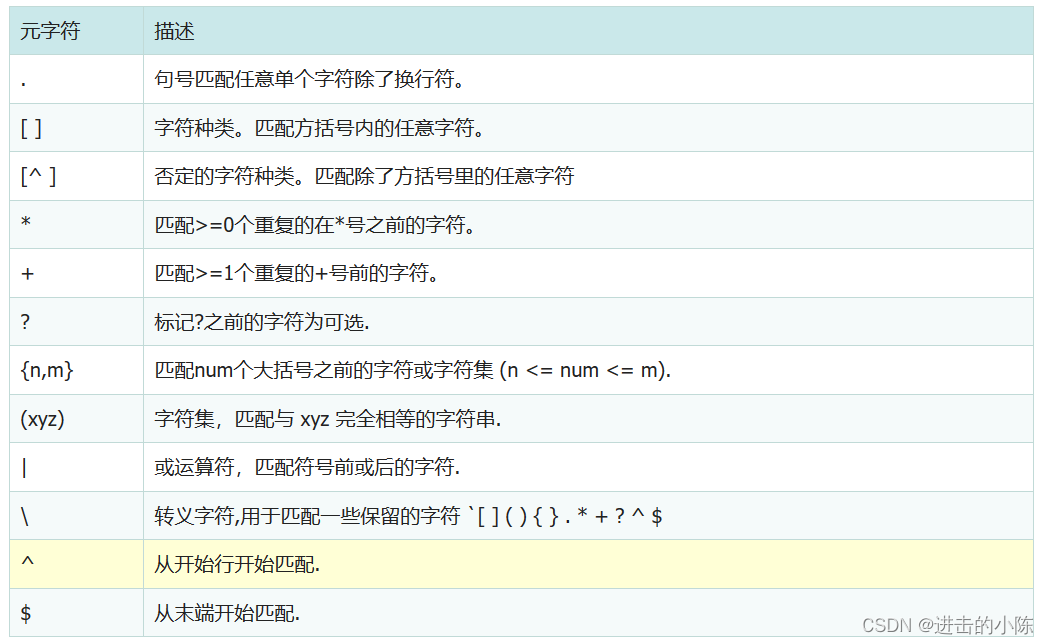
目录
词云简介
准备工作
安装方法一:
安装方法二:
生成词云步骤
数据预处理:
分词:
统计词频出现的次数:
去除词语:
生成词云:
显示词云:
保存词云:
完整代码
词云简介
“词云”这个概念由美国西北大学新闻学副教授、新媒体专业主任里奇·戈登(Rich Gordon)于提出,词云是一种可视化描绘单词或词语出现在文本数据中频率的方式,它主要是由随机分布在词云图的单词或词语构成,出现频率较高的单词或词语则会以较大的形式呈现出来,而频率越低的单词或词语则会以较小的形式呈现。词云主要提供了一种观察社交媒体网站上的热门话题或搜索关键字的一种方式,它可以对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。

准备工作
我们需要安装一些基本的库:(因为wordcloud库,jieba库不是python的内置库)
- wordcloud
- jieba
安装方法一:
windows+R,打开cmd,在命令行输入:
pip install wordcloud等待安装完成即可。同样的方法安装jieba库;
安装方法二:
直接再pycharm软件中安装:
打开pycharm,找到pythong软件包,在搜索框中搜索要下载的库,点击安装即可。
(如果第一次安装失败的话,直接再次尝试安装,基本上第二次是可以成功的)。

生成词云步骤
- 准备好文本数据,词云背景模板;
- 数据预处理:对文本数据处理,如去除标点符号,停用词,数字等,以便更好的生成词云图;
- 分词:文本数据处理好后,使用分词工具进行分词,也就是将词分成一个个词语;
- 统计词频:也就是统计每个词语出现的次数;
- 去除不想要的词语;
- 生成词云图:使用wordcloud库的函数生成词云图,设置一些背景颜色,字体,词云形状;
- 显示词云图;
- 保存词云图;
数据预处理:
file = open(r"test.txt", mode="r",encoding="utf-8")
txt1 = file.read()txt2 = re.sub(r"[^\u4e00-\u9fa5]","",txt1)
- 这里file是打开文件的操作:如果直接print(file),结果显示的也只是一个操作,不会显示文本内容;要想真正的把文本里面的内容读取出来,就需要file.read()的方法;
- txt1中存放的就是原始文本,但是只是原始文本并不行,使用re库中的re.sub将文本中的标点进行匹配,替换成空白,优化好的文本我们放到txt2中;
这里re.sub()函数可以看:re.sub()用法的详细介绍_jackandsnow的博客-CSDN博客_re sub
分词:
我们平常看到的词云:
如果整个文本直接生成词云肯定是不行的,接下来我们就需要对文本进行分词操作;
txt3 = jieba.cut(txt2) # 可迭代对象#for i in txt3:
# print(i)这里我们就用到了准备工作中的jieba库:
jieba.cut(s) 精确模式:把文本精确的切分开,不存在冗余单词;
这样txt3中的保存的就是一个个的词语:

统计词频出现的次数:
txt4 = {}
for i in txt3:if i not in txt4:txt4[i]=1else:txt4[i]+=1txt5 = sorted(txt4.items(),key=lambda x :x[1],reverse=True)txt6={}
for word,count in txt5:txt6[word]=count这里我们把结果存放到字典里面,因为{key:value},可以存放值和出现次数;
存放好后,我们进行排序;
- sorted函数是默认升序排序,当需要降序排序时,需要使用reverse = Ture;
- 这里的items是将txt4字典转换为一个列表;
我们排好序后,还需要将这个列表转换为一个字典;
去除词语:
统计并排好词后我们打印一下:

如果里面有不想出现的词语,可以把它删去:
list1={'的','和','我','我们','会','可以','是','我会','例如'} #去除不想要的词语
for i in list1:del txt6[i]生成词云:
img =Image.open("R-C.jpg")//我们想要的词云模板导入img_array = np.array(img)wordcloud = WordCloud(mask=img_array, # 设置词云模板background_color='white', #背景颜色font_path='simsun.ttc', #字体路径max_words=500, #最大显示的单词数max_font_size=100, #单词最大字号width = 500, #宽度height= 500, #高度
).generate_from_frequencies(txt6)显示词云:
plt.Figure(figsize=(8,8)) #画布大小
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off') #关闭坐标轴
plt.show()保存词云:
wordcloud.to_file('词云图片.jpg') # 保存图片完整代码
import re
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
import numpy as np
from PIL import Imagefile = open(r"test.txt", mode="r",encoding="utf-8")
txt1 = file.read()
# print(txt1) #原始文本
txt2 = re.sub(r"[^\u4e00-\u9fa5]","",txt1)
# print(txt2) #进化后的文本txt3 = jieba.cut(txt2) # 可迭代对象
# for i in txt3:
# print(i)txt4 = {}
for i in txt3:if i not in txt4:txt4[i]=1else:txt4[i]+=1
txt5 = sorted(txt4.items(),key=lambda x :x[1],reverse=True)
# print(txt5)txt6={}
for word,count in txt5:txt6[word]=count
print(txt6)list1={'的','和','我','我们','会','可以','是','我会','例如'} #去除不想要的词语
for i in list1:del txt6[i]
# print(txt6)img =Image.open("R-C.jpg")img_array = np.array(img)wordcloud = WordCloud(mask=img_array, # 设置词云模板background_color='white', #背景颜色font_path='simsun.ttc', #字体路径max_words=500, #最大显示的单词数max_font_size=100, #单词最大字号width = 500, #宽度height= 500, #高度
).generate_from_frequencies(txt6)
plt.Figure(figsize=(8,8)) #画布大小
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off') #关闭坐标轴
plt.show()
wordcloud.to_file('词云图片.jpg') # 保存图片完结!!