接上篇文章yolov8逐步分解(1)--默认参数&超参配置文件加载继续讲解。
1. 默认配置文件加载完成后,创建对象trainer时,需要从默认配置中获取类DetectionTrainer初始化所需的参数args,如下所示
def train(cfg=DEFAULT_CFG, use_python=False):"""Train and optimize YOLO model given training data and device."""model = cfg.model or 'yolov8n.pt'data = cfg.data or 'coco128.yaml' # or yolo.ClassificationDataset("mnist")device = cfg.device if cfg.device is not None else ''args = dict(model=model, data=data, device=device)if use_python:from ultralytics import YOLOYOLO(model).train(**args)else:trainer = DetectionTrainer(overrides=args) #初始化训练器trainer.train()通过debug可以看到,如下所示,args值为指定模型和数据集

2. 使用上一步中获取的参数args,创建并初始化一个目标检测训练器trainer
trainer = DetectionTrainer(overrides=args)3. DetectionTrainer类的初始化代码如下,下面我们将逐步讲解。
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):"""Initializes the BaseTrainer class.Args:cfg (str, optional): Path to a configuration file. Defaults to DEFAULT_CFG.overrides (dict, optional): Configuration overrides. Defaults to None.对配置文件/训练数据文件参数进行加载,关键信息判断处理解析,保证文件存在,不存在则下载等合法性检测,及值的初始化化操作"""self.args = get_cfg(cfg, overrides) #将overrides中的配置与cfg中的配置融合,返回SimpleNameSpace类型self.device = select_device(self.args.device, self.args.batch) #选择运行在CPU/GPU还是苹果推出的MPS库上self.check_resume() #判断是否基于之前的断点继续训练,如果是,则加载之前保存的数据参数self.validator = Noneself.model = Noneself.metrics = Noneself.plots = {}init_seeds(self.args.seed + 1 + RANK, deterministic=self.args.deterministic) #初始化随机数# Dirs 创建运行结果保存额目录及文件:创建本次训练的目录/ weights保存目录 /保存运行参数project = self.args.project or Path(SETTINGS['runs_dir']) / self.args.task #project: runs/detectname = self.args.name or f'{self.args.mode}' #name: 'train'if hasattr(self.args, 'save_dir'): #判断是否设置保存路径 ,如果没有则根据项目和任务名穿件保存目录self.save_dir = Path(self.args.save_dir)else:self.save_dir = Path(increment_path(Path(project) / name, exist_ok=self.args.exist_ok if RANK in (-1, 0) else True))self.wdir = self.save_dir / 'weights' # weights dir #runs/detect/train72/weighhtsif RANK in (-1, 0):self.wdir.mkdir(parents=True, exist_ok=True) # make dirself.args.save_dir = str(self.save_dir)yaml_save(self.save_dir / 'args.yaml', vars(self.args)) # save run args #保存运行参数self.last, self.best = self.wdir / 'last.pt', self.wdir / 'best.pt' # checkpoint pathsself.save_period = self.args.save_period #保存周期#设置 epoch次数 和 batch的大小self.batch_size = self.args.batchself.epochs = self.args.epochsself.start_epoch = 0if RANK == -1:print_args(vars(self.args))# Deviceif self.device.type == 'cpu':self.args.workers = 0 # faster CPU training as time dominated by inference, not dataloading# Model and Dataset 初始化模型文件 和数据集self.model = self.args.model #yolov8n.pttry:if self.args.task == 'classify': #分类任务self.data = check_cls_dataset(self.args.data)elif self.args.data.endswith('.yaml') or self.args.task in ('detect', 'segment'): #检测和分割任务self.data = check_det_dataset(self.args.data) #加载数据yaml文件,进行关键属性值检测,并进行路径转换,确保数据集文件存在,不存在则下载if 'yaml_file' in self.data:self.args.data = self.data['yaml_file'] # for validating 'yolo train data=url.zip' usageexcept Exception as e:raise RuntimeError(emojis(f"Dataset '{clean_url(self.args.data)}' error ❌ {e}")) from eself.trainset, self.testset = self.get_dataset(self.data) #初始化训练集测试集参数 获取路径self.ema = None# Optimization utils initself.lf = None #损失函数self.scheduler = None #学习率调整策略# Epoch level metrics 指标self.best_fitness = Noneself.fitness = Noneself.loss = None #当前损失值self.tloss = None #总损失值self.loss_names = ['Loss']self.csv = self.save_dir / 'results.csv'self.plot_idx = [0, 1, 2]# Callbacksself.callbacks = _callbacks or callbacks.get_default_callbacks()if RANK in (-1, 0):callbacks.add_integration_callbacks(self)3.1 self.args = get_cfg(cfg, overrides) 该行主要实现功能为:
将默认配置参数从Simplenamespace转为字典后与overrides中的参数合并更新,进行一些参数的合法性检测后,再转换为Simplenamespace格式输出。
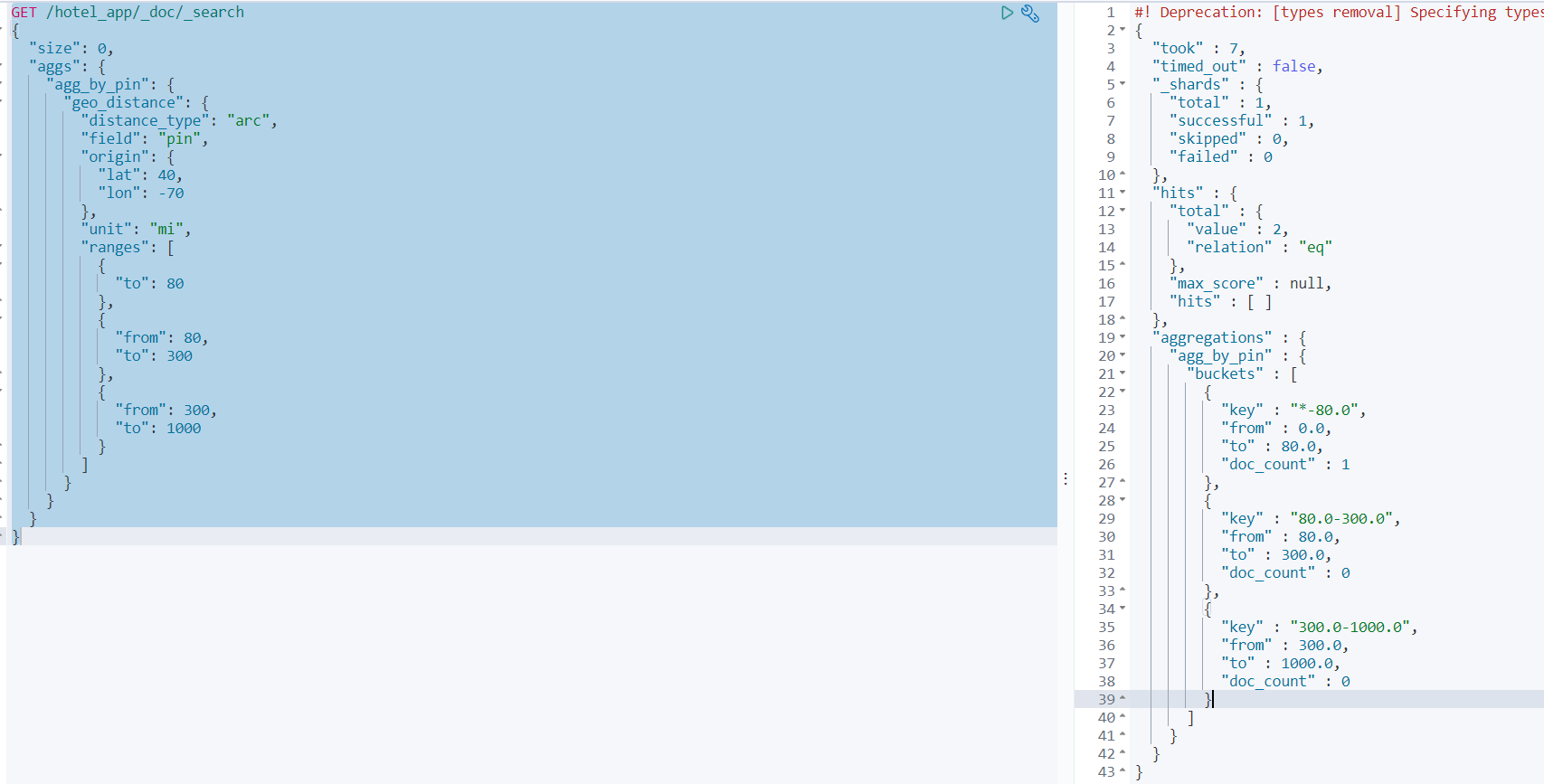
overrides该参数主要是用于更新默认加载的配置文件中model和data的值,默认配置中上述值均为None,如下图所示:
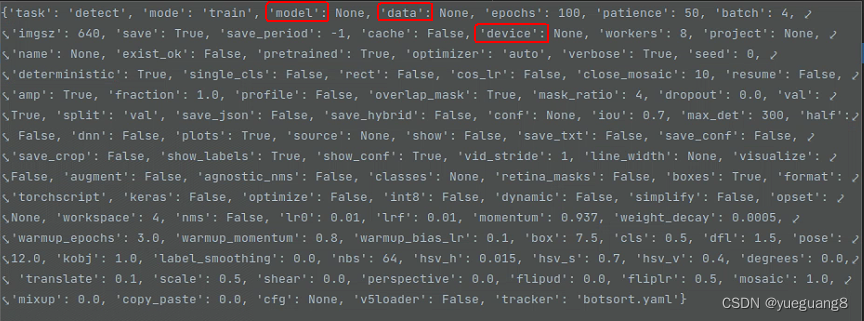
更新后的配置如下图所示:

3.2 self.device = select_device(self.args.device, self.args.batch) 功能为:
选择算法运行在CPU还是GPU上,参数batch用于检测设置的batch数值是否是GPU个数的整数倍,若不是整数倍则报错。
3.3 self.check_resume() :判断是否基于之前的断点继续训练,如果是,则加载之前保存的数据参数,本次默认配置参数该值为False.

3.4 接下来创建运行时的文件保存目录,包括本次训练的权重文件保存目录,并保存训练使用的参数以及checkPoint路径等。
# Dirs 创建运行结果保存目录及文件:创建本次训练的目录/ weights保存目录 /保存运行参数project = self.args.project or Path(SETTINGS['runs_dir']) / self.args.task #project: runs/detectname = self.args.name or f'{self.args.mode}' #name: 'train'if hasattr(self.args, 'save_dir'): #判断是否设置保存路径 ,如果没有则根据项目和任务名创建保存目录self.save_dir = Path(self.args.save_dir)else:self.save_dir = Path(increment_path(Path(project) / name, exist_ok=self.args.exist_ok if RANK in (-1, 0) else True))self.wdir = self.save_dir / 'weights' # weights dir #runs/detect/train72/weighhtsif RANK in (-1, 0):self.wdir.mkdir(parents=True, exist_ok=True) # make dirself.args.save_dir = str(self.save_dir)yaml_save(self.save_dir / 'args.yaml', vars(self.args)) # save run args #保存运行参数self.last, self.best = self.wdir / 'last.pt', self.wdir / 'best.pt' # checkpoint pathsself.save_period = self.args.save_period #保存周期3.5 初始化batch/epoch等参数,这个一目了然,不在解释
3.6 初始化数据集(coco128.yaml),步骤如下:
3.6.1 检测传入的数据集参数’dataset’是否是yaml结尾文件
3.6.2 若是路径并且是压缩格式,则下载数据集配置文件
3.6.3 加载coco128.yaml,通过函数yaml_load()加载
def check_det_dataset(dataset, autodownload=True):"""Download, check and/or unzip dataset if not found locally."""data = check_file(dataset) #dataset: coco128.yaml #判断文件是否合法,如果不存在在下载,或者从本地搜索# Download (optional)extract_dir = ''if isinstance(data, (str, Path)) and (zipfile.is_zipfile(data) or is_tarfile(data)): #判断数据集是否时zip or tar压缩格式 #new_dir = safe_download(data, dir=DATASETS_DIR, unzip=True, delete=False, curl=False)data = next((DATASETS_DIR / new_dir).rglob('*.yaml'))extract_dir, autodownload = data.parent, False# Read yaml (optional)if isinstance(data, (str, Path)):data = yaml_load(data, append_filename=True) # dictionary #读取数据集yam文件 simplenamespace格式# Checks 必要参数检测for k in 'train', 'val':if k not in data: #如果数据中既不包含 train也不包含 val,则报错raise SyntaxError(emojis(f"{dataset} '{k}:' key missing ❌.\n'train' and 'val' are required in all data YAMLs."))if 'names' not in data and 'nc' not in data:raise SyntaxError(emojis(f"{dataset} key missing ❌.\n either 'names' or 'nc' are required in all data YAMLs."))if 'names' in data and 'nc' in data and len(data['names']) != data['nc']:raise SyntaxError(emojis(f"{dataset} 'names' length {len(data['names'])} and 'nc: {data['nc']}' must match."))if 'names' not in data: #如果没有names则,用数字代替data['names'] = [f'class_{i}' for i in range(data['nc'])]else:data['nc'] = len(data['names'])data['names'] = check_class_names(data['names']) #检测data['names']是否是dict,以及将key转换为数字# Resolve pathspath = Path(extract_dir or data.get('path') or Path(data.get('yaml_file', '')).parent) # dataset rootif not path.is_absolute():path = (DATASETS_DIR / path).resolve() #转化为绝对路径data['path'] = path # download scriptsfor k in 'train', 'val', 'test': #全部转换为绝对路径if data.get(k): # prepend pathif isinstance(data[k], str):x = (path / data[k]).resolve()if not x.exists() and data[k].startswith('../'):x = (path / data[k][3:]).resolve()data[k] = str(x)else:data[k] = [str((path / x).resolve()) for x in data[k]]# Parse yamltrain, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))if val:val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val pathif not all(x.exists() for x in val): #不存在则下载name = clean_url(dataset) # dataset name with URL auth strippedm = f"\nDataset '{name}' images not found ⚠️, missing paths %s" % [str(x) for x in val if not x.exists()]if s and autodownload:LOGGER.warning(m)else:m += f"\nNote dataset download directory is '{DATASETS_DIR}'. You can update this in '{SETTINGS_YAML}'"raise FileNotFoundError(m)t = time.time()if s.startswith('http') and s.endswith('.zip'): # URLsafe_download(url=s, dir=DATASETS_DIR, delete=True)r = None # successelif s.startswith('bash '): # bash scriptLOGGER.info(f'Running {s} ...')r = os.system(s)else: # python scriptr = exec(s, {'yaml': data}) # return Nonedt = f'({round(time.time() - t, 1)}s)'s = f"success ✅ {dt}, saved to {colorstr('bold', DATASETS_DIR)}" if r in (0, None) else f'failure {dt} ❌'LOGGER.info(f'Dataset download {s}\n')check_font('Arial.ttf' if is_ascii(data['names']) else 'Arial.Unicode.ttf') # download fontsreturn data # dictionary其中,data = yaml_load(data, append_filename=True)加载完成后,data内容如下:
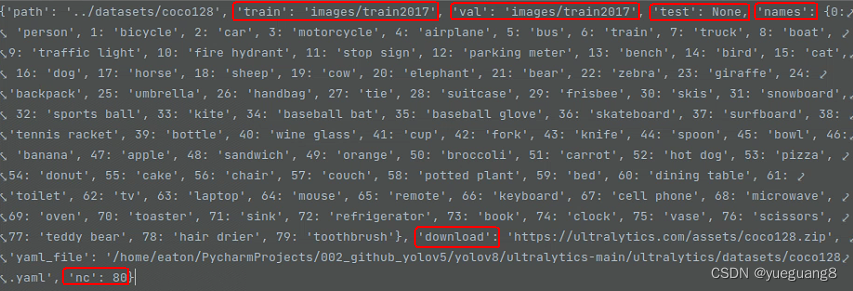
注意:’nc’:80 是通过 data['nc'] = len(data['names']) 后添加的。
3.6.4 将data中的路径全部转换为绝对路径
for k in 'train', 'val', 'test': #全部转换为绝对路径if data.get(k): # prepend pathif isinstance(data[k], str):x = (path / data[k]).resolve()if not x.exists() and data[k].startswith('../'):x = (path / data[k][3:]).resolve()data[k] = str(x)else:data[k] = [str((path / x).resolve()) for x in data[k]]转换完成并更新data后,data的内容如下,其中train,val,test等键的值变为了绝对路径:
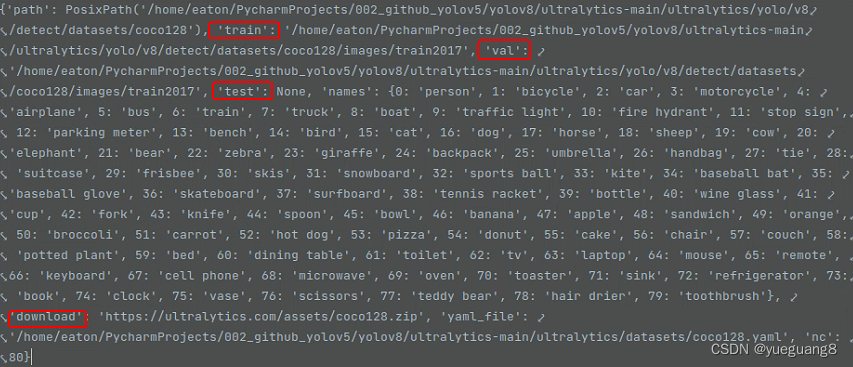
3.6.5 获取训练集、测试集、验证集、以及下载路径
train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))3.6.6 最終返回data,数据类型为字典,完成对coco128.yaml文件的加载解析及校验工作。
3.7 获取训练集和验证集的路径
self.trainset, self.testset = self.get_dataset(self.data) #初始化训练集测试集参数 获取路径
其中,获取路径方法函数实现过程如下:
def get_dataset(data):"""Get train, val path from data dict if it exists. Returns None if data format is not recognized."""return data['train'], data.get('val') or data.get('test')3.8 其他学习率、损失函数等都设置为None
self.ema = None# Optimization utils initself.lf = None #损失函数self.scheduler = None #学习率调整策略# Epoch level metrics 指标self.best_fitness = Noneself.fitness = Noneself.loss = None #当前损失值self.tloss = None #总损失值self.loss_names = ['Loss']self.csv = self.save_dir / 'results.csv'self.plot_idx = [0, 1, 2]3.9 设置用于结果展示获取的一些回调函数
# Callbacksself.callbacks = _callbacks or callbacks.get_default_callbacks()if RANK in (-1, 0):callbacks.add_integration_callbacks(self)至此,trainer的初始化过程解析完成。
总结,本章详细介绍了yolov8训练器trainer的初始化过程,讲解参数的加载替换过程,着重讲解了coco128数据集的加载解析及校验,最后介绍了损失函数学习率的初始化。