jdk8中Arrays.sort
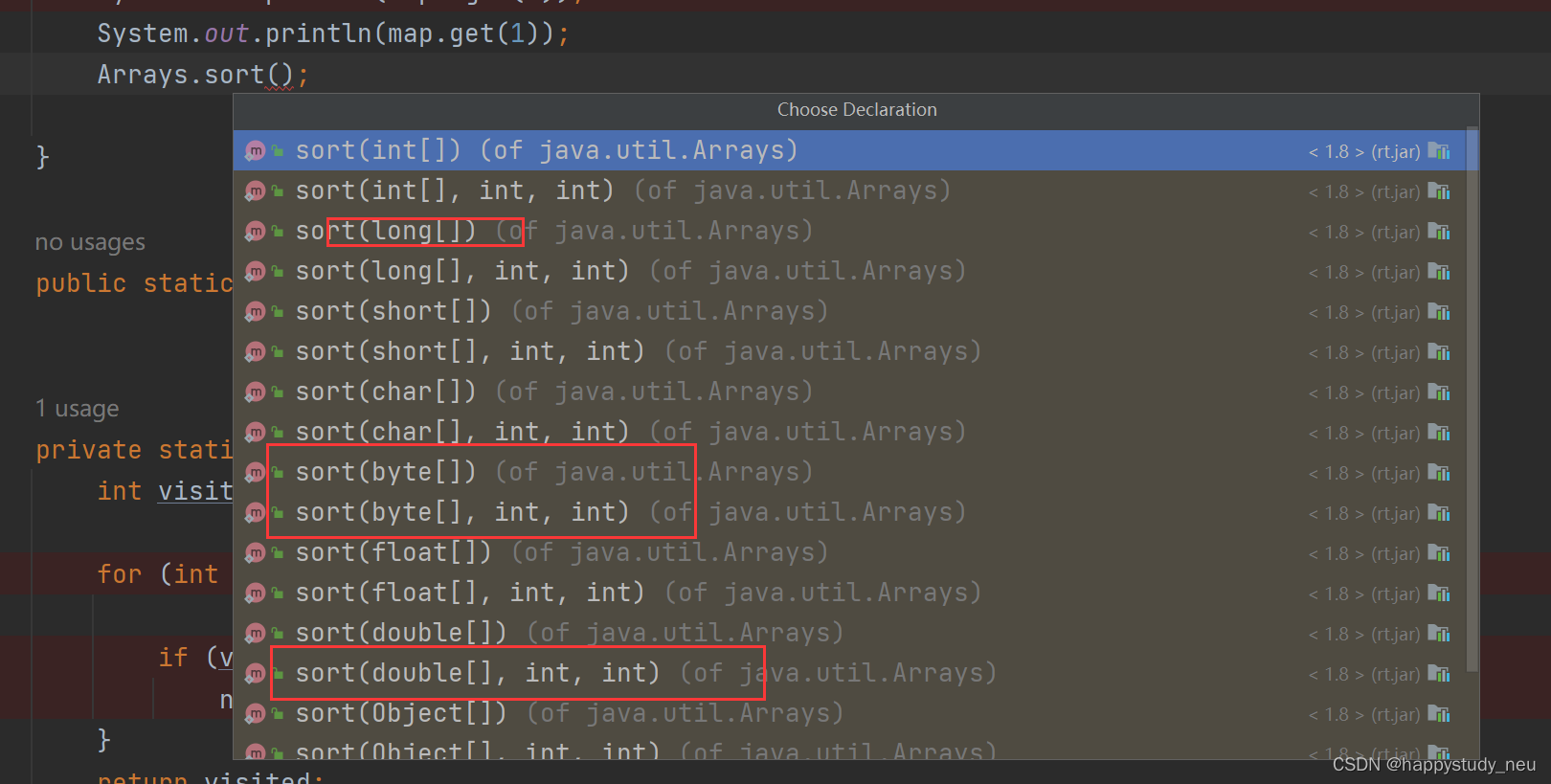
这里可以看到根据传入数组类型的不同,排序的算法是由区别的。
拆分解析
我们在平时引用的时候,一般只会传入一个数组,但是真正调用的时候,参数会进行补全。
public static void sort(int[] a) {DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);}/*** Sorts the specified range of the array into ascending order. The range* to be sorted extends from the index {@code fromIndex}, inclusive, to* the index {@code toIndex}, exclusive. If {@code fromIndex == toIndex},* the range to be sorted is empty.** <p>Implementation note: The sorting algorithm is a Dual-Pivot Quicksort* by Vladimir Yaroslavskiy, Jon Bentley, and Joshua Bloch. This algorithm* offers O(n log(n)) performance on many data sets that cause other* quicksorts to degrade to quadratic performance, and is typically* faster than traditional (one-pivot) Quicksort implementations.** @param a the array to be sorted* @param fromIndex the index of the first element, inclusive, to be sorted* @param toIndex the index of the last element, exclusive, to be sorted** @throws IllegalArgumentException if {@code fromIndex > toIndex}* @throws ArrayIndexOutOfBoundsException* if {@code fromIndex < 0} or {@code toIndex > a.length}*/public static void sort(int[] a, int fromIndex, int toIndex) {rangeCheck(a.length, fromIndex, toIndex);DualPivotQuicksort.sort(a, fromIndex, toIndex - 1, null, 0, 0);}
Arrays.sort里面的排序是灵活的,选取条件一般是传入数组的类型,数组的长度,包括数组的有序度进行判断,然后来选择排序。
一般他会先对这个数组的合法进行一个检查。
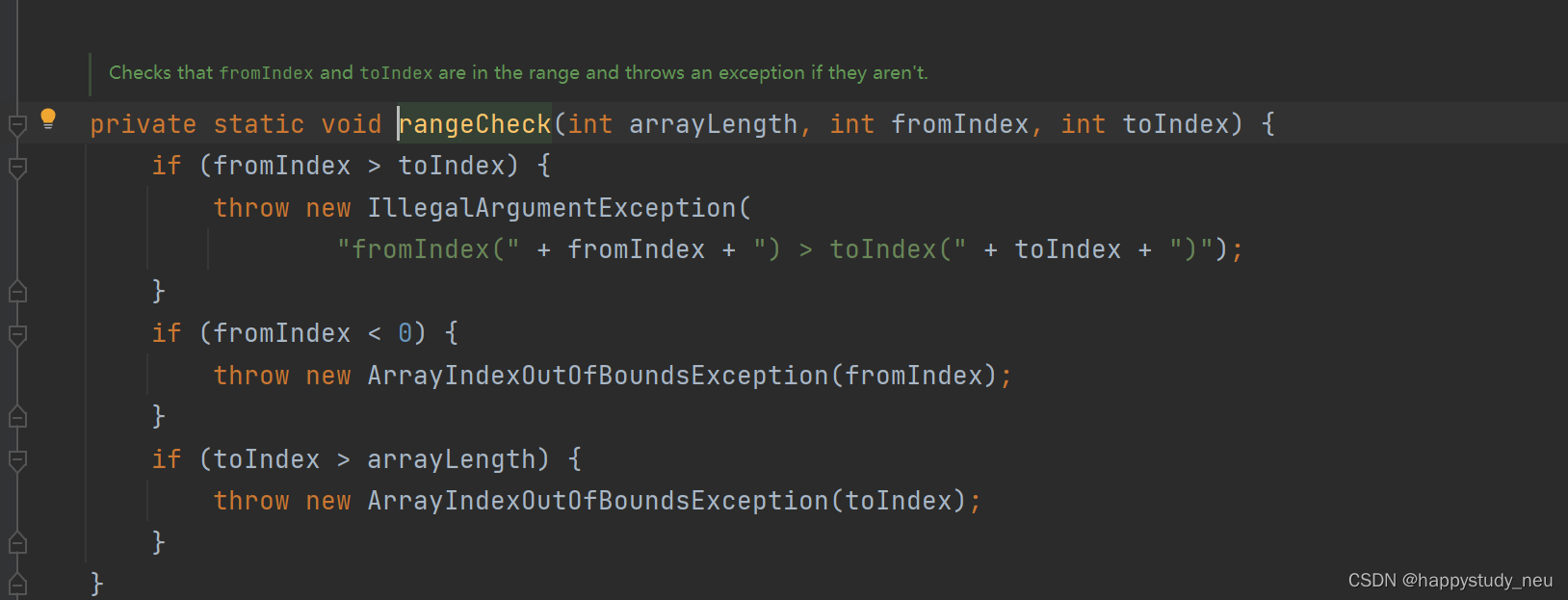
这里我们以int的为例子
可以看到排序代码为:
static void sort(int[] a, int left, int right,int[] work, int workBase, int workLen) {// Use Quicksort on small arraysif (right - left < QUICKSORT_THRESHOLD) {sort(a, left, right, true);return;}/** Index run[i] is the start of i-th run* (ascending or descending sequence).*/int[] run = new int[MAX_RUN_COUNT + 1];int count = 0; run[0] = left;// Check if the array is nearly sortedfor (int k = left; k < right; run[count] = k) {if (a[k] < a[k + 1]) { // ascendingwhile (++k <= right && a[k - 1] <= a[k]);} else if (a[k] > a[k + 1]) { // descendingwhile (++k <= right && a[k - 1] >= a[k]);for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) {int t = a[lo]; a[lo] = a[hi]; a[hi] = t;}} else { // equalfor (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k]; ) {if (--m == 0) {sort(a, left, right, true);return;}}}/** The array is not highly structured,* use Quicksort instead of merge sort.*/if (++count == MAX_RUN_COUNT) {sort(a, left, right, true);return;}}// Check special cases// Implementation note: variable "right" is increased by 1.if (run[count] == right++) { // The last run contains one elementrun[++count] = right;} else if (count == 1) { // The array is already sortedreturn;}// Determine alternation base for mergebyte odd = 0;for (int n = 1; (n <<= 1) < count; odd ^= 1);// Use or create temporary array b for mergingint[] b; // temp array; alternates with aint ao, bo; // array offsets from 'left'int blen = right - left; // space needed for bif (work == null || workLen < blen || workBase + blen > work.length) {work = new int[blen];workBase = 0;}if (odd == 0) {System.arraycopy(a, left, work, workBase, blen);b = a;bo = 0;a = work;ao = workBase - left;} else {b = work;ao = 0;bo = workBase - left;}// Mergingfor (int last; count > 1; count = last) {for (int k = (last = 0) + 2; k <= count; k += 2) {int hi = run[k], mi = run[k - 1];for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) {if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) {b[i + bo] = a[p++ + ao];} else {b[i + bo] = a[q++ + ao];}}run[++last] = hi;}if ((count & 1) != 0) {for (int i = right, lo = run[count - 1]; --i >= lo;b[i + bo] = a[i + ao]);run[++last] = right;}int[] t = a; a = b; b = t;int o = ao; ao = bo; bo = o;}}比较疑惑的地方就在于,他是如何进行长度判断的,又是如何检测数组的有序性的,是在排序前还是排序中呢,如果在排序后才知道数组是否有序,就没有意义了。
这里看源码
逻辑从上往下看:
第一步先以数组的长度为判断条件:
计算数组的长度容易:
直接right-left就可以了
那么这里的quicksort_threshold就是一个阈值
static void sort(int[] a, int left, int right,int[] work, int workBase, int workLen) {// Use Quicksort on small arraysif (right - left < QUICKSORT_THRESHOLD) {sort(a, left, right, true);return;}我们可以先看一下常量值:
Max_Run_Count是衡量有序性的,MAX_RUN_LENGTH是衡量重复重复元素的。
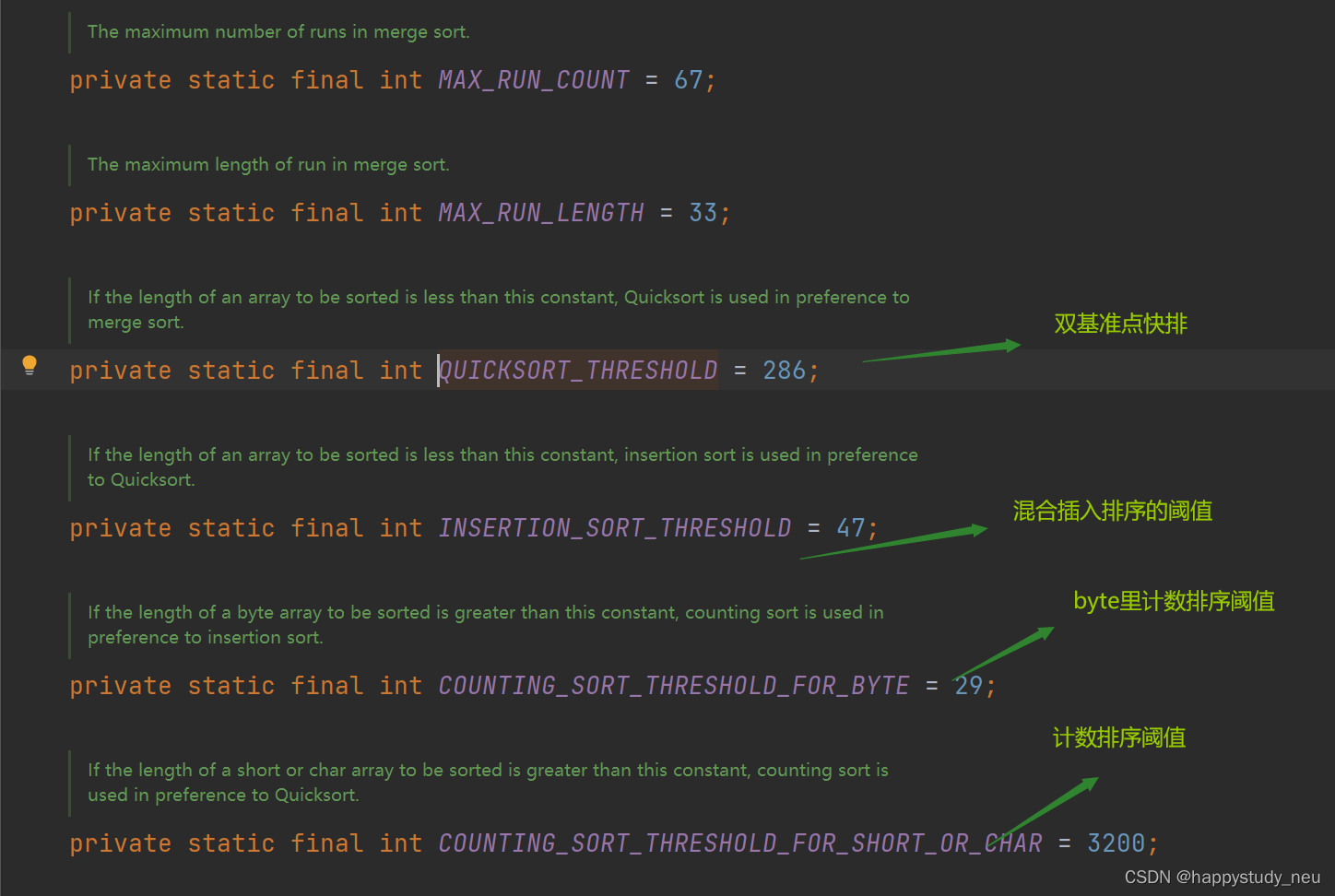
再回头看的话可以知道这个代码是长度小于这个286就直接采用双基准点快排了。
那么如果大于这个值呢?接着往下看
/** Index run[i] is the start of i-th run* (ascending or descending sequence).*/int[] run = new int[MAX_RUN_COUNT + 1];int count = 0; run[0] = left;run用来记录记录升序或者降序的起点
// Check if the array is nearly sorted
for (int k = left; k < right; run[count] = k) {// 循环遍历数组中的元素,k 从左边界开始逐步向右移动if (a[k] < a[k + 1]) { // ascending// 如果当前元素小于下一个元素,说明当前区间是递增的while (++k <= right && a[k - 1] <= a[k]);// 继续移动 k 直到找到递增区间的结束位置} else if (a[k] > a[k + 1]) { // descending// 如果当前元素大于下一个元素,说明当前区间是递减的while (++k <= right && a[k - 1] >= a[k]);// 继续移动 k 直到找到递减区间的结束位置// 然后反转递减区间,将递减区间转换为递增区间for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) {int t = a[lo]; a[lo] = a[hi]; a[hi] = t;// 交换递减区间中的元素,实现反转}} else { // equal// 如果当前元素等于下一个元素,说明当前区间是相等的for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k]; ) {// 继续移动 k 直到找到不相等的元素或者达到最大相等长度if (--m == 0) {// 如果重复元素超过阈值,算法会尝试通过不同的分区策略来处理。这些策略旨在提高排序的效率,尽可能地减少重复元素对排序性能的影响,这里的sort还需要进行源码查看,比较复杂。sort(a, left, right, true);return;}}}/** The array is not highly structured,* use Quicksort instead of merge sort.*/// 如果发现数组不是高度结构化的,即当前区间并不是递增或递减的if (++count == MAX_RUN_COUNT) {// 如果累积的 run 数达到了最大值sort(a, left, right, true);// 则认为数组无序,使用快速排序进行排序return;}
}
、
这段代码是来判断这个区间的有序度。
count值越多,说明这个越无序,如果无序的话,那么采用快排来进行排序。
否则接着往下看
if (run[count] == right++) { // The last run contains one element 这段代码在检查最后一个 run 是否只包含一个元素。run[count] 表示当前记录的最后一个 run 的起始索引位置。如果这个 run 的起始索引位置与 right 相等,即最后一个 run 只包含一个元素,那么 right++ 会使 right 增加 1,这是因为 right 之前可能已经增加过 1。然后 run[++count] = right; 将新的右边界 right 记录到 run 数组中,表示这个 run 的结束位置。这样做的目的是为了确保 run 数组中的所有 run 都是左闭右开的区间。
第二个是cout值没有发生变化,已经排好序了,直接返回即可。
if (run[count] == right++) { // The last run contains one elementrun[++count] = right;} else if (count == 1) { // The array is already sortedreturn;}那么最后一段代码则是归并排序了
// Determine alternation base for mergebyte odd = 0;for (int n = 1; (n <<= 1) < count; odd ^= 1);// Use or create temporary array b for mergingint[] b; // temp array; alternates with aint ao, bo; // array offsets from 'left'int blen = right - left; // space needed for bif (work == null || workLen < blen || workBase + blen > work.length) {work = new int[blen];workBase = 0;}if (odd == 0) {System.arraycopy(a, left, work, workBase, blen);b = a;bo = 0;a = work;ao = workBase - left;} else {b = work;ao = 0;bo = workBase - left;}// Mergingfor (int last; count > 1; count = last) {for (int k = (last = 0) + 2; k <= count; k += 2) {int hi = run[k], mi = run[k - 1];for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) {if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) {b[i + bo] = a[p++ + ao];} else {b[i + bo] = a[q++ + ao];}}run[++last] = hi;}if ((count & 1) != 0) {for (int i = right, lo = run[count - 1]; --i >= lo;b[i + bo] = a[i + ao]);run[++last] = right;}int[] t = a; a = b; b = t;int o = ao; ao = bo; bo = o;}数量大于快排阈值并且有序度比较高的情况会用到归并。
小总结
那么这里举了int的分析例子,最后附上一个参考表格。
| 排序目标 | 条件 | 采用算法 |
|---|---|---|
| int[] long[] float[] double[] | size < 47 | 混合插入排序 (pair) |
| size < 286 | 双基准点快排 | |
| 有序度低 | 双基准点快排 | |
| 有序度高 | 归并排序 | |
| byte[] | size <= 29 | 插入排序 |
| size > 29 | 计数排序 | |
| char[] short[] | size < 47 | 插入排序 |
| size < 286 | 双基准点快排 | |
| 有序度低 | 双基准点快排 | |
| 有序度高 | 归并排序 | |
| size > 3200 | 计数排序 | |
| Object[] | -Djava.util.Arrays.useLegacyMergeSort=true | 传统归并排序 |
| TimSort |
其中 TimSort 是用归并+二分插入排序的混合排序算法