文章目录
- 1、索引介绍
- 2、索引分类
- 2.1、数据结构
- Hash
- B + Tree
- 2.2、存储方式
- 聚簇索引
- 非聚簇索引
- 2.3、功能特性
- 主键索引
- 唯一索引
- 普通索引
- 2.4、字段数量
- 单列索引
- 多列索引
- 3、最佳实践
- 3.1、索引覆盖
- 3.2、回表操作
- 3.3、最左匹配原则
- 3.4、索引下推
1、索引介绍
对于MySQL数据库来说,有个非常重要的概念就是索引,索引的用途是:
加速我们对MySQL数据库的
查询操作性能,减少磁盘IO操作。
注意这里说的是查询,而不是新增、修改、删除。索引不仅对新增、修改等操作没有性能提升,并且还会降低这类DML(非查询SQL)操作的性能,原因很简单,因为DML操作还需要我们对索引结构不断进行维护…所以索引并不是越多越好,还是有维护的成本的,所以很多情况是可以考虑不创建索引的,例如:
- 表数据量少
- 字段重复数据多
- 频繁进行DML操作的表
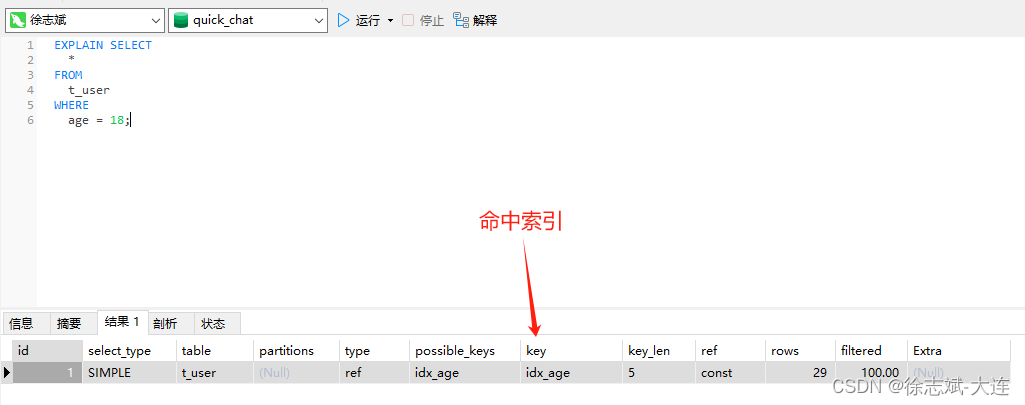
如果把MySQL比喻成一本书籍,那么索引就如同这本书籍的目录,我们通过目录就能大概确定我们想要页码的范围,这样就大大缩短了我们查找的时间,索引就类似这个工作方式,通过B+Tree就能够知道所查询行记录所在页,大大缩短了查询的范围,减少了对磁盘IO次数,提高查询性能。例如:我们为 t_user 表的 age 字段建立了索引,此时如果执行如下SQL,就会通过索引查询,性能非常快:
2、索引分类
无论是网上文章还是书中,经常会提到一大堆的索引概念,例如:主键索引、聚簇索引、二级索引、辅助索引、唯一索引…大家看到这些繁琐的名词就会觉得头晕,其实他们之间的很多概念都是重复的,例如我们常说的主键索引其实就是聚簇索引,接下来我们来具体看看不同维度下索引的分类有哪些。
2.1、数据结构
Hash
在Buffer Pool缓冲中有个部分就叫做:自适应哈希索引,这个索引采用的就是Hash的数据结构,也就是KV存储。频繁访问使用的索引页在一定场景下会被InnoDB自动转换成自适应Hash索引,自适应哈希索引采用的就是Hash的数据结构,这个转换不需要人为手动操作,Hash数据结构的索引时间复杂度为O(1),性能相比于后续提到的B+Tree结构要更快,不过Hash数据结构索引存储数据是无序的,并且不支持范围查询,除了自适应哈希索引,我们也可以为表中的字段手动创建Hash索引。
B + Tree
这是InnoDB存储引擎默认的索引数据结构,听名字就知道该数据结构是根据索引字段构造出一个树状结构。树的顶部就是根节点,树干部分我们称之为非叶子节点,最下方的部分就是叶子节点,B+Tree的每个节点本质都是一个页(16KB)。B+Tree的树状结构会按照索引字段值就行排序,也就是有序的,最下方叶子节点数据通过双向链表进行连接,方便相邻索引页横向检索查询。对于B+Tree数据结构,一般来说树层高3~4层,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
2.2、存储方式
聚簇索引
聚簇索引这个概念听着很唬人,其实我换个称呼你就知道它的真面目了,其实聚簇索引就是主键索引,聚簇索引的索引数据和表数据在磁盘中的位置是一起的,也就是说可以通过聚集聚集索引字段值直接找到对应整行表记录。一张表中除了主键索引属于聚簇索引,其他所有的索引都属于非聚簇索引(后面会提到),聚簇索引还有其他称呼:
- 聚簇索引
- 聚集索引
- 主键索引
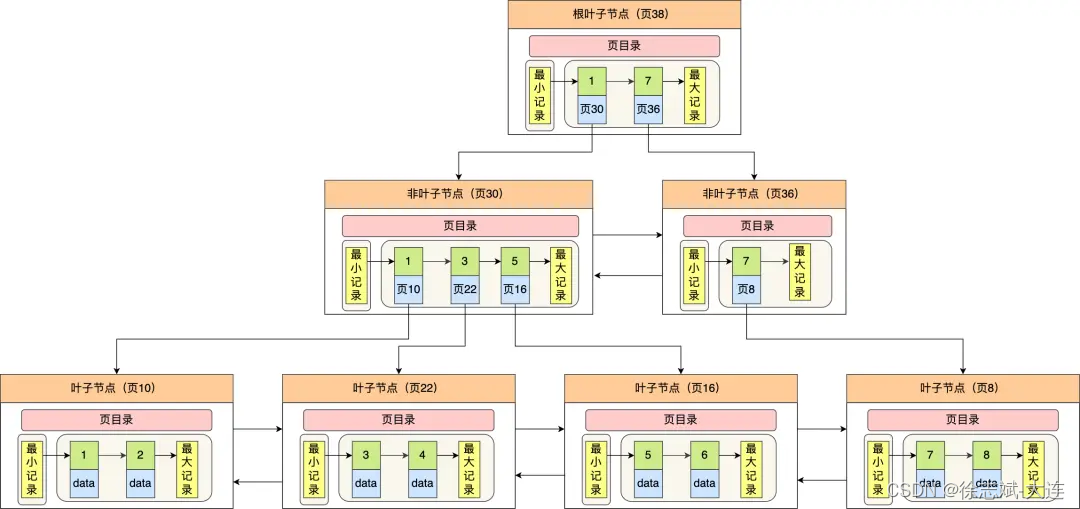
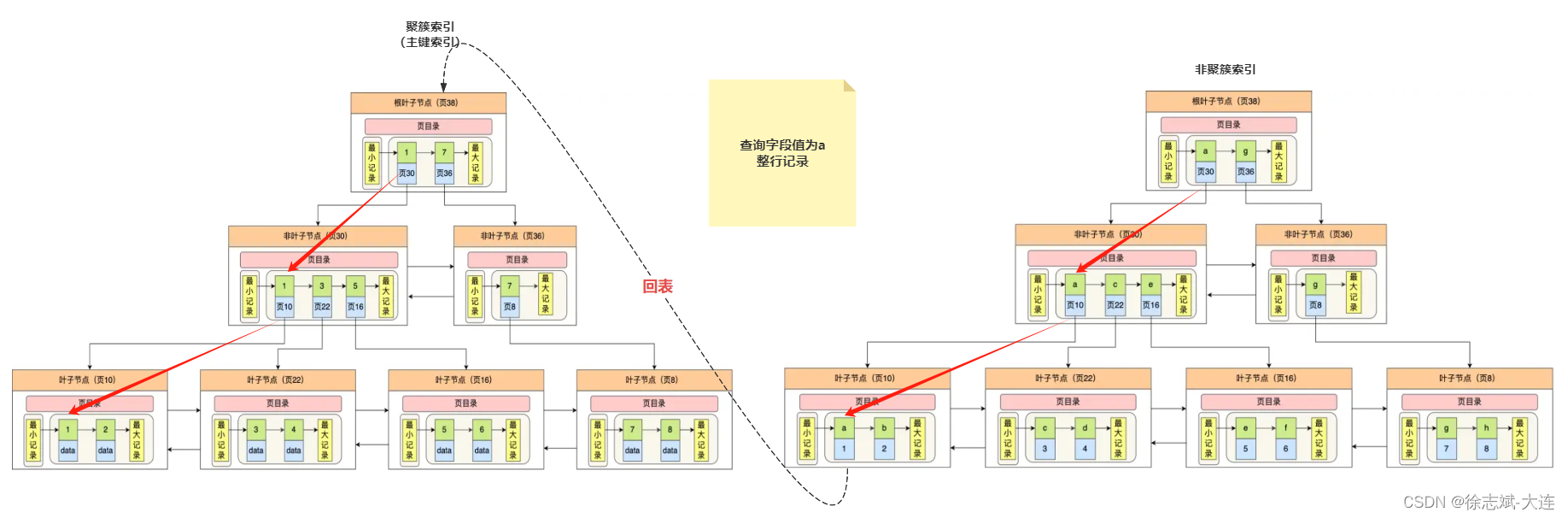
接下来看看数据也中聚簇索引 B+Tree样貌(下图来自于小林coding),B+Tree中每个节点都是页,每个页都会对应一个页号,假如我们条件查询想要查主键索引字段值为1的数据(聚簇索引就是主键索引),就会从根节点(页38)开始,不断向下遍历,直至通过B+Tree找到叶子节点(页10),从而找到该页中记录的索引字段值为1的data,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,页中记录会被页目录进行分组,在该页内通过页目录进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找行记录。
这里需要注意:聚簇索引叶子节点的行记录是主键索引对应的整行记录(包含所有的字段值),其中最大、最小记录可以理解为数据页中行记录的边界。图中绿色部分为聚簇(主键)索引字段值,叶子节点的蓝色部分data为聚簇(主键)索引字段值对应的整行记录。
非聚簇索引
什么是非聚簇索引呢?只需要记住除了主键索引(属于聚簇索引),其他类型的索引都属于非聚簇索引。非聚簇索引的索引数据和表数据在磁盘中的位置不是一起的(跟聚簇索引相反),用物理地址的方式维护两者的联系,非聚簇索引还有其他称呼:
- 非聚簇索引
- 非聚集索引
- 辅助索引
- 二级索引
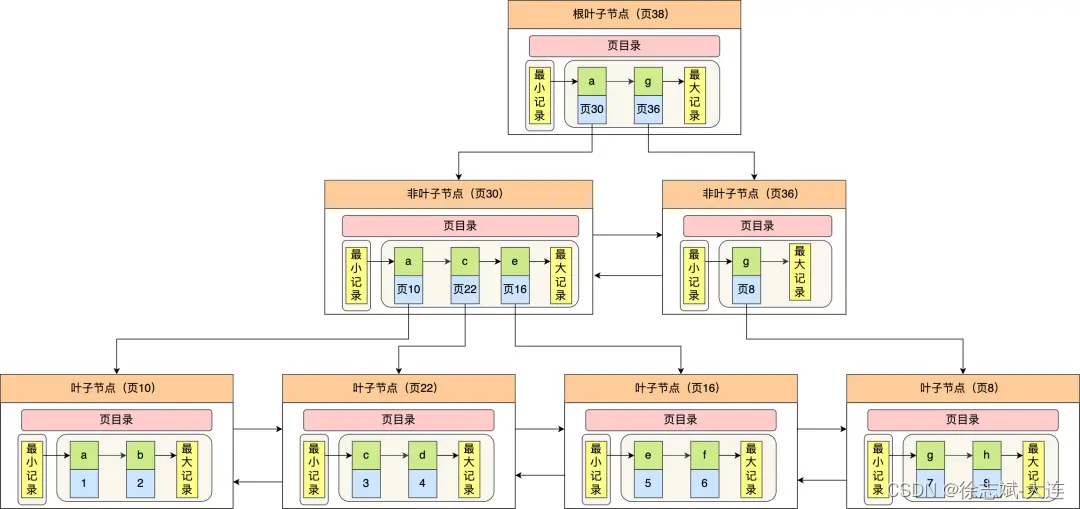
接下来看看数据也中非聚簇索引 B+Tree样貌(下图来自于小林coding),跟上面提到的聚簇索引 B+Tree最大的区别就是叶子节点的行记录不再是索引对应的一整行内容,而是索引字段对应行记录的主键字段值。
注意:图中绿色部分为非聚簇索引字段值,叶子节点的蓝色部分为非聚簇索引字段值对应行记录的主键id。
2.3、功能特性
主键索引
主键索引(PRIMARY KEY)是非空且唯一的,也就是说不允许重复,更不允许为空。
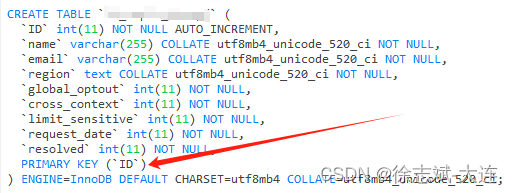
对于InnoDB存储引擎来说,任何一张表都会有主键索引,即使在表中时没有指定那个字段为主键索引,InnoDB也必须保证必须要有一个主键索引,当没有主键索引时它会按照以下规则选择:
如果没有指定主键索引,那就查找是否有非空唯一索引,认作主键索引
如果没有非空唯一索引,那 InnoDB 将自动生成一个隐式自增 id 列作为主键索引(row_id)
唯一索引
唯一索引(UNIQUE KEY)是不允许重复的,主键索引和唯一索引的区别在于不允许有空值。
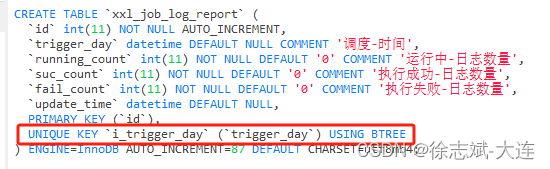
普通索引
普通索引(KEY)就是建立在普通字段上的索引,既不要求字段数据唯一,也不要求非空。
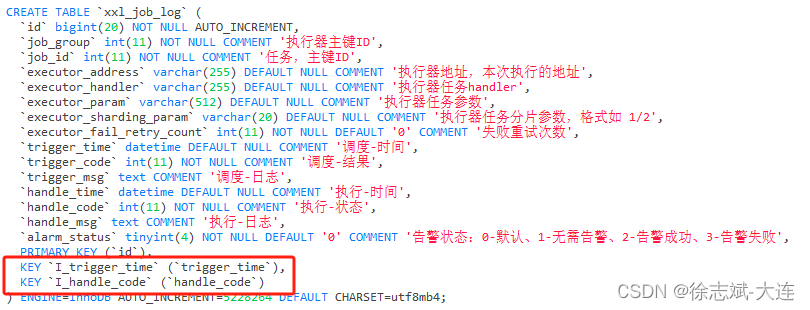
2.4、字段数量
单列索引
单列索引顾名思义,就是通过一个列(字段)创建的索引:
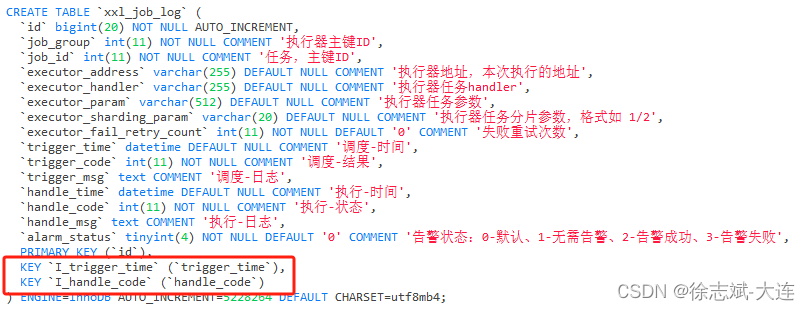
多列索引
多列索引又叫联合索引,多个字段(字段数量 ≥ 2)联合组成的索引,实际开发过程中建议尽可能使用联合索引来代替单列索引,并且还要符合特定规则情况下才能保证索引是有效的,这个规则就是最左匹配原则,后续会提到:
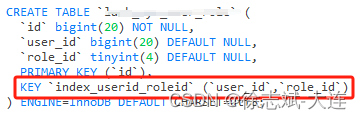
3、最佳实践
3.1、索引覆盖
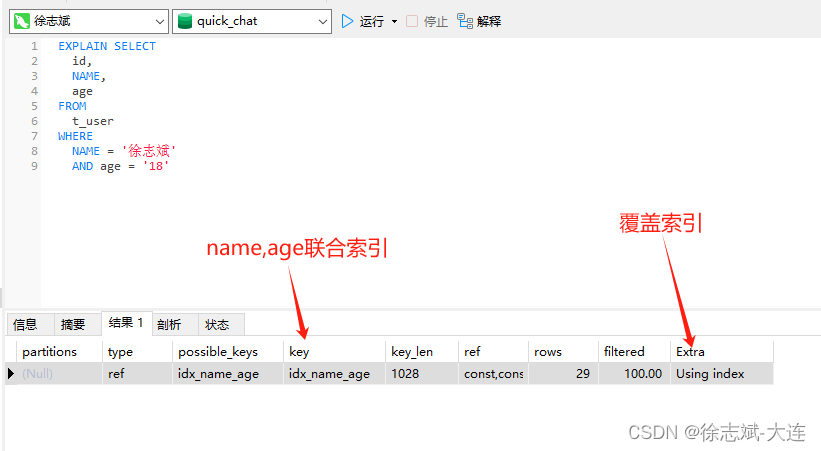
索引覆盖是比较理想的索引使用方式,具体解释就是:本次SQL查询所需要的字段数据都可以在当前索引的B+Tree叶子节点上找到,举个例子:加入有一张t_user表,表中有四个字段:id、name、age、weight,此时根据name、age字段建立了联合索引,联合索引本身就是非聚簇索引,也就是叶子节点中行记录不会包含主键id对应的整行记录,所以该联合索引构成的 B+Tree 叶子节点中行记录就大体包含了:name、age字段值,行记录对应的主键id。
此时如果查询SQL为下方语句,通过EXPLAIN查看本次查询SQL的执行计划可以看到Using Index,所需数据只需在当前索引即可全部获得,不须要再到表中获取其他字段数据,就说明本次的查询操作进行了索引覆盖:
但是下方这个SQL的查询操作就无法采用索引覆盖,因为weight字段值在叶子节点中不存在:
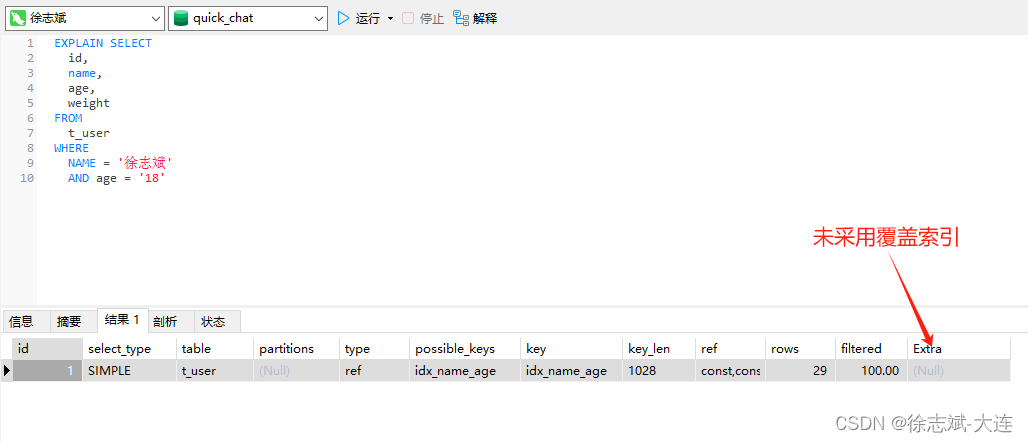
所以当非聚簇索引的B+Tree中字段值无法满足本次查询请求,就需要去聚簇索引的B+Tree中进行进一步查找,因为聚簇索引的叶子节点行记录是整行的,这步操作有个很官方的称呼,叫做回表,所以说到这里大家也该知道为啥不建议使用select *,其中一个原因就是这类SQL绝大多数情况下都需要进行回表操作,接下来画图解释一下什么是回表操作。
3.2、回表操作
上面大致介绍过了,回表简单来说就是查询字段信息无法在非聚簇索引B+Tree的行记录中完全拿到,需要在查询一次聚簇索引B+Tree,拿到缺失的字段信息,所以只能先从非聚簇索引找到查询目标行所对应的主键id,然后根据主键id回到聚簇索引中查询整行记录,拿到想要的信息,如下图:
3.3、最左匹配原则
针对与多列索引(非聚簇索引)有个很重要的概念叫做最左匹配原则。简单来说就是我们的查询SQL如果想要命中联合索引,那么查询条件就要有一定的规则顺序,例如创建了一个 (a, b, c) 联合索引:
# 符合(由于优化器存在,a顺序不重要)
where a = 1;
where a = 1 and b = 2;
where a = 1 and b = 2 and c = 3;# 不符合,索引失效
where b = 2;
where c = 3;
where b = 2 and c = 3;
之所以需要匹配,原因就是B+Tree索引结构是有序的,根据a,b,c建立联合索引,InnoDB会从a字段开始排序,然后再是b,最后是c;所以单单通过b,c自然就无法进行排序查找。
MySQL的最左前缀原则,在匹配到范围查询时会停止匹配,比如>、<、between、like这类范围条件,并不会继续使用联合索引,例如:where a = 1 and b > 2 and c = 3,则会在每个节点依次命中ab,无法命中c。对于联合索引的建立有个技巧,就是把查询条件使用频次多的字段放到前面,这样尽可能的能够踩中最左匹配原则。
3.4、索引下推
索引下推是InnoDB5.6版本诞生的优化特性,它出现就是为了减少回表次数,提高查询效率。上面讲最左匹配原则是提到过遇到范围查询条件时会停止规则匹配,例如:>、<、between、like,那么当我们对a,b建立联合索引,此时查询条件为:
select a,b,c from 表 where a > 10 and b = 100
此时只有 a 踩中了索引,假设此时查询a,b,c字段信息是需要回表,那么它并不会直接开始回表操作,它在继续回表前,先将b字段的判断条件进行一次筛选,如果不符合本次查询到行记录b字段值,那就没必要在进行回表了,这就是索引下推ICP,减少了回表次数,提高查询性能。