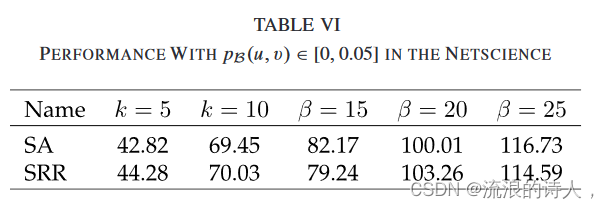
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
#include <iostream>
#include <vector>
#include <unordered_set>int longestConsecutiveSequence(const std::vector<int>& nums) {std::unordered_set<int> numSet(nums.begin(), nums.end());int maxLength = 0;for (int num : numSet) {// 只考虑当前数字作为序列起点的情况if (numSet.find(num - 1) == numSet.end()) {int currentNum = num;int currentLength = 1;while (numSet.find(currentNum + 1) != numSet.end()) {currentNum++;currentLength++;}maxLength = std::max(maxLength, currentLength);}}return maxLength;
}int main() {std::vector<int> nums = {100, 4, 200, 1, 3, 2};int result = longestConsecutiveSequence(nums);std::cout << "The length of the longest consecutive sequence is: " << result << std::endl;return 0;
}这段代码首先将输入的整数数组构建为一个 unordered_set,以便快速查找数字是否存在。然后遍历数组中的每个数字,对于每个数字,判断是否存在比它小的数字(即作为某个序列的起点),如果不存在,则从该数字开始向后搜索连续的数字,计算当前连续序列的长度。最后更新最长连续序列的长度并返回。
整个算法的时间复杂度为 O(n),其中 n 为输入数组的长度,因为使用了哈希集合来存储数字,判断数字是否存在的时间复杂度为 O(1)。
不考虑时间复杂度,纯从解题角度还有一种解决方案:
int longestConsecutive(vector<int>& nums) {int len = nums.size();if (len == 0) {return 0;}int maxlen = 1;int maxt = 1;vector<int> numst = nums;unordered_map<int, int> m;sort(numst.begin(), numst.end());for (int i = 0; i < len; i++) {if (m.find(nums[i]) == m.end()) {m.insert(make_pair(nums[i], 1));}else {m[nums[i]] = m[nums[i]] + 1;}}for (int i = 0; i < len-1; i++) {if ((m.find(numst[i] + 1) != m.end())) {if (m[numst[i] + 1]) {maxt++;m[numst[i] + 1] = 0;}}else {maxt = 1;}maxlen = max(maxlen, maxt);}return maxlen;}
};
时间复杂度为 O(n log n),空间复杂度为 O(n)。
时间复杂度分析:
对输入数组 nums 进行排序的时间复杂度为 O(n log n)。
第一个 for 循环遍历整个数组并将元素及其出现次数存储在 unordered_map 中,时间复杂度为 O(n)。
第二个 for 循环遍历排序后的数组,对于每个元素,查找其是否存在相邻的元素,并更新最长连续序列的长度,时间复杂度为 O(n)。
综合以上步骤,总体时间复杂度为 O(n log n) + O(n) + O(n) = O(n log n)。
空间复杂度分析:
额外使用了一个大小为 n 的 vector numst 来存储 nums 的副本,空间复杂度为 O(n)。
使用了一个 unordered_map<int, int> m 来存储元素及其出现次数,空间复杂度也为 O(n)。
综合以上两部分,总体空间复杂度为 O(n)。
这个方案使用了排序和哈希表的方法来计算最长连续序列的长度。和上一个方案相比的优势和劣势:
优势:
排序后查找相邻元素更方便: 通过对数组进行排序,可以更容易地找到相邻的元素,从而判断是否存在连续序列。
使用哈希表存储元素及其出现次数: 哈希表在查找、插入操作上具有 O(1) 的时间复杂度,能够有效地存储元素及其出现次数,方便后续的查找和更新操作。
劣势:
时间复杂度较高: 使用排序的方法将时间复杂度提升到了 O(n log n),而哈希表的插入和查找操作虽然是 O(1),但仍需遍历整个数组,总体时间复杂度仍为 O(n log n)。
空间复杂度较高: 使用了额外的哈希表来存储元素及其出现次数,增加了空间复杂度。
逻辑复杂度高: 需要维护排序后的数组以及哈希表,增加了代码的复杂度和维护成本。
相比之下,前一种方案,代码逻辑清晰,且时间复杂度为 O(n),空间复杂度也较低,不需要额外的排序和哈希表操作。