution Engine):负责执行字节码指令。
- 垃圾回收器(Garbage Collector):负责自动回收不再使用的对象,释放内存空间。
- JIT编译器(Just-In-Time Compiler):将热点代码(频繁执行的代码)编译成本地机器码,提高执行效率。
- Java Native Interface(JNI):提供了与本地语言(如C、C++)交互的接口。
- 本地方法库(Native Method Libraries):包含了与操作系统相关的一些本地方法的实现。
2)说一下 JVM 运行时数据区
- 方法区(Method Area):用于存储类的结构信息、常量池、静态变量等。
- 堆(Heap):用于存储对象实例,是JVM管理的最大一块内存区域。
- 虚拟机栈(VM Stack):用于存储方法调用的局部变量、方法参数、返回值等。
- 本地方法栈(Native Method Stack):与虚拟机栈类似,但是为本地方法服务。
- 程序计数器(Program Counter):用于记录当前线程执行的字节码指令位置。
- 运行时常量池(Runtime Constant Pool):存放编译期生成的各种字面量和符号引用。
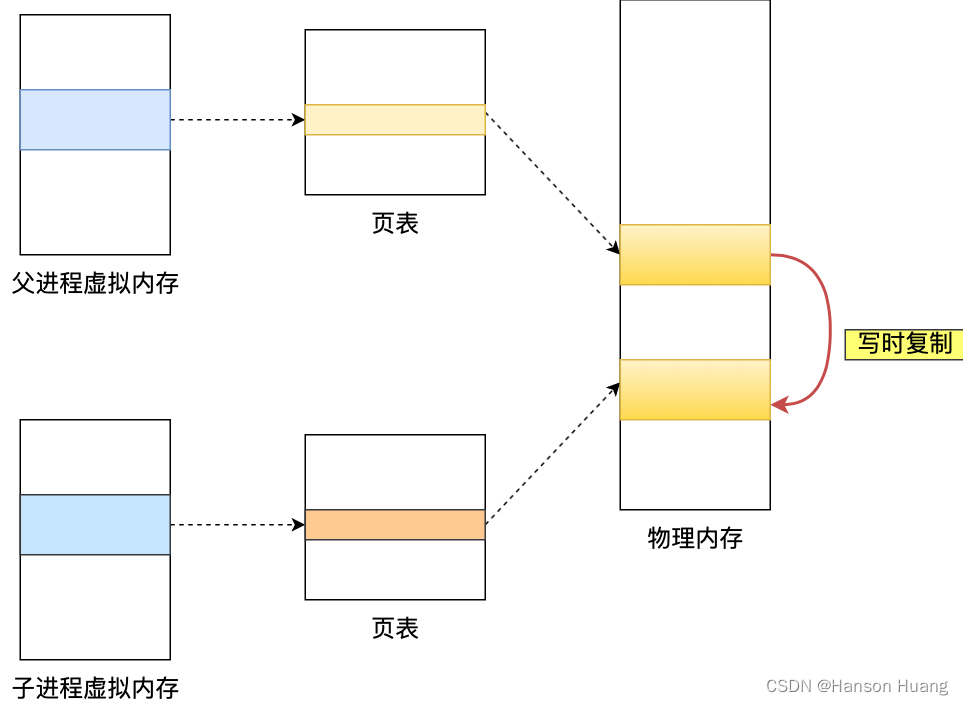
3)深拷贝和浅拷贝
- 深拷贝(Deep Copy):在拷贝对象时,不仅复制对象本身,还会递归复制对象引用的所有对象,使得拷贝后的对象与原对象完全独立。
- 浅拷贝(Shallow Copy):在拷贝对象时,只复制对象本身,而不会复制对象引用的其他对象,拷贝后的对象与原对象共享引用对象。
深拷贝和浅拷贝的区别在于是否复制对象引用的其他对象。深拷贝可以避免对象之间的相互影响,每个对象都拥有独立的数据副本,但是拷贝过程较为复杂和耗时。而浅拷贝则只是简单地复制对象本身,对象之间仍然共享引用对象,容易导致对象之间的数据冲突。
在Java中,可以通过实现Cloneable接口并重写clone()方法来实现对象的浅拷贝,或者使用序列化和反序列化来实现对象的深拷贝。另外,也可以通过手动复制对象的属性来实现深拷贝。
4)说一下堆栈的区别?
- 堆(Heap)是一块用于存储对象实例的内存区域,由JVM动态分配和管理。堆的大小可以通过启动参数进行调整。堆中的对象可以被所有线程访问,是线程共享的。
- 栈(Stack)是一块用于存储方法调用的局部变量、方法参数、返回值等的内存区域。每个线程都有自己的栈,栈的大小是固定的。栈中的数据只能被所属线程访问,是线程私有的。
堆和栈的区别主要体现在以下几个方面:
- 内存管理:堆由JVM动态分配和回收,栈由编译器自动分配和回收。
- 大小和生命周期:堆的大小可以通过启动参数调整,生命周期较长;栈的大小是固定的,生命周期与线程相对应,方法调用结束后,栈中的数据会被自动释放。
- 对象存储:堆存储对象实例,对象可以被多个线程访问;栈存储局部变量等方法调用相关的数据,只能被所属线程访问。
- 内存分配方式:堆采用动态分配,对象的创建和销毁由JVM负责;栈采用静态分配,方法的调用和返回由编译器控制。
5)队列和栈是什么?有什么区别?
- 队列(Queue)是一种先进先出(First-In-First-Out,FIFO)的数据结构,类似于排队的概念。新元素被插入到队列的尾部,而从队列中取出元素时,总是从队列的头部开始取出。
- 栈(Stack)是一种后进先出(Last-In-First-Out,LIFO)的数据结构,类似于一摞盘子。新元素被压入栈的顶部,而从栈中取出元素时,总是从栈的顶部开始取出。
区别:
- 插入和删除方式:队列采用先进先出的方式,插入元素在队尾,删除元素在队头;栈采用后进先出的方式,插入和删除元素都在栈顶。
- 元素访问顺序:队列按照插入顺序访问元素,先插入的元素先被访问;栈按照插入顺序的逆序访问元素,后插入的元素先被访问。
- 应用场景:队列常用于实现消息队列、任务调度等场景,栈常用于实现函数调用、表达式求值等场景。
- 数据结构:队列可以用数组或链表实现,栈也可以用数组或链表实现。
6)对象的创建
在Java中,对象的创建主要有以下几个步骤:
- 分配内存:根据对象的类型,分配一块连续的内存空间。
- 初始化:对分配的内存空间进行初始化,设置对象的初始值。
- 执行构造函数:调用对象的构造函数,进行进一步的初始化操作。
- 返回对象引用:将对象的引用返回给调用者,以便后续对对象的操作。
在创建对象时,可以使用关键字new来实例化一个对象,例如ClassName obj = new ClassName()。在实例化对象时,会调用对象的构造函数进行初始化。构造函数可以有多个重载形式,用于满足不同的对象初始化需求。对象的创建和初始化是在堆中进行的,而对象的引用则存储在栈中。
7)为对象分配内存
在Java中,对象的内存分配是由JVM自动完成的。当使用关键字new创建一个对象时,JVM会在堆中分配一块连续的内存空间来存储对象的数据。JVM会根据对象的类型和大小来确定分配的内存大小,并进行对象的初始化。
8)处理并发安全问题
并发安全问题是指在多线程环境下,多个线程对共享资源进行读写操作时可能出现的数据不一致或不正确的情况。为了处理并发安全问题,可以采取以下几种方式:
- 使用同步机制:通过使用
synchronized关键字或ReentrantLock等锁机制来保证同一时间只有一个线程访问共享资源,从而避免数据竞争和并发冲突。 - 使用原子操作类:Java提供了一些原子操作类,如
AtomicInteger、AtomicLong等,它们提供了线程安全的原子操作,可以避免多线程并发操作时的数据不一致问题。 - 使用线程安全的集合类:Java提供了一些线程安全的集合类,如
ConcurrentHashMap、CopyOnWriteArrayList等,它们在多线程环境下可以安全地进行读写操作。
9)对象的访问定位
在Java中,对象的访问定位是通过对象的引用来实现的。当创建一个对象时,会在堆中分配内存,并返回一个指向该对象的引用。通过引用,可以访问对象的属性和方法。引用可以存储在栈中,也可以存储在堆中的其他对象中。
10)内存溢出异常
内存溢出异常(OutOfMemoryError)是指在程序运行过程中,申请的内存超出了JVM所能分配的内存大小,导致无法继续分配内存空间的异常。内存溢出异常通常发生在以下情况:
- 创建过多的对象:如果程序中频繁创建大量的对象,并且没有及时释放,就会导致内存溢出。
- 递归调用导致栈溢出:如果程序中出现无限递归调用,每次递归都会占用一部分栈空间,当栈空间耗尽时,就会导致栈溢出。
- 内存泄漏:如果程序中存在内存泄漏的情况,即对象不再使用但没有被正确释放,就会导致内存溢出。
处理内存溢出异常的方法包括:
- 检查代码中的对象创建和销毁,确保及时释放不再使用的对象。
- 增加JVM的堆内存大小,可以通过调整启动参数来增加堆内存大小。
- 优化程序逻辑,减少对象的创建和占用的内存空间。
- 使用内存分析工具,定位内存泄漏的问题,并进行修复。
开源项目地址:https://gitee.com/falle22222n-leaves/vue_-book-manage-system
前后端总计已经 900+ Star,1.5W+ 访问!
⭐点赞⭐收藏⭐不迷路!⭐