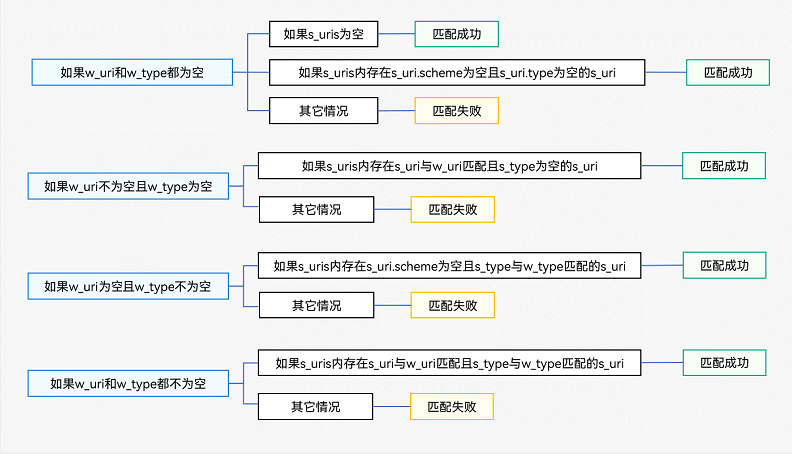
从理论分析入手把握大规模神经网络优化的规律,可以指导实践中的超参数选择。反过来,实践中的超参数选择也可以指导理论分析。本篇文章聚焦于大语言模型,介绍从 GPT 以来大家普遍使用的训练超参数的变化。
规模律研究的是随着神经网络规模的增大,超参数、性能是如何改变的。规模律是对模型、数据、优化器关系的深刻刻画,揭示大模型优化时的普遍规律。通过规模律,我们可以用少量成本在小模型上验证超参数的选择和性能的变化情况,继而外推到大模型上。
在 LLM 中规模性常常变换模型大小和数据规模,进行大量调参而保持优化器不变。故对于大模型优化器而言,规模性是其性能很好的展现(性能上限)。设计更好的优化器(用更少的数据达到相同的性能)就是在挑战现有的规模律。
图片
超参最佳实践
我们首先回顾从 GPT 以来重要文章中使用的超参数,本文将不同模型的超参数列举在下方。首先,除了 Google 的 T5, PaLM 外,其它的模型都是用了 Adam 类的优化器(Adam 或 AdamW)。其次,超参数选择上的更新都是在前人的基础上慢慢变化,并被后续采纳的。这包括使用 dropuout、梯度范数裁剪(Megatron-LM),批量的动态变化(GPT-3),Adam (GPT-3)。
学习率:我们发现随着模型的增大,学习率越来越小。学习率与数据量、批量大小都没有明显的关系,且一般使用 左右的学习率。学习率的变化策略都包括 warmup 和衰减(decay)两阶段。目前普遍使用 GPT-3 中余弦衰减到原学习率的十分之一。谷歌则倾向于使用平方根衰减(优点之一在于不用提前知道训练步数)。
批量大小:训练使用的批量大小随着模型的增大也在不断增大,从 GPT 的 32k、BERT 的 128k,到 GPT-3 的 3.2M、LLaMA 的 4M。值得注意的是,GPT-3 的批量大小是从 32k 开始,在 12B tokens 的训练中逐渐增加到 4M 的,批量大小增加了 125 倍。
OpenAI 在论文中认为随着学习的进行,模型能够承载的批量大小快速增加。而后续很多工作直接使用了更大的批量。这可能是批量增大的过程只占总数据的 2%,即使直接使用最大批量也不会造成太大的问题。
权重衰减 /L2 正则化:在 L2 正则化(或 weight decay)上,GPT 与 BERT 都使用了正则化,后续的模型有些使用而有些没有使用。首先注意到,在 GPT 和 BERT 时代,数据量还是大于模型参数量的(over-parameterized),训练时也是使用多轮训练(multi-epoch)。
而随着人们意识到数据的重要性,数据量已经超越模型的参数量的(GPT3, 680B tokens, 175B params, under-parameterized),训练时也只使用了一轮训练(single-epoch)。根据 [ADV+23] 中的分析,在 over-parameterized 网络中使用 weight decay 相当于对优化器施加了潜在的正则;而在 under-parameterized 网络中,weight decay 只是改变了实际的学习率。随着网络训练权重的变化,相当于施加了自适应的学习率变化策略。
在本文的最后列举了不同模型的超参选择。其中 Adam 括号中的数字代表 ,sch 为学习率调整策略,bs为批量大小,L2 为权重衰减的 权重,init 为初始化方法。
图片
神经网络规模律
神经网络规模律(neural scaling laws)通过廉价的小规模实验来预测大规模模型的表现,从而决定最佳的架构、算法、数据集、超参数等等。从广义上讲所有因素都可以研究:模型的宽度,数据数量,计算资源(FLOPs)等等。
图片
上图是强化学习中的一些例子,黑色点为实验数据,红色线为拟合的规模律,绿色点为验证数据。可以看到,如果规模律的拟合效果好,就可以用来预测大规模模型的表现。除了上述单调的规模律,还有一些非单调的规模律,如下图所示。Tranformer 的性能随着模型的宽度增加先增加后减小最后再增加。
图片
神经网络规模律的研究重点之一在于研究什么样的曲线能够拟合上述现象。一个简单的拟合策略是使用 ,这可以对付不少情况,然而无法应对上述非单调的情况。[CGR+23] 提出了自己的拟合曲线 BNSL(broken neural scaling laws)
图片
其中 对应横坐标,其它参数为拟合参数。其中, 代表了曲线由 段组成,当 时就是 。大家不用纠结于公式的具体形式,该公式只是希望“大包大揽”,把所有可能的规模性都考虑进来。这个公式允许出现下图中所示的三种变化方式,具有很高的灵活性。
图片
图片
大语言模型规模律
讨论大语言模型规模律最重要的两篇可以说是 OpenAI 的 [KMH+20] 和 DeepMind 的 Chinchilla[HBM+22] 了。我们将主要介绍这两篇文章的结论。
定义 为模型参数量, 为数据量, 为计算量(FLOPs), 为损失值。超参数分为优化超参数(学习率等)和架构超参数(如深度、宽度)。 为批量大小, 为训练步数,对于单轮训练,。其中对于大语言模型,确定 和 大小后,就可以估算出 。
实际中我们拥有的计算量为 时,为了获得最低的损失 ,我们希望通过选择 和 使得 最小。记 为给定计算量下最佳的 ,即
图片
- 模型性能与 密切相关,与架构超参数关系不大。
- L 与 成幂律分布(Power-law),即 。
图片
这里 指的是在给定 下的最佳性能,即最低的损失值。该规律的前提条件是不受另外两个因素制约。由于 ,该规律最终会失效,但 [KMH+22] 的实验规模使我们看不到这一点。
3. 给定计算量后, 。
该结论即当模型参数翻倍后,数据量也应该翻倍从而得到最优性能。这是 [HBM+22] 中对 [KMH+20] 主要纠正的结论。下图中黑色虚线为 [KMH+20] 的结论,其它三色线是 [HBM+22] 用三个方法得出的相同结论,并且根据该放缩率训练了 Chinchilla 模型。
图片
在 [KMH+20] 中,作者认为模型增大 5 倍,数据量增大 8 倍。[HBM+22] 认为两个因素导致了[KMH+20] 中的错误:
对不同的 没有尝试使用不同的学习率调整策略(正确的学习率调整策略对训练影响很大)
[KMH+20] 使用的 较小。规模性存在曲率,导致用太小的 得到的结论不准确。(规模性存在曲率也说明了最终该规律会失效)
图片
这里展式 [HBM+20] 中的一种论证,即绘制相同 下不同 与最优 的关系,从而得到最优配置。
图片
Chinchilla 规模律的最终拟合结果如下,通过代入 我们可以计算得到述 的取值,并可以揭示数据与模型规模应该同时增加的规律。此外,在 Chinchilla 的设置下,。
图片
4. 临界批量大小 ,与其它因素弱相关。
临界批量大小在大规模神经网络优化:批量与噪声中有过介绍,可以理解为使用相同 可以达到相同 的最大 。在 [KMH+20] 中,拟合得到 。 约小可以用的批量越大也解释了上文 GPT-3 模型中批量大小的增大。
图片
另一方面,训练损失随着训练步数呈现快速下降-线性-平坦三个阶段的特点(见下图 Llama 训练图)。由于训练早期训练损失的快速下降,临界批量大小又随损失幂律下降,可见临界批量大小随训练步数下降的很快。我们用将 llama 的损失带入计算,当训练的非常前期损失就能下降到 2.2,临界批量大小 4.7M,这与 llama 使用的 4M 批量大小吻合。这也解释了为什么可以省略掉批量大小的调整。
图片
如果损失能够下降到 1.5,临界批量大小就会增加到 30M,所以 llama 可以在训练中进一步增加批量大小的使用。按此推断,GPT-4 最终使用了 60M 的批量大小,对应的训练损失可能为 1.3。
5. 模型的迁移泛化能力与在训练数据集上的泛化能力正相关。
如右图所示,在训练数据集上的测试损失越低,则在其它数据集上的损失也越低(如训练在 Wikipedia,测试在 WebText2)。右图则显示随着参数量增大,模型的测试损失越低。且在不同数据集上的测试损失与在训练集上的测试测试损失仅仅相差一个常数偏移。
图片
- 更大的模型收敛更快(更少的数据量达到相同的损失)
下图中越亮的线代表更大的模型。左图说明达到相同的测试损失,使用大模型需要见到的数据量更少。右图中则是使用相同计算量的比较。两条线的交点分割了使用大小模型的优劣:在交点左侧应该使用小模型,在交点右侧应该使用大模型。
图片
图中另外一个重要的观察是,训练后期损失下降的更慢。故与其训练一个小模型到收敛,不如用相同的资源训练一个不到收敛的大模型更加高效。
图片
大语言模型规模律拾遗
除了上述两篇经典文章之外,不少文章也给出了自己的洞见。
3.1 涌现是指标选择的结果,连续指标与参数规模符合幂律分布
涌现现象指的是模型的某些性能随着模型参数增加到一定规模突然不可预测的快速提升。这被认为是大模型能力的重要体现。这里我们研究的是指标性能与模型参数的关系,也是一种规模律。
图片
[SMK23] 论文则指出,大部分所谓的涌现现象,都出现在两种指标上:多选题的正确性,以及完全字符串匹配正确性。更换指标可以更好的对模型能力的规模性进行预测。
上文中我们已经知道,模型损失值随模型参数指数下降(图A),从而可以得到单个样本预测的正确率指数上升(图B)。如果将非线性指标“完全字符串匹配正确率”替换为“错误预测的 Token 数”,可以发现同样的幂律分布。同理,将不连续的选择正确率替换为连续的选择正确率,也可以得到幂律分布。
图片
笔者认为,这篇文章不应该看做对”涌现“重要性的否定。在现实世界、生活、市场中,我们关心的指标就是非线性,或者说非连续指标。这篇文章的意义在于,我们可以用连续指标更好的建模规模律,从而预测非连续指标的变化。同时,这也揭示了大模型中”量变产生质变“的背后机理,并不需要用“整体的复杂交互”进行解释。
3.2 大模型需要更小的学习率
通过上文中的大模型参数经验,我们很容易就发现大模型需要更小的学习率。[YHB+22] 在下左图中展示了这点。其认为这是为了控制总方差在一定值(方差随参数量以 增大)。对于这点笔者暂未找到详细的理论解释。[YHB+22] 中还提出了一种新的初始化和参数设置方法以保证不同规模的模型可以使用相同的学习率,这里不再展开。
图片
3.3 使用重复数据训练时(multi-epoch),应该用更多的轮次训练较小的模型
[MRB+23] 探究了当数据有限时,如何训练大模型。左图中,当轮次小于 4 时,与使用新数据效果相当(GPT-4 中重复了文本两次,代码四次,与该结果印证)。当轮次大于 40 次时,则几乎没有提升。右图中,用左图的拟合结果可以计算得到,相比于 Chinchilla 的规模性,使用重复数据训练时,应该用更多的数据(重复数)训练较小的模型。
图片
3.4 使用重复数据训练对训练帮助很小
[XFZ+23] 进行了大量的实验验证了一系列观点。下左图中,作者在 Encoder-Decoder 模型上验证了 Chinchilla 规模律同样成立(即数据量与模型参数量应该同时增加)。右图则显示了使用出发数据训练对性能没有帮助。文中还尝试了高质量数据、UL2 训练目标、不同的正则化方法,最终发现除了 Dropout 之外对重复训练都没有帮助。
图片
3.5 训练比 Chinchilla 规模律更小的模型
Chinchilla 规模律的出发点是给定计算量,通过分配参数量和数据量最小化损失值。换言之,给定要达到的损失值,最小化计算量。然而在实际中,训练一个小模型能带来计算量(代表训练开销)以外的收益:
小模型部署后进行推理成本更小
小模型训练所需的集群数量更少
故 [H23] 提出,在不大幅度增加训练开销的前提下,尽可能减小模型的参数量。具体而言,作者在 Chinchilla 规模律的基础上,让模型的参数量变为 ,进而计算出达到相同损失所需的数据量 。通过推导可得 与 无关,即无论训练开销多大, 与 的关系都是一致的。下图展示了计算量的增加值 与 的关系。
图片
其中,LLaMA-7B 就比 Chinchilla 中对应的最优解使用了更小的模型和更多的计算量(数据)。由于参数量减小到一定程度,需要的计算量会有急剧的上升,作者认为模型的大小不应该小于临界模型大小。譬如当使用 30% 的参数量时,所需计算量会增加 100%。参数量不应该再继续减小(否则计算量会上升很多)。
在 Llama-2 上我们也能看到类似的现象。根据 Chinchilla 规模性,2T 数据对应大约 50B 的参数量。所以对于 Llama-2-7b 来说,训练了一个相对更小的模型。而对于 Llama-2-70b 来说,则不够效率。
图片
Werra 认为我们应该用更多的数据继续训练更小的模型。这其中的难点在于:
训练所需的数据量不够(正如 [XFZ+23] 指出的,我们正在用尽互联网上所有的 tokens)。
小集群上训练小模型需要更长的训练时间(Llama2 500k its);如果使用大集群训练则更困难(比如要使用更大的批量大小才能提高效率)。
图片
LLM 的超参选择
4.1 GPT(117M):
Adam
lr:2.5e-4
sch: warmup linear 2k, cosine decay to 0
bs: 32k=64x512
its: 3M (100e)
L2: 0.01
init: N(0, 0.02)
4.2 BERT(330M):
Adam(0.9,0.999)
lr: 1e-4
sch: warmup 10k, linear decay to 0
bs: 128k=256x512
its: 1M (40e)
L2: 0.01
dropout: 0.1
4.3 Megatron-LM(GPT2 8.3B & Bert 3.9B):
Adam
lr: 1.5e-4
sch: warmup 2k, cosine decay to 1e-5
bs: 512k=512x1024
its: 300k
L2: 0.01
dropout: 0.1
gradient norm clipping: 1.0
init: N(0, 0.02), weights before residual layer
4.4 T5 (11B)
AdaFactor
lr: 1e-2
sch: warmup constant 10k, sqrt decay
bs: 65k=128x512
its: 500k (1e)
4.5 GPT-3
Adam(0.9, 0.95, eps=1e-8)
lr & final bs:
图片
sch: warmup linear 375m tokens, cosine decay to 0.1xlr 260b tokens, continue training with 0.1xlr
bs sch: 32k to final bs gradually in 4-12B tokens
seq length: 2048
data: 680B
gradient norm clipping: 1.0
4.6 Gopher
Adam (Adafactor unstable beyond 7.1B)
lr & final bs:
图片
sch: warmup 1.5k, cosine decay to 0.1xlr
gradient norm clipping: 0.25 for 7.1B & 280B, 1.0 for the rest
4.7 Chinchilla (70B)
AdamW
lr: 1e-4
bs: 1.5M to 3M
others follow Gopher
4.8 OPT
Adam(0.9, 0.95) (SGD plateau quickly)
lr & bs:
图片
sch: warmup linear 2k, decay to 0.1xlr
L2: 0.1
dropout: 0.1
gradient norm clipping: 1.0
init: N(0, 0.006), output layer N(0, 0.006* )
4.9 PaLM
Adafactor(0.9, 1-)
lr 1e-2
sch: warmup 10k, decay at
bs: 1M (<50k), 2M (<115k), 4M (<255k)
L2: lr
dropout: 0.1
gradient norm clipping: 1.0
its: 255kinit: N(0, embedding N(0,1)
4.10 LLaMA (RMSNorm, SwiGLU, RoPE)
AdamW(0.9, 0.95)
lr & bs:
图片
sch: warmup 2k, decay to 0.1xlr
L2: 0.1
gradient norm clipping: 1.0
4.11 LLaMA2
AdamW(0.9, 0.95, eps=1e-5)
lr
图片
sch: warmup 2k, decay to 0.1xlr
L2: 0.1
gradient norm clipping: 1.0