分库分表实践
分库分表概念以及使用场景
分库分表用来解决单表数据量太大,引起的性能问题。使用分库分表后能够根据特定路由键值将数据分布在不同库以及不同表中,解决了单表数据量的性能、运维等问题。一般来讲,单一数据库实例的数据的阈值
在 1TB 之内,是比较合理的范围。关于mysql 单表的数据量,一般单表数据量不超过2000万,这里和B+tree有关系,具体和每行数据大小,这里的2000万是根据跟行数据是1kb的前提下算出来的,当超过2000万,叶子节点会超过三层,此时性能会受到影响。其次还有到系统、磁盘io等硬件、软件的影响。
分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,
一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。使用多主多从的分片方式,可以有效
的避免数据单点,从而提升数据架构的可用性。
数据分片一般乐可以按垂直拆分和水平擦拆分。垂直拆分是按照业务来拆分表,例如拆成订单和用户表,往往需要对架构和设计进行调整。水平拆分是对表的水平拓展,解决单表或者单库的瓶颈问题。
分库分表同样是一把双刃剑,后会带来以下的问题:
1.运维难度加大
2.分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理,例如时间聚合查询时不能像以前一样单表分页查询,对业务的带来很多场景上的不适配。解决方案一般是同步到es这种Nosql数据库中进行聚合分析查询。
3.分布式事务,多库之间的DML操作事务不一致的问题,业务上尽量需要避免,同时也需要提供就柔性事务的解决方案,强一致性解决方案性能上存在问题。
shardingjdbc
ShardingSphere‐JDBC 定位为轻量级 Java 框架,它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC和各种 ORM 框架。
全面支持 DML、DDL、DCL、TCL 和常用 DAL。支持分页、去重、排序、分组、聚合、表关联等复杂查
询。支持 PostgreSQL 和 openGauss 数据库 SCHEMA DDL 和 DML 语句。• 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接
使用 JDBC;
• 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
• 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何
可使用 JDBC 访问的数据库。
常见概念:
分片键: 数据路由字段,根据改字段落到库和表中
分片算法:对分片键进行计算得到的表架构,可以用常见的运算表达式,也可以自定义算法
分布式主键:雪花算法、Uuid等算法
springboot使用可以参考如下配置文件方式配置,配置了分库分表的分片键以及对应算法,当然也可以自定义算法。这里也用了DruidDataSource数据源,来配置shardingjdbc,并且配置了数据源的监控。
这里配置了双数据源对应两个而不同的库,然后定义了父子关系表,以及两张表的路由方式和表的主键由雪花算法生成。user_id为分库路由键,order_id为分表路由键,具体代码可以参考该项目,https://github.com/luozijing/springLearning,欢迎关注!
CREATE TABLE `pay_parent_0` (`id` bigint NOT NULL AUTO_INCREMENT,`user_id` int NOT NULL,...
) ENGINE=InnoDB AUTO_INCREMENT=1571152425171070979 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_binCREATE TABLE `pay_parent_item_1` (`id` bigint NOT NULL AUTO_INCREMENT,`order_id` bigint NOT NULL,`user_id` int NOT NULL,...
) ENGINE=InnoDB AUTO_INCREMENT=1571152424793583629 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
spring:main:allow-bean-definition-overriding: trueshardingsphere:props:sql:show: truedatasource:demo0:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://xxxxx:3306/demo0?useSSL=false&allowPublicKeyRetrieval=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=CTTusername: rootpassword: xxxtype: com.alibaba.druid.pool.DruidDataSourcemaxActive: 20min-idle: 5connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000filters: stat,wall,log4j2demo1:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://xxx:3306/demo1?useSSL=false&allowPublicKeyRetrieval=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=CTTusername: rootpassword: xxxxtype: com.alibaba.druid.pool.DruidDataSourcemaxActive: 20min-idle: 5connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000filters: stat,wall,log4j2names: demo0,demo1sharding:binding-tables: pay_parent,pay_parent_itembroadcast-tables: t_addressdefault-database-strategy:inline:algorithm-expression: demo$->{user_id % 2}sharding-column: user_idtables:pay_parent:actual-data-nodes: demo$->{0..1}.pay_parent_$->{0..1}key-generator:column: idprops:worker:id: 123type: SNOWFLAKEtable-strategy:inline:algorithm-expression: pay_parent_$->{id % 2}sharding-column: idpay_parent_item:actual-data-nodes: demo$->{0..1}.pay_parent_item_$->{0..1}key-generator:column: idprops:worker:id: 123type: SNOWFLAKEtable-strategy:inline:algorithm-expression: pay_parent_item_$->{order_id % 2}sharding-column: order_id
场景问题分析
为了模拟实际场景,模拟并发插入将近50w数据,利用这50w数据来分析实际场景中的一些聚合分析,每张表大概分到12.5w数据,说明雪花算法分布还是随机比较均匀的算法。
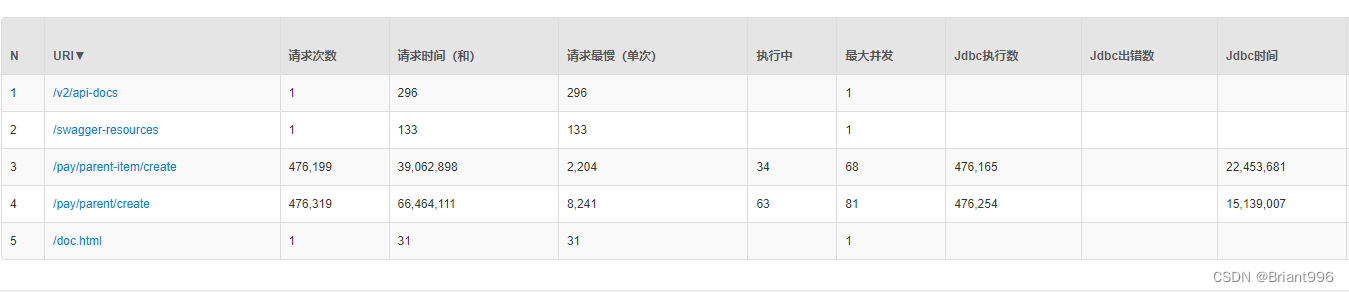
Limit分页查询
分页查询时由于不带任务路由键,所以是数据全量数据查询,然后按照主键id排序,这个效率十分低下,当带上路由键时,会路由到指定库,效率才会提升。所以在实际业务中,路由键十分重要,决定了业务的使用。
1.查询所有用户数据
SELECT COUNT(*) AS total FROM pay_parent WHERE deleted = 0
-》
Actual SQL: demo0 ::: SELECT COUNT(*) AS total FROM pay_parent_0 WHERE deleted = 0
Actual SQL: demo0 ::: SELECT COUNT(*) AS total FROM pay_parent_1 WHERE deleted = 0
Actual SQL: demo1 ::: SELECT COUNT(*) AS total FROM pay_parent_0 WHERE deleted = 0
Actual SQL: demo1 ::: SELECT COUNT(*) AS total FROM pay_parent_1 WHERE deleted = 0
各个库和各类表累加SELECT id,status,user_id,create_time,update_time,creator,updater,deleted FROM pay_parent WHERE deleted=0 ORDER BY id DESC LIMIT ?
-》
Actual SQL:SELECT id,status,user_id,create_time,update_time,creator,updater,deleted FROM pay_parent_0 WHERE deleted=0
.....2.查询指定用户数据
Actual SQL: demo0 ::: SELECT id,status,user_id,create_time,update_time,creator,updater,deleted FROM pay_parent_0 WHERE deleted=0 AND (user_id = ?) ORDER BY id DESC LIMIT ? ::: [54, 10]
Actual SQL: demo0 ::: SELECT id,status,user_id,create_time,update_time,creator,updater,deleted FROM pay_parent_1 WHERE deleted=0 AND (user_id = ?) ORDER BY id DESC LIMIT ? ::: [54, 10]
关联分页查询
两张表的关联,这里入参利用userID,数据源路由键,可以路由到具体的数据库,然后联表查询,联表时很明显由于没有路由键,这里查询的数量是笛卡尔积,效率上也是大打折扣。
Actual SQL: demo0 ::: selectl.id, l.user_id, l.status,r.id as item_id, r.order_id, r.status as item_status, r.user_id as item_user_idfrom pay_parent_1 as lleft join pay_parent_item_0 r on l.id = r.order_idwhere 1= 1and l.user_id = ? LIMIT ? ::: [56, 10]
Actual SQL: demo0 ::: selectl.id, l.user_id, l.status,r.id as item_id, r.order_id, r.status as item_status, r.user_id as item_user_idfrom pay_parent_1 as lleft join pay_parent_item_1 r on l.id = r.order_idwhere 1= 1 Actual SQL: demo0 ::: selectl.id, l.user_id, l.status,r.id as item_id, r.order_id, r.status as item_status, r.user_id as item_user_idfrom pay_parent_0 as lleft join pay_parent_item_0 r on l.id = r.order_idwhere 1= 1and l.user_id = ? LIMIT ? ::: [56, 10]Actual SQL: demo0 ::: selectl.id, l.user_id, l.status,r.id as item_id, r.order_id, r.status as item_status, r.user_id as item_user_idfrom pay_parent_0 as lleft join pay_parent_item_1 r on l.id = r.order_idwhere 1= 1and l.user_id = ? LIMIT ? ::: [56, 10]总结
在实施分库分表时,要结合实际业务的需求来制定分库分表的规则以及路由的字段。一般来说,为了保障实际业务的性能,会将路由键带入查询条件中,路由到单库单表,此中情况性能较高。其次,经过上面验证,shardingjdbc能够满足mybatis 联表查询和分页查询的适配,其中联表在没有路由键是笛卡儿积的数量,验证数据准确,在实际业务中,分库分表改造后,对现有sql的需要一一验证有效性,包括性能和准确性上,改造成本还是不小。后续还将会继续探讨分库分表相关话题。
参考
https://blog.csdn.net/Edwin_Hu/article/details/124897224?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124897224-blog-125905356.pc_relevant_multi_platform_featuressortv2dupreplace&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124897224-blog-125905356.pc_relevant_multi_platform_featuressortv2dupreplace&utm_relevant_index=1 --单表数据量 2000w
https://download.csdn.net/download/qq_17236715/86542410?spm=1001.2014.3001.5503 -ShardingSphere 中文文档