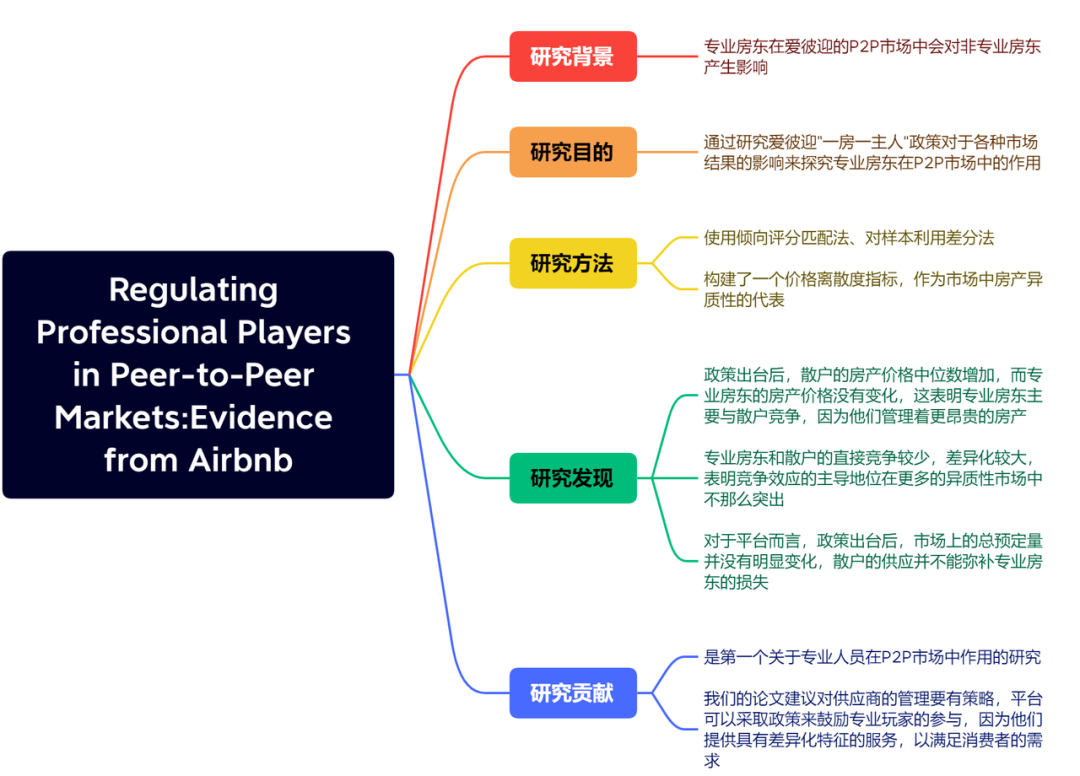
因为内核内存需要节省着用,内核处理内存分配错误比较麻烦等,所以内核中获取内存不用户空间获取内存复杂得多。
本章讨论内核是如何管理内存和内核之中获取内存的办法。
12.1页
a)
可以通过 getconf 命令来查看系统的page的大小:
[wangyubin@localhost ]$ getconf -a | grep -i 'page'
PAGESIZE 4096
PAGE_SIZE 4096
_AVPHYS_PAGES 637406
_PHYS_PAGES 2012863
4096(Byte) =2^12(Byte) = 4(Kilobyte),以上的 PAGESIZE 就是当前机器页大小,即 4KB
b)
页的结构体头文件是: <linux/mm_types.h> 位置:include/linux/mm_types.h
/** 页中包含的成员非常多,还包含了一些联合体* 其中有些字段我暂时还不清楚含义,以后再补上。。。*/
struct page {unsigned long flags; /* 存放页的状态,各种状态参见<linux/page-flags.h> */atomic_t _count; /* 页的引用计数 */union {atomic_t _mapcount; /* 已经映射到mms的pte的个数 */struct { /* 用于slab层 */u16 inuse;u16 objects;};};union {struct {unsigned long private; /* 此page作为私有数据时,指向私有数据 */struct address_space *mapping; /* 此page作为页缓存时,指向关联的address_space */};
#if USE_SPLIT_PTLOCKSspinlock_t ptl;
#endifstruct kmem_cache *slab; /* 指向slab层 */struct page *first_page; /* 尾部复合页中的第一个页 */};union {pgoff_t index; /* Our offset within mapping. */void *freelist; /* SLUB: freelist req. slab lock */};struct list_head lru; /* 将页关联起来的链表项 */
#if defined(WANT_PAGE_VIRTUAL)void *virtual; /* 页的虚拟地址 */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGSunsigned long debug_flags; /* Use atomic bitops on this */
#endif#ifdef CONFIG_KMEMCHECK/** kmemcheck wants to track the status of each byte in a page; this* is a pointer to such a status block. NULL if not tracked.*/void *shadow;
#endif
};
c)
硬件MMU:管理内存并把虚拟地址转换为物理地址。
大多数32位体系结构支持4KB的页,而大多数64位系统结构支持8KB。
内核用struct page描述硅制物理内存,不描述内存中的数据。通过struct page可以知道一个页是否空闲,即struct page用于管理页的使用。
page->_count存放页的引用计数,page->_count的值为-1表示内核没有引用此页。
struct page占40字节,一个物理内存4GB、物理页大小为8KB系统共有页面524288个。描述所有页面的struct page总共消耗20MB内存,管理代价不高。
12.2区
a)
页是内存管理的最小单元,但是并不是所有的页对于内核都一样。为了方便管理与使用,内核根据特性对页进行分组。
内核将内存按地址的顺序分成了不同的区,有的硬件只能访问有专门的区。
x86-32系统结构相对简单只是分为了三个区:
| 区 | 描述 | 物理内存 |
|---|---|---|
| ZONE_DMA | DMA使用的页 | <16MB |
| ZONE_NORMAL | 正常可寻址的页 | 16~896MB |
| ZONE_HIGHMEM | 动态映射的页 | >896MB |
b)
Linux把系统的页划分为区,形成不同的内存池,这样就可以根据用途进行分配,但是分配不能跨区界限。
当然,内核更希望一般用途的内存从常规区分配,这样节省ZONE_DMA中的页,保证正真需要DMA时,ZONE_DMA中剩余页足够分配。
c)
内核中的分区定义在头文件 <linux/mmzone.h> ,头文件位置:include/linux/mmzone.h
内存区的种类参见 enum zone_type 中的定义。
内存区的结构体定义也在 <linux/mmzone.h> 中,具体参考其中 struct zone 的定义。
12.3获得页
内核提供了一种请求内存的底层机制,并提供了对它进行访问的几个接口:
void *page_address(struct page *page)//把给定物理页转化成它的逻辑地址,返回一个指针,指向它的逻辑地址struct page* alloc_pages(gfp_t gfp_mask, unsigned int order)//分配 2^order 个页,返回指向第一页页结构的指针
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)//分配 2^order 个页,返回指向第一页逻辑地址的指针struct page *alloc_page(gfp_t gfp_mask)//只分配一页,返回指向页结构的指针
unsigned long __get_free_page(gfp_t gfp_mask)//只分配一页,返回指向其逻辑地址的指针
alloc** 方法和 get** 方法的区别在于,一个返回的是内存的物理地址,一个返回内存物理地址映射后的逻辑地址。
如果无须直接操作物理页结构体的话,一般使用 get** 方法。
1)获得填充为零的页
分配页时,页中数据是随机产生的垃圾信息,但是,有可能其中包含有某些敏感数据,所以特别是分配给用户空间页,就需要将页填充为0。保障系统安全。
unsigned long get_zeroed_page(unsigned int gfp_mask)//只分配一页,并将分配好的页都填充为0。返回指向其逻辑地址的指针
2)释放页
相应的释放内存的函数如下:也是在 <linux/gfp.h> 中定义的
extern void __free_pages(struct page *page, unsigned int order);
extern void free_pages(unsigned long addr, unsigned int order);
extern void free_hot_page(struct page *page);
12.4kmalloc()
kmalloc的定义在 <linux/slab_def.h> 中
void *kmalloc(size_t size, gfp_t flags)
//kmalloc 分配的内存物理地址是连续的,虚拟地址也是连续的,返回的是连续地址的首地址。
// 第 2 个参数, 分配标志,内部最终通过调用 __get_free_pages 来进行,即对应 __get_free_pages 的参数gfp_mask
1) gfp_mask 标志
在请求内存时,参数中有个 gfp_mask 标志,这个标志是控制分配内存时必须遵守的一些规则。
gfp_mask 标志有3类:(所有的 GFP 标志都在 <linux/gfp.h> 中定义)
行为标志 :控制分配内存时,分配器的一些行为
区标志 :控制内存分配在那个区(ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM 之类)
类型标志 :由上面2种标志组合而成的一些常用的场景
行为标志主要有以下几种:
| 行为标志 | 描述 |
|---|---|
| __GFP_WAIT | 分配器可以睡眠 |
| __GFP_HIGH | 分配器可以访问紧急事件缓冲池 |
| __GFP_IO | 分配器可以启动磁盘I/O |
| __GFP_FS | 分配器可以启动文件系统I/O |
| __GFP_COLD | 分配器应该使用高速缓存中快要淘汰出去的页 |
| __GFP_NOWARN | 分配器将不打印失败警告 |
| __GFP_REPEAT | 分配器在分配失败时重复进行分配,但是这次分配还存在失败的可能 |
| __GFP_NOFALL | 分配器将无限的重复进行分配。分配不能失败 |
| __GFP_NORETRY | 分配器在分配失败时不会重新分配 |
| __GFP_NO_GROW | 由slab层内部使用 |
| __GFP_COMP | 添加混合页元数据,在 hugetlb 的代码内部使用 |
区标志主要以下3种:
| 区标志 | 描述 |
|---|---|
| __GFP_DMA | 从 ZONE_DMA 分配 |
| __GFP_DMA32 | 只在 ZONE_DMA32 分配 (注1) |
| __GFP_HIGHMEM | 从 ZONE_HIGHMEM 或者 ZONE_NORMAL 分配 (注2) |
注1:ZONE_DMA32 和 ZONE_DMA 类似,该区包含的页也可以进行DMA操作。
唯一不同的地方在于,ZONE_DMA32 区的页只能被32位设备访问。
注2:优先从 ZONE_HIGHMEM 分配,如果 ZONE_HIGHMEM 没有多余的页则从 ZONE_NORMAL 分配。
类型标志是编程中最常用的,在使用标志时,应首先看看类型标志中是否有合适的,如果没有,再去自己组合 行为标志和区标志。
| 类型标志 | 实际标志 | 描述 |
|---|---|---|
| GFP_ATOMIC | __GFP_HIGH | 这个标志用在中断处理程序,下半部,持有自旋锁以及其他不能睡眠的地方 |
| GFP_NOWAIT | 0 | 与 GFP_ATOMIC 类似,不同之处在于,调用不会退给紧急内存池。 这就增加了内存分配失败的可能性 |
| GFP_NOIO | __GFP_WAIT | 这种分配可以阻塞,但不会启动磁盘I/O。 这个标志在不能引发更多磁盘I/O时能阻塞I/O代码,可能会导致递归 |
| GFP_NOFS | (__GFP_WAIT | __GFP_IO) | 这种分配在必要时可能阻塞,也可能启动磁盘I/O,但不会启动文件系统操作。 这个标志在你不能再启动另一个文件系统的操作时,用在文件系统部分的代码中 |
| GFP_KERNEL | (__GFP_WAIT | __GFP_IO | __GFP_FS ) | 这是常规的分配方式,可能会阻塞。这个标志在睡眠安全时用在进程上下文代码中。 为了获得调用者所需的内存,内核会尽力而为。这个标志应当为首选标志 |
| GFP_USER | (__GFP_WAIT | __GFP_IO | __GFP_FS ) | 这是常规的分配方式,可能会阻塞。用于为用户空间进程分配内存时 |
| GFP_HIGHUSER | (__GFP_WAIT | __GFP_IO | __GFP_FS )|__GFP_HIGHMEM) | 从 ZONE_HIGHMEM 进行分配,可能会阻塞。用于为用户空间进程分配内存 |
| GFP_DMA | __GFP_DMA | 从 ZONE_DMA 进行分配。需要获取能供DMA使用的内存的设备驱动程序使用这个标志。通常与以上的某个标志组合在一起使用。 |
以上各种类型标志的使用场景总结:
| 场景 | 相应标志 |
|---|---|
| 进程上下文,可以睡眠 | 使用 GFP_KERNEL |
| 进程上下文,不可以睡眠 | 使用 GFP_ATOMIC,在睡眠之前或之后以 GFP_KERNEL 执行内存分配 |
| 中断处理程序 | 使用 GFP_ATOMIC |
| 软中断 | 使用 GFP_ATOMIC |
| tasklet | 使用 GFP_ATOMIC |
| 需要用于DMA的内存,可以睡眠 | 使用 (GFP_DMA|GFP_KERNEL) |
| 需要用于DMA的内存,不可以睡眠 | 使用 (GFP_DMA|GFP_ATOMIC),或者在睡眠之前执行内存分配 |
2)Kfree()
kmalloc 和 vmalloc 所对应的释放内存的方法分别为:
void kfree(const void *)
void vfree(const void *)
12.5vmalloc()
vmalloc通过分配非连续的物理内存块,再“修改”页表,把内存映射到逻辑地址空间的连续区域中。
虽然一般必须要物理连续的内存的是硬件,但是使用vmalloc需要专门建立页表项,影响性能,最终我们基本都用kmalloc()来获得内存。
kmalloc的定义在 <linux/slab_def.h> 中
void *vmalloc(unsigned long size)//vmalloc 分配的内存物理地址是不连续的,虚拟地址是连续的
kmalloc 和 vmalloc 所对应的释放内存的方法分别为:
void kfree(const void *)
void vfree(const void *)
12.6slab层
高速缓存:硬件高速缓存的容量大,访问速度接近于CPU的速度(CPU的时钟频率)。CPU可以直接向高速缓存中存取数据,从而减少了时间,提高了系统的运行速度。
空闲链表:空闲链表包含可供使用的、已经分配好的数据结构块。当代码需要一个新的数据结构实例时,就可以从空闲链表中抓取一个,而不需要请求分配内存。使用完放回空闲链表,而不是释放它。
分配和释放数据结构是所有内核普遍的操作之一。为了便于数据的频繁分配和回收,编程人员常常会用到空闲链表。
CPU访问高速缓存快于访问内存,从空闲链表提取放回内存快于从内核请求释放内存。
1)slab层的设计
高速缓存:硬件高速缓存的容量大,访问速度接近于CPU的速度(CPU的时钟频率)。CPU可以直接向高速缓存中存取数据,从而减少了时间,提高了系统的运行速度。
空闲链表:空闲链表包含可供使用的、已经分配好的数据结构块。当代码需要一个新的数据结构实例时,就可以从空闲链表中抓取一个,而不需要请求分配内存。使用完放回空闲链表,而不是释放它。
分配和释放数据结构是所有内核普遍的操作之一。为了便于数据的频繁分配和回收,编程人员常常会用到空闲链表。
CPU访问高速缓存快于访问内存,从空闲链表提取放回内存快于从内核请求释放内存。
slab分配器扮演着通用数据结构缓存层的角色。
linux中的高速缓存是用所谓 slab 层来实现的,slab层即内核中管理高速缓存的机制。
整个slab层的原理如下:
可以在内存中建立各种对象的高速缓存(比如进程描述相关的结构 task_struct 的高速缓存)
除了针对特定对象的高速缓存以外,也有通用对象的高速缓存
每个高速缓存中包含多个 slab,slab用于管理缓存的对象
slab中包含多个缓存的对象,物理上由一页或多个连续的页组成
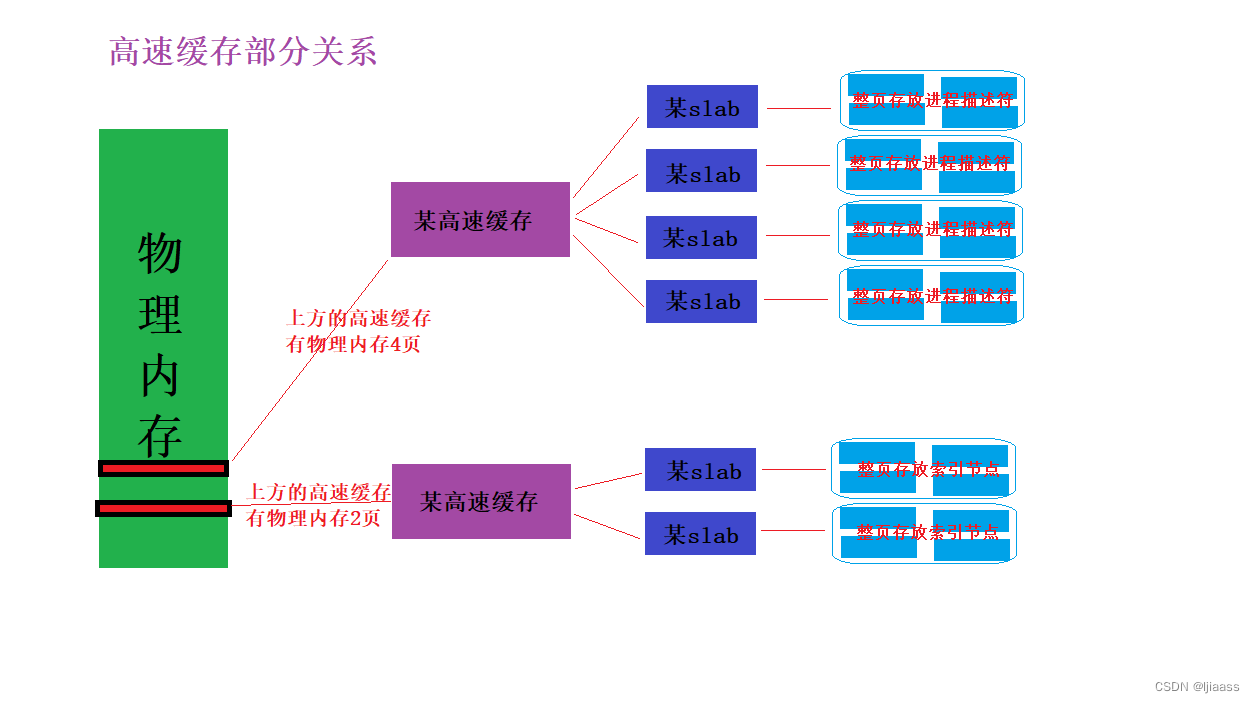
2)slab分配器的接口
slab结构体的定义参见:mm/slab.c
struct slab {struct list_head list; /* 存放缓存对象,这个链表有 满,部分满,空 3种状态 */unsigned long colouroff; /* slab 着色的偏移量 */void *s_mem; /* 在 slab 中的第一个对象 */unsigned int inuse; /* slab 中已分配的对象数 */kmem_bufctl_t free; /* 第一个空闲对象(如果有的话) */unsigned short nodeid; /* 应该是在 NUMA 环境下使用 */
};
slab层的使用主要有四个方面:
高速缓存的创建
从高速缓存中分配对象
向高速缓存释放对象
高速缓存的销毁
/*** 创建高速缓存* 参见文件: mm/slab.c* 这个函数的注释很详细,这里就不多说了。*/
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,unsigned long flags, void (*ctor)(void *))/*** 从高速缓存中分配对象也很简单* 函数参见文件:mm/slab.c* @cachep - 指向高速缓存指针* @flags - 之前讨论的 gfp_mask 标志,只有在高速缓存中所有slab都没有空闲对象时,* 需要申请新的空间时,这个标志才会起作用。** 分配成功时,返回指向对象的指针*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)/*** 向高速缓存释放对象* @cachep - 指向高速缓存指针* @objp - 要释放的对象的指针*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)/*** 销毁高速缓存* @cachep - 指向高速缓存指针 */
void kmem_cache_destroy(struct kmem_cache *cachep)
3)尝试使用slab分配器的接口
我做了创建高速缓存的例子,来尝试使用上面的几个函数。
测试代码如下:(其中用到的 kn_common.h 和 kn_common.c 参见之前的博客《Linux内核设计与实现》读书笔记(六)- 内核数据结构)
#include <linux/slab.h>
#include <linux/slab_def.h>
#include "kn_common.h"MODULE_LICENSE("Dual BSD/GPL");#define MYSLAB "testslab"static struct kmem_cache *myslab;/* 申请内存时调用的构造函数 */
static void ctor(void* obj)
{printk(KERN_ALERT "constructor is running....\n");
}struct student
{int id;char* name;
};static void print_student(struct student *);static int testslab_init(void)
{struct student *stu1, *stu2;/* 建立slab高速缓存,名称就是宏 MYSLAB */myslab = kmem_cache_create(MYSLAB,sizeof(struct student),0,0,ctor);//创建高速缓存MYSLAB(#define MYSLAB "testslab")/* 高速缓存中分配2个对象 */printk(KERN_ALERT "alloc one student....\n");stu1 = (struct student*)kmem_cache_alloc(myslab, GFP_KERNEL);//从高速缓存myslab中分配对象stu1->id = 1;stu1->name = "wyb1";print_student(stu1);printk(KERN_ALERT "alloc one student....\n");stu2 = (struct student*)kmem_cache_alloc(myslab, GFP_KERNEL);stu2->id = 2;stu2->name = "wyb2";print_student(stu2);/* 释放高速缓存中的对象 */printk(KERN_ALERT "free one student....\n");kmem_cache_free(myslab, stu1);//向高速缓存myslab释放对象stu1printk(KERN_ALERT "free one student....\n");kmem_cache_free(myslab, stu2);//向高速缓存myslab释放对象stu2/* 执行完后查看 /proc/slabinfo 文件中是否有名称为 “testslab”的缓存。(保存着监视系统中所有活动的 slab 缓存的信息的文件为/proc/slabinfo) */return 0;
}static void testslab_exit(void)
{/* 删除建立的高速缓存 */printk(KERN_ALERT "*************************\n");print_current_time(0);kmem_cache_destroy(myslab);//销毁高速缓存printk(KERN_ALERT "testslab is exited!\n");printk(KERN_ALERT "*************************\n");/* 执行完后查看 /proc/slabinfo 文件中是否有名称为 “testslab”的缓存 */
}static void print_student(struct student *stu)
{if (stu != NULL){printk(KERN_ALERT "**********student info***********\n");printk(KERN_ALERT "student id is: %d\n", stu->id);printk(KERN_ALERT "student name is: %s\n", stu->name);printk(KERN_ALERT "*********************************\n");}elseprintk(KERN_ALERT "the student info is null!!\n");
}module_init(testslab_init);//注册模块加载函数,调用函数 module_init 来声明 xxx_init 为驱动入口函数,当加载驱动的时候 xxx_init
函数就会被调用。
module_exit(testslab_exit);//注册模块卸载函数,调用函数module_exit来声明xxx_exit为驱动出口函数,当卸载驱动的时候xxx_exit
函数就会被调用。
Makefile文件如下:
# must complile on customize kernel
obj-m += myslab.o
myslab-objs := testslab.o kn_common.o#generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modulesrm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
执行测试代码:(我是在 centos6.3 x64 上实验的)
[root@vbox chap12]# make
[root@vbox chap12]# insmod myslab.ko #加载驱动文件myslab.ko,Linux 下模块扩展名为.ko。
[root@vbox chap12]# dmesg | tail -220 #平时通过insmod加载驱动文件的时候,不输出log,所以没办法看ko中输出的log,但是通过dmesg | tail 可以看到日志反馈.#保存着监视系统中所有活动的 slab 缓存的信息的文件为/proc/slabinfo[root@vbox chap12]# cat /proc/slabinfo | grep test #查看我们建立的缓存名在不在系统中。(#define MYSLAB "testslab")
testslab 0 0 16 202 1 : tunables 120 60 0 : slabdata 0 0 0
[root@vbox chap12]# rmmod myslab.ko #卸载内核模块
[root@vbox chap12]# cat /proc/slabinfo | grep test #我们的缓存名已经不在系统中了。#cat连接文件并打印到标准输出设备上。grep 命令用于查找文件里符合条件的字符串。
12.7在栈上的静态分配
内核栈小而固定
当给每个进程分配一个固定大小的栈后,不但可以减少内存的消耗,而且内核也无须负担太重的栈管理任务。
1)单页内核栈
内核栈可以在编译时配置选项,设置成4~16KB,即一页为4KB时,可以设置成1、2、3、4页。一页为8KB时,可以设置成1、2页。
历史上中断处理程序和被中断的进程共享一个栈,后可以激活1页栈选项,使中断处理程序获得自己的一页栈。
2)在栈上光明正大地工作

即静态分配内存不要超过几百字节,需要大块内存,使用动态分配。
12.8高端内存的映射
zone n.区;气候带
high adj.高的
Memory n.内存
高端内存就是之前提到的 ZONE_HIGHMEM 区的内存。
在x86体系结构中,这个区的内存不能映射到内核地址空间上,也就是没有逻辑地址,
为了使用 ZONE_HIGHMEM 区的内存,内核提供了永久映射和临时映射2种手段:
1)永久映射
永久映射的函数是可以睡眠的,所以只能用在进程上下文中。
/* 将 ZONE_HIGHMEM 区的一个page永久的映射到内核地址空间* 返回值即为这个page对应的逻辑地址*/
static inline void *kmap(struct page *page)/* 允许永久映射的数量是有限的,所以不需要高端内存时,应该及时的解除映射 */
static inline void kunmap(struct page *page)
2)临时映射
临时映射不会阻塞,也禁止了内核抢占,所以可以用在中断上下文和其他不能重新调度的地方。
/*** 将 ZONE_HIGHMEM 区的一个page临时映射到内核地址空间* 其中的 km_type 表示映射的目的,* enum kn_type 的定义参见:<asm/kmap_types.h>,它描述了临时映射的目的*/
static inline void *kmap_atomic(struct page *page, enum km_type idx)/* 相应的解除映射是个宏 */
#define kunmap_atomic(addr, idx) do { pagefault_enable(); } while (0)
以上的函数都在 <linux/highmem.h> 中定义的。
12.9每个CPU的分配
用一个数组,一项是一个CPU的数据,几个CPU就有几项。

按CPU来分配数据主要有2个优点:
最直接的效果就是减少了对数据的锁,提高了系统的性能
由于每个CPU有自己的数据,所以处理器切换时可以大大减少缓存失效的几率 (*注1)
注1:如果一个处理器操作某个数据,而这个数据在另一个处理器的缓存中时,那么存放这个数据的那个
处理器必须清理或刷新自己的缓存。持续的缓存失效成为缓存抖动,对系统性能影响很大。
12.10新的每个CPU接口
1)编译时的每个CPU数据
a)
每个CPU数据:“专用数组”的数据(用一个数组,一项是一个CPU的数据,几个CPU就有几项)。
可以在编译时就定义分配给每个CPU的变量,其分配的接口参见:<linux/percpu-defs.h>
编译时定义就是静态实现,“专用数组”个人猜测可以用宏创建。此“专用数组”正真怎么实现看源码
注意下面两个宏,一个是声明,一个是定义。
其实也就是 DECLARE_PER_CPU 中多了个 extern 的关键字
/* 给每个CPU声明一个类型为 type,名称为 name 的变量 */
DECLARE_PER_CPU(type, name)
/* 给每个CPU定义一个类型为 type,名称为 name 的变量 */
DEFINE_PER_CPU(type, name)
b)
分配好变量后,就可以在代码中使用这个变量 name 了。
DEFINE_PER_CPU(int, name); /* 为每个CPU定义一个 int 类型的name变量 */get_cpu_var(name)++; /* 当前处理器上的name变量 +1 */
put_cpu_var(name); /* 完成对name的操作后,激活当前处理器的内核抢占 */
c)
通过 get_cpu_var 和 put_cpu_var 的代码,我们可以发现其中有禁止和激活内核抢占的函数。
相关代码在 <linux/percpu.h> 中
#define get_cpu_var(var) (*({ \extern int simple_identifier_##var(void); \preempt_disable();/* 这句就是禁止当前处理器上的内核抢占 */ \&__get_cpu_var(var); }))
#define put_cpu_var(var) preempt_enable() /* 这句就是激活当前处理器上的内核抢占 */
2)运行时的每个CPU数据
除了像上面那样静态的给每个CPU分配数据,还可以以指针的方式在运行时给每个CPU分配数据。
动态分配参见:<linux/percpu.h>
/* 给每个处理器分配一个 size 字节大小的对象,对象的偏移量是 align */
extern void *__alloc_percpu(size_t size, size_t align);
/* 释放所有处理器上已分配的变量 __pdata */
extern void free_percpu(void *__pdata);/* 还有一个宏,是按对象类型 type 来给每个CPU分配数据的,* 其实本质上还是调用了 __alloc_percpu 函数 */
#define alloc_percpu(type) (type *)__alloc_percpu(sizeof(type), \__alignof__(type))
动态分配的一个使用例子如下:
void *percpu_ptr;
unsigned long *foo;percpu_ptr = alloc_percpu(unsigned long);
if (!percpu_ptr)/* 内存分配错误 */foo = get_cpu_var(percpu_ptr);
/* 操作foo ... */
put_cpu_var(percpu_ptr);
12.11使用每个CPU数据的原因
按CPU来分配数据主要有2个优点:
最直接的效果就是减少了对数据的锁,提高了系统的性能
由于每个CPU有自己的数据,所以处理器切换时可以大大减少缓存失效的几率 (*注1)
注1:如果一个处理器操作某个数据,而这个数据在另一个处理器的缓存中时,那么存放这个数据的那个
处理器必须清理或刷新自己的缓存。持续的缓存失效成为缓存抖动,对系统性能影响很大。
12.12分配函数的选择
在众多的内存分配函数中,如何选择合适的内存分配函数很重要,下面总结了一些选择的原则:
| 应用场景 | 分配函数选择 |
|---|---|
| 如果需要物理上连续的页 | 选择低级页分配器或者 kmalloc 函数 |
| 如果kmalloc分配是可以睡眠 | 指定 GFP_KERNEL 标志 |
| 如果kmalloc分配是不能睡眠 | 指定 GFP_ATOMIC 标志 |
| 如果不需要物理上连续的页 | vmalloc 函数 (vmalloc 的性能不如 kmalloc) |
| 如果需要高端内存 | alloc_pages 函数获取 page 的地址,在用 kmap 之类的函数进行映射 |
| 如果频繁撤销/创建教导的数据结构 | 建立slab高速缓存 |