Flink学习笔记
前言:今天是学习 flink 的第 10 天啦!学习了 flink 四大基石之 State (状态),主要是解决大数据领域增量计算的效果,能够保存已经计算过的结果数据状态!重点学习了 state 的类型划分和应用,以及 TTL 原理和应用,即数据状态也会过期和定期清除的问题,以及广播流数据的企业应用场景,结合自己实验猜想和代码实践,总结了很多自己的理解和想法,希望和大家多多交流!
Tips:广州回南天色佳,学习 state 意更浓。心随知识飘然去,智慧之舟破浪中。越来越有状态,明天也要继续努力!
文章目录
- Flink学习笔记
- 三、Flink 高级 API 开发
- 3. State
- 3.1 State 应用场景
- 3.2 State 类型划分
- 3.2.1 Keyed State 键控状态
- (1) 特点
- (2) 保存的数据结构
- (3) 案例演示
- 3.2.1 Operate State 算子状态
- (1) 特点
- (2) 保存的数据结构
- (3) 案例演示
- 3.3 State TTL 状态有效期
- 3.3.1 功能用法
- (1) TTL 的更新策略
- (2) 状态数据过期但未被清除时
- (3) 过期数据的清除
- 3.3.2 案例演示
- 3.4 Broadcast State
- 3.4.1 应用场景
- 3.4.2 注意事项
- 3.4.3 案例演示
- 3.4.4 BroadcastState 执行思路梳理
三、Flink 高级 API 开发
3. State
简介:State(状态)是基于 Checkpoint(检查点)来完成状态持久化,在 Checkpoint 之前,State 是在内存中(变量),在 Checkpoint 之后,State 被序列化永久保存,支持存储方式:File,HDFS,S3等。
3.1 State 应用场景
- (1)去重
- (2)窗口计算
- (3)机器学习/深度学习
- (4)访问历史数据
3.2 State 类型划分
- 基本类型划分
- Keyed State(键控状态)
- Operate State(算子状态)
- 存在方式划分
- raw State (原始状态):原始状态
- managed State(托管状态):Flink 自动管理的 State,实际生产推荐使用
- 原始状态和托管状态区别:
| 状态管理方式 | 数据结构 | 使用场景 | |
|---|---|---|---|
| Managed State | Flink Runtime 管理自动存储,自动恢复内存管理可自动优化 | Value,List,Map… | 大多数情况下均可使用 |
| Raw State | 需要用户自己管理,需要自己序列化 | 字节数组 | 自定义Operator时使用 |
3.2.1 Keyed State 键控状态
(1) 特点
- 1- 只能用于 keyby 后的数据流
- 2- 一个 key 只能属于 一个key State
(2) 保存的数据结构
- Keyed State 通过 RuntimeContext 访问,这需要 Operator 是一个RichFunction。
- 1- ValueState:单值状态
- 2- ListState:列表状态
- 3- ReducingState:传入reduceFunction,单一状态值
- 4- MapState<UK, UV>:状态值为 map
(3) 案例演示
例子:词频统计,不要用 sum,而是用 reduce,然后 ValueState
package cn.itcast.day10.state;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichReduceFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author lql* @time 2024-03-03 16:01:44* @description TODO:演示 keyedState 的使用*/
public class KeyedStateDemo {public static void main(String[] args) throws Exception {//todo 1)创建flink流处理的运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//todo 2)开启checkpointenv.enableCheckpointing(5000);//todo 3)构建数据源DataStreamSource<String> lines = env.socketTextStream("node1", 9999);//todo 4)单词拆分SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndNum = lines.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String line) throws Exception {String[] data = line.split(",");return Tuple2.of(data[0], Integer.parseInt(data[1]));}});//todo 5)分流操作KeyedStream<Tuple2<String, Integer>, String> keyedDataStream = wordAndNum.keyBy(t -> t.f0);//todo 6) 聚合操作(自定义state方式实现)SingleOutputStreamOperator<Tuple2<String, Integer>> reduceState = keyedDataStream.reduce(new RichReduceFunction<Tuple2<String, Integer>>() {// todo 6.1 定义 state 对象private ValueState<Tuple2<String, Integer>> valueState = null;// 初始化资源@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// todo 6.2 实例化 state 对象valueState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple2<String, Integer>>("reduceState",TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {})));}@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {// state 存储的历史数据// todo 6.3 获取state 对象Tuple2<String, Integer> result = valueState.value();if (result == null) {result = Tuple2.of(value1.f0, value1.f1);}Tuple2<String, Integer> resultSum = Tuple2.of(result.f0, result.f1 + value2.f1);// 之前没有重写状态:Tuple2.of(value1.f0, value1.f1 + value2.f1);// 因为我们这里的 value1 已经从 state 中获取到 result了,所以重写状态的方法是,就用result!// todo 6.4 更新 state 对象valueState.update(resultSum);return resultSum;}// 释放资源@Overridepublic void close() throws Exception {super.close();// 获取 state 的数据Tuple2<String, Integer> value = valueState.value();System.out.println("=======释放资源的时候打印 state 数据========");System.out.println(value);}});//todo 6)打印测试reduceState.print();//todo 7)运行env.execute();}
}
结果:
输入:
hadoop,1
hadoop,2输出:
8> (hadoop,1)
8> (hadoop,3)
总结:
- 1- state 类似于一个数据库,可以从中获取之前计算过的数据
- 2- 定义 state 对象,初始值为 null
- 3- 实例化 state 对象,getRuntimeContext().getState(new ValueStateDescriptor())
- 4- 获取 state 中的数据:状态.value()
- 5- 更新 state 中的数据:状态.update(数据流)
3.2.1 Operate State 算子状态
(1) 特点
- 1- 一个算子状态仅与一个算子实例绑定
- 2- 算子状态可以用于所有算子,但常见是 Source
(2) 保存的数据结构
- Operator State 需要自己实现 CheckpointedFunction 或 ListCheckpointed 接口
- 1- ListState
- 2- BroadcastState<K,V>
(3) 案例演示
例子:使用 OperatorState 进行演示基于类似于 kafka 消费数据的功能
package cn.itcast.day10.state;/*** @author lql* @time 2024-03-03 17:21:50* @description TODO:使用OperatorState进行演示基于类似于kafka消费数据的功能*/import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.OperatorStateStore;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;import java.util.List;
import java.util.concurrent.TimeUnit;/*** 实现步骤:* 1)初始化flink流式程序的运行环境* 2)设置并行度为1* 3)启动checkpoint* 4)接入数据源* 5)打印测试* 6)启动作业*/
public class OperatorStateDemo {public static void main(String[] args) throws Exception {// todo 1) 初始化环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// todo 2) 设置并行度为 1env.setParallelism(1);// todo 3) 启动checkpoint机制env.enableCheckpointing(4000);// todo 4) 接入数据源DataStreamSource<Integer> source = env.addSource(new MySourceWithState());SingleOutputStreamOperator<String> result = source.map(new MapFunction<Integer, String>() {@Overridepublic String map(Integer integer) throws Exception {return integer.toString();}});//TODO 5)打印测试result.printToErr();//TODO 6)启动作业env.execute();}private static class MySourceWithState extends RichSourceFunction<Integer> implements CheckpointedFunction {//定义成员变量是否循环生成数据private Boolean isRunning = true;private Integer currentCounter = 0;//定义ListState保存结果数据。保存offset的累加值private ListState<Integer> listState = null;/*** 将state中的数据持久化存储到文件中(每4秒钟进行一次快照,将state数据存储到hdfs)* @param functionSnapshotContext* @throws Exception*/@Overridepublic void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {System.out.println("调用snapshotState方法。。。。。。。。");// 清除历史状态存储的历史数据,this引用对象的成员变量this.listState.clear();//将最新的累加值添加到状态中this.listState.add(this.currentCounter);}/*** 初始化 state 对象* @param context* @throws Exception*/@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {System.out.println("调用initializeState方法。。。。。。。。");//初始化一个listStateOperatorStateStore stateStore = context.getOperatorStateStore();listState = stateStore.getListState(new ListStateDescriptor<>("operator-states",TypeInformation.of(new TypeHint<Integer>() {})));// 获取历史数据for (Integer counter : this.listState.get()) {//将历史存储的累加值取出来赋值给当前累加值变量this.currentCounter = counter;}//清除状态中存储的历史数据this.listState.clear();}/*** 生产数据* @param sourceContext* @throws Exception*/@Overridepublic void run(SourceContext<Integer> sourceContext) throws Exception {while (isRunning){currentCounter ++;sourceContext.collect(currentCounter);TimeUnit.SECONDS.sleep(1);if (this.currentCounter == 10){System.out.println("手动抛出异常"+(1/0));}}}/*** 取消生产数据*/@Overridepublic void cancel() {isRunning = false;}}
}
结果:
调用initializeState方法。。。。。。。。
1
2
3
4
调用snapshotState方法。。。。。。。。
5
6
7
8
调用snapshotState方法。。。。。。。。
9
10
调用initializeState方法。。。。。。。。
9
调用snapshotState方法。。。。。。。。
10<==10这里出现异常了,所以保存state中的数据是9,初始化方法后恢复 9+1 数据,然后 10 也保存到state中了==>调用initializeState方法。。。。。。。。
10
调用snapshotState方法。。。。。。。。
调用initializeState方法。。。。。。。。
11
12
13
14
调用snapshotState方法。。。。。。。。
15
16
17
总结:
- 1- 定义数据源要继承 RichSourceFunction 父类,实现 CheckpointedFunction 接口
- 2- 初始化 listState:getOperatorStateStore.getListState(new ListStateDescriptor<>)
- 3- 获取历史数据:因为是listState,所以用循环 get()
- 4- 历史值赋予当前值,清空历史数据 clear()
- 5- 检查点之后,恢复数据就是 [ 历史数据 + 1 ]
3.3 State TTL 状态有效期
举例子:更新策略着眼于是更新日期是在哪个时候,
而这里设置停留时间 .newBuilder(Time.seconds(1)) 是指状态保存多长时间,
时间一过状态数据就标记过期(设置时间要比 checkpoint 时间长,才能保证 checkpoint 顺利持久化),
清除策略着眼于过期数据清理是在哪个时候
应用场景:使用 flink 进行实时计算中,会遇到一些状态数不断累积,导致状态量越来越大的情形。
3.3.1 功能用法
(1) TTL 的更新策略
-
只在创建和写入时更新:.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
-
读取和写入时也会更新:.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
(2) 状态数据过期但未被清除时
- 不返回过期数据:.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
- 返回未被清除的过期数据:.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
(3) 过期数据的清除
-
关闭后台自动清理过期数据:disableCleanupInBackground()
-
全量快照时清理:cleanupFullSnapshot()
- 这种策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效。
-
增量快照时清理:.cleanupIncrementally(10, true)
-
第一个是每次清理时检查状态的条目数,在每个状态访问时触发。
第二个参数表示是否在处理每条记录时触发清理。
-
-
后台自动清理(RocksDB state backend 存储):.cleanupInRocksdbCompactFilter(1000)
-
默认后台清理策略会每处理 1000 条数据进行一次,
-
表示在 RocksDB 的compaction过程中,每删除1000个键值对,就会执行一次TTL过期的键值对的清理。
-
RocksDB 的 compaction是一个过程,它会合并多个小的数据库文件(SSTables)成一个大的文件
-
3.3.2 案例演示
例子1:10s 读取一行数据,checkpoint 60s,state 时间 5 s
package cn.itcast.day10.state;import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.util.Collector;import java.io.BufferedReader;
import java.io.FileReader;
import java.util.concurrent.TimeUnit;/*** @author lql* @time 2024-03-04 18:53:52* @description TODO*/
public class StateWordCount {public static void main(String[] args) throws Exception {// todo 1) 使用工具类将传入的参数解析为对象final ParameterTool parameters = ParameterTool.fromArgs(args);// todo 2) 初始化环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// todo 3) 将传入的参数解析成参数注册到作业中env.getConfig().setGlobalJobParameters(parameters);// todo 4) 开启 checkpoint,一致性语义env.enableCheckpointing(60000, CheckpointingMode.EXACTLY_ONCE);// todo 5) 接入数据源DataStreamSource<String> lines = env.addSource(new SourceFunctionFile());lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] data = s.split(" ");for (String item : data) {collector.collect(new Tuple2<>(item, 1));}}}).keyBy(t -> t.f0).flatMap(new WordCountFlatMap()).printToErr();// todo 6)启动作业env.execute();}private static class SourceFunctionFile extends RichSourceFunction<String> {// 定义是否继续生成数据标记private Boolean isRunning = true;@Overridepublic void run(SourceContext<String> sourceContext) throws Exception {BufferedReader bufferedReader = new BufferedReader(new FileReader("D:\\IDEA_Project\\BigData_Java\\flinkbase_pro\\data\\input\\wordcount.txt"));while (isRunning) {String line = bufferedReader.readLine();if (StringUtils.isBlank(line)) {continue;}sourceContext.collect(line);TimeUnit.SECONDS.sleep(10);}}@Overridepublic void cancel() {isRunning = false;}}// 自定义聚合private static class WordCountFlatMap extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {// 定义状态private ValueState<Tuple2<String, Integer>> valueState = null;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);//创建ValueStateDescriptorValueStateDescriptor valueStateDescriptor = new ValueStateDescriptor("StateWordCount",TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));//配置stateTTLStateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) // 存活时间.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // 创建或更新的时候修改时间.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 永不返回过期的数据.cleanupFullSnapshot() // 全量快照时进行清理.build();// 激活 stateTTLvalueStateDescriptor.enableTimeToLive(ttlConfig);// 实例化 valueState 对象valueState = getRuntimeContext().getState(valueStateDescriptor);}@Overridepublic void close() throws Exception {super.close();}@Overridepublic void flatMap(Tuple2<String, Integer> value, Collector<Tuple2<String, Integer>> collector) throws Exception {// 获取状态数据Tuple2<String, Integer> currentState = valueState.value();// 初始化 valueState 数据if (currentState == null) {currentState = new Tuple2<>(value.f0,0);}// 累加单词的次数Tuple2<String, Integer> newState = new Tuple2<>(currentState.f0, currentState.f1 + value.f1);// 更新valueStatevalueState.update(newState);// 返回累加后的结果collector.collect(newState);}}
}
数据源:
Total time BUILD SUCCESS
Final Memory Finished at
Total time BUILD SUCCESS
Final Memory Finished at
Total time BUILD SUCCESS
Final Memory Finished at
BUILD SUCCESS
BUILD SUCCESS
BUILD SUCCESS
BUILD SUCCESS
BUILD SUCCESS
结果:没有累加历史值
======第1个10s=====
(Total,1)
(time,1)
(BUILD,1)
(SUCCESS,1)======第2个10s=====
(Final,1)
(Memory,1)
(Finished,1)
(at,1)======第3个10s=====
(Total,1)
(time,1)
(BUILD,1)
(SUCCESS,1)
例子2:10s 读取一行数据,checkpoint 5s,state 时间 20 s 或者 21s
结果:触发累加历史值
======第1个10s=====
(Total,1)
(time,1)
(BUILD,1)
(SUCCESS,1)======第2个10s=====
(Final,1)
(Memory,1)
(Finished,1)
(at,1)======第3个10s=====
(Total,2)
(time,2)
(BUILD,2)
(SUCCESS,2)
例子3:10s 读取一行数据,checkpoint 5s,state 时间 19s
结果:没有累加历史值
-
总结1: 从例子1-3,因为第1个Total距第2个Total 20s,故 state 设置要尽可能大20s,设置太小来不及遇见第二个就过期了。
例子4:10s 读取一行数据,checkpoint 10s,state 时间 20 s
结果:触发累加历史值
例子5:10s 读取一行数据,checkpoint 60s,state 时间 20s
结果:触发累加历史值
例子6:10s 读取一行数据,checkpoint 20s,state 时间 20 s
结果:没有累加历史值
-
总结2:从例子 4-6,checkpoint 比 state 建议小很多或大很多,不然 [10-20] 有些不能触发,[20-60] 有些能触发。
例子7:10s 读取一行数据,checkpoint 19s,state 时间 20s(之前不能触发)
(此时设置.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp) // 返回过期但未被清除的数据)
结果:触发累加历史值
例子8:10s 读取一行数据,checkpoint 60s,state 时间 5 s(之前state小于20s不能触发)
结果:触发累加历史值
例子9:10s 读取一行数据,checkpoint 60s,state 时间 20s(之前可以触发)
(此时设置.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp) // 返回过期但未被清除的数据)
结果:触发累加历史值
-
总结3:从例子7-9,设置 ReturnExpiredIfNotCleanedUp 之前可以触发的不可以触发的,都可以触发了!
总结:
- 1- state 设置要尽可能大于相同数据间隔s,设置太小来不及遇见第二个就过期了。
- 2- checkpoint 比 state 建议小很多或大很多
- 3- 设置 ReturnExpiredIfNotCleanedUp 可以避免不能触发
- 4- BufferedReader 去 new 一个 FileReader 可以读取文件
- 5- 激活 stateTTL:valueStateDescriptor.enableTimeToLive(ttlConfig)
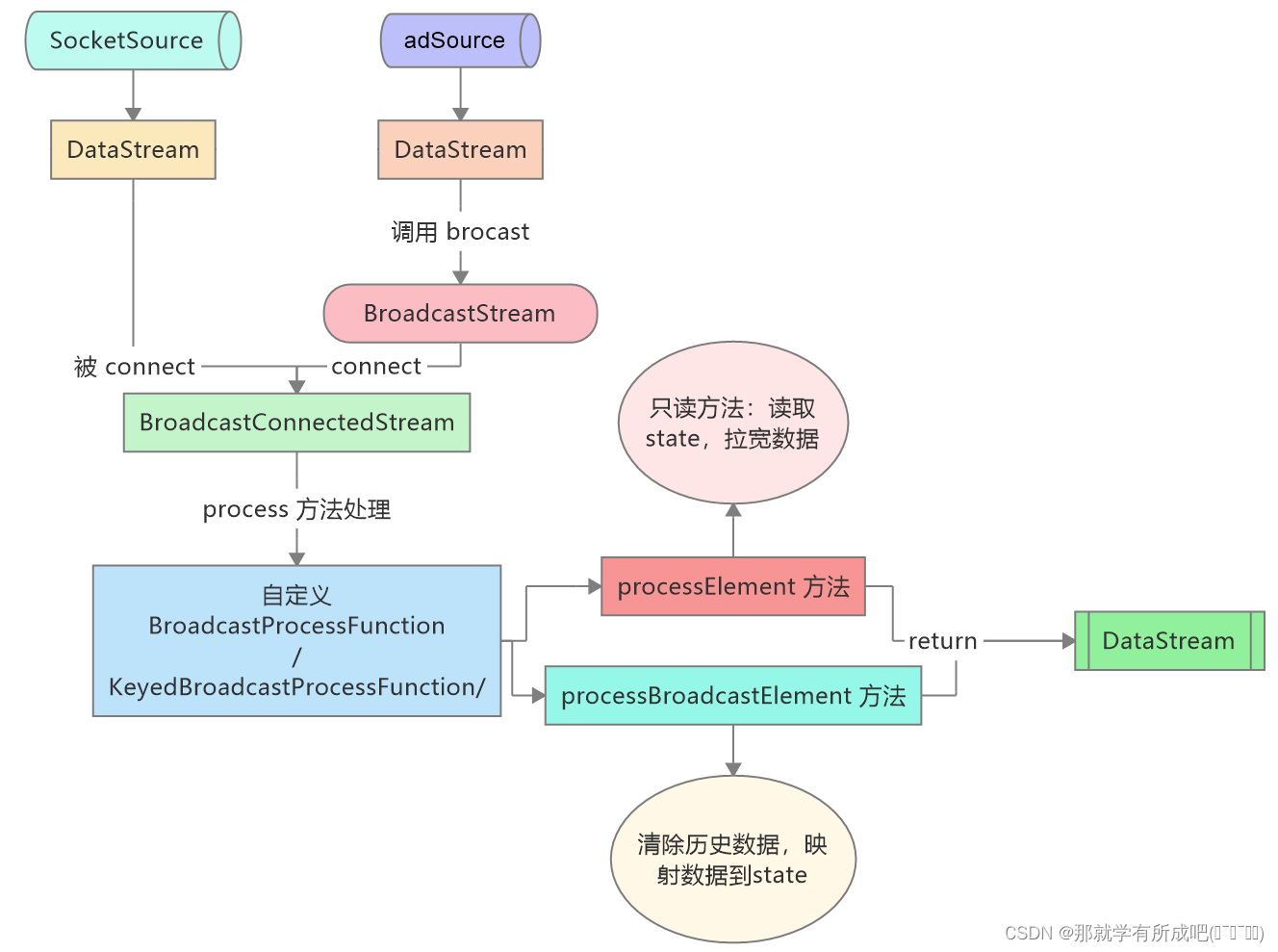
3.4 Broadcast State
3.4.1 应用场景
- 1-动态更新计算规则: 如事件流需要根据最新规则进行计算,可将规则作为广播状态广播到下游Task。
- 2-实时增加额外字段: 如事件流需要实时增加用户基础信息,可将基础信息作为广播状态到下游Task。
3.4.2 注意事项
-
Broadcast State 是 Map 类型,即 K-V 类型
-
Broadcast State 只有在广播的一侧,即在重写方法:processBroadcastElement 方法中可修改,另一个方法只读
-
Broadcast State 在 checkpoint 时,每个 Task 都会 checkpoint(持久化)广播状态。
-
Broadcast State 在运行时保存在内存中,(flink 1.13)还不能保存在 Rocked State Backend 中
3.4.3 案例演示
例子:公司有10个广告位, 其广告的内容(描述和图片)会经常变动(广告到期,更换广告等)
package cn.itcast.day10.state;/*** @author lql* @time 2024-03-05 13:54:54* @description TODO*/import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;import java.util.*;
import java.util.concurrent.TimeUnit;/*** 广播状态流演示* 需求:公司有10个广告位, 其广告的内容(描述和图片)会经常变动(广告到期,更换广告等)* 实现:* 1)通过socket输入广告id(事件流)* 2)关联出来广告的信息打印出来,就是广告发生改变的时候,能够感知到(规则流)*/
public class BroadcastStateDemo {public static void main(String[] args) throws Exception {//todo 1)初始化flink流处理的运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//todo 2) 设置checkpoint周期运转env.enableCheckpointing(5000L);//todo 3) 构建数据流 (我输入的是字符串数字,需要转化为整数类型)DataStreamSource<String> lines = env.socketTextStream("node1", 9999);SingleOutputStreamOperator<Integer> adIdDataStream = lines.map(new MapFunction<String, Integer>() {@Overridepublic Integer map(String value) throws Exception {return Integer.parseInt(value);}});// todo 4) 构建规则流(广告流)DataStreamSource<Map<Integer, Tuple2<String, String>>> adSourceStream = env.addSource(new MySourceForBroadcastFunction());adSourceStream.print("最新的广告信息>>>");// todo 5) 将规则流(广告流)转化为广播流==> 这里和之前的广播是不一样的!// todo 5.1 定义规则流(广告流)的描述器MapStateDescriptor<Integer, Tuple2<String, String>> mapStateDescriptor = new MapStateDescriptor<Integer, Tuple2<String, String>>("broadcaststate",TypeInformation.of(new TypeHint<Integer>() {}),TypeInformation.of(new TypeHint<Tuple2<String,String>>(){}));// todo 5.2 运用描述器将(广告流)转化为广播流BroadcastStream<Map<Integer, Tuple2<String, String>>> broadcastStream = adSourceStream.broadcast(mapStateDescriptor);// todo 6) 将数据流和规则流合并在一起BroadcastConnectedStream<Integer, Map<Integer, Tuple2<String, String>>> connectedStream = adIdDataStream.connect(broadcastStream);// todo 7) 对关联后的数据做拉宽操作SingleOutputStreamOperator<Tuple2<String, String>> result = connectedStream.process(new MyBroadcastProcessFunction());// todo 8) 打印结果数据result.printToErr("拉宽后的结果>>>");//todo 9)启动作业env.execute();}/*** 自定义规则数据,注意 返回类型是 Map<K,V>*/private static class MySourceForBroadcastFunction implements SourceFunction<Map<Integer, Tuple2<String,String>>> {private final Random random = new Random();private final List<Tuple2<String, String>> ads = Arrays.asList(Tuple2.of("baidu", "搜索引擎"),Tuple2.of("google", "科技大牛"),Tuple2.of("aws", "全球领先的云平台"),Tuple2.of("aliyun", "全球领先的云平台"),Tuple2.of("腾讯", "氪金使我变强"),Tuple2.of("阿里巴巴", "电商龙头"),Tuple2.of("字节跳动", "靠算法出名"),Tuple2.of("美团", "黄色小公司"),Tuple2.of("饿了么", "蓝色小公司"),Tuple2.of("瑞幸咖啡", "就是好喝"));private boolean isRun = true;@Overridepublic void run(SourceContext<Map<Integer, Tuple2<String, String>>> sourceContext) throws Exception {while (isRun){// 定义一个 HashMap,用来存储键值对HashMap<Integer, Tuple2<String,String>> map = new HashMap<>();int keyCounter = 0;for (int i = 0; i < ads.size(); i++) {keyCounter++;map.put(keyCounter,ads.get(random.nextInt(ads.size())));}sourceContext.collect(map);TimeUnit.SECONDS.sleep(5L);}}@Overridepublic void cancel() {isRun = false;}}private static class MyBroadcastProcessFunction extends BroadcastProcessFunction<Integer,Map<Integer, Tuple2<String, String>>, Tuple2<String, String>> {//定义state的描述器MapStateDescriptor<Integer, Tuple2<String, String>> mapStateDescriptor = new MapStateDescriptor<Integer, Tuple2<String, String>>("broadcaststate",TypeInformation.of(new TypeHint<Integer>() {}),TypeInformation.of(new TypeHint<Tuple2<String, String>>() {}));/*** 这个方法只读,用来拉宽操作* @param integer* @param readOnlyContext* @param collector* @throws Exception*/@Overridepublic void processElement(Integer integer, ReadOnlyContext readOnlyContext, Collector<Tuple2<String, String>> collector) throws Exception {//只读操作,意味着只能读取数据,不能修改数据,根据广告id获取广告信息ReadOnlyBroadcastState<Integer, Tuple2<String, String>> broadcastState = readOnlyContext.getBroadcastState(mapStateDescriptor);//根据广告id获取广告信息Tuple2<String, String> tuple2 = broadcastState.get(integer);//判断广告信息是否关联成功if(tuple2 != null) {collector.collect(tuple2);}}/*** 可写的,用来更新state的数据* @param integerTuple2Map* @param context* @param collector* @throws Exception*/@Overridepublic void processBroadcastElement(Map<Integer, Tuple2<String, String>> integerTuple2Map, Context context, Collector<Tuple2<String, String>> collector) throws Exception {//先读取state数据BroadcastState<Integer, Tuple2<String, String>> broadcastState = context.getBroadcastState(mapStateDescriptor);// 删除历史状态数据broadcastState.clear();//将最新获取到的广告信息进行广播操作broadcastState.putAll(integerTuple2Map);}}
}
结果:
最新的广告信息>>>:7> {1=(aws,全球领先的云平台), 2=(aliyun,全球领先的云平台), 3=(阿里巴巴,电商龙头), 4=(aws,全球领先的云平台), 5=(瑞幸咖啡,就是好喝), 6=(瑞幸咖啡,就是好喝), 7=(美团,黄色小公司), 8=(aws,全球领先的云平台), 9=(腾讯,氪金使我变强), 10=(字节跳动,靠算法出名)}最新的广告信息>>>:8> {1=(美团,黄色小公司), 2=(饿了么,蓝色小公司), 3=(aws,全球领先的云平台), 4=(baidu,搜索引擎), 5=(aws,全球领先的云平台), 6=(baidu,搜索引擎), 7=(美团,黄色小公司), 8=(字节跳动,靠算法出名), 9=(瑞幸咖啡,就是好喝), 10=(腾讯,氪金使我变强)}======我在终端输入了 3,刚好对应上面一条信息的 3 位置========
拉宽后的结果>>>:4> (aws,全球领先的云平台)最新的广告信息>>>:1> {1=(饿了么,蓝色小公司), 2=(aliyun,全球领先的云平台), 3=(google,科技大牛), 4=(瑞幸咖啡,就是好喝), 5=(美团,黄色小公司), 6=(baidu,搜索引擎), 7=(google,科技大牛), 8=(google,科技大牛), 9=(google,科技大牛), 10=(腾讯,氪金使我变强)}最新的广告信息>>>:2> {1=(google,科技大牛), 2=(饿了么,蓝色小公司), 3=(字节跳动,靠算法出名), 4=(aliyun,全球领先的云平台), 5=(aws,全球领先的云平台), 6=(aws,全球领先的云平台), 7=(google,科技大牛), 8=(google,科技大牛), 9=(美团,黄色小公司), 10=(aliyun,全球领先的云平台)}======我在终端输入了 1,刚好对应上面一条信息的 1 位置========
拉宽后的结果>>>:5> (google,科技大牛)
总结:
- 1- 这里的规则流转化为广播流操作,和之前广播分区不一样
- 数据广播到各个分区:数据.Brocast()
- 数据流转化为广播流:数据.Brocast(描述器)
- 2- BroadcastProcessFunction 方法中重写的 processElement 只读方法,用来拉宽操作
- 获取数据+关联数据(判非空后收集)
- 3- BroadcastProcessFunction 方法中重写的 processBroadcastElement 可修改方法,
- 读取 state 数据:getBroadcastState()
- 删除历史数据:clear()
- 将新的实例添加到广播状态中:putAll()
3.4.4 BroadcastState 执行思路梳理




![[嵌入式系统-37]:龙芯1B 开发学习套件 -6-协处理器CP0之CPU异常处理与外部中断控制器的中断处理](https://img-blog.csdnimg.cn/direct/897bb684e81a4c3497a7910b5bbd7c74.png)