论文:
GPT:Improving Language Understanding by Generative Pre-Training
GTP-2:Language Models are Unsupervised Multitask Learners
GPT-3:Language Models are Few-Shot Learners
参考:GPT、GPT-2、GPT-3论文精读、论文小结:GPT1、李宏毅版GPT、
GPT-1/GPT-2/GPT-3/GPT-3.5 语言模型详细介绍、GPT系列:GPT, GPT-2, GPT-3精简总结
关于Transformer、BERT和GPT的时间轴,如下:

三个模型的对比
一、GPT
GPT的训练过程采用了预训练和微调的二段式训练策略。在预训练阶段,GPT模型基于大规模的语料进行无监督预训练,得到文本的语义向量。具体来说,GPT采用了标准语言模型,即通过上文预测当前的词。
GPT提出的一种半监督方案:
- 非监督式预训练: 利用大规模无标记语料,构建预训练单向语言模型。
- 监督式微调: 用预训练的结果作为下游任务的初始化参数,增加一个线性层,匹配下游任务
- 具体是DecoderTransformer参数用预训练的结果初始化,和词向量相比,直接对句子序列建模。
- 采用的Transormer Decoder, 和原始的Transformer相比,因为不是seq2seq模型,将对应部份的模块去除。
1.1 模型结构

GPT只使用了Transformer 的Decoder结构,而且只是用了Mask Multi-Head Attention。Transformer 结构提出是用于机器翻译任务,机器翻译是一个序列到序列的任务,因此 Transformer 设计了Encoder 用于提取源端语言的语义特征,而用 Decoder 提取目标端语言的语义特征,并生成相对应的译文。GPT目标是服务于单序列文本的生成式任务,所以舍弃了关于 Encoder部分以及包括 Decoder 的 Encoder-Dcoder Attention 层(也就是 Decoder中 的 Multi-Head Atteion)。
GPT保留了Decoder的Masked Multi-Attention 层和Feed Forward层,并扩大了网络的规模。将层数扩展到12层,GPT还将Attention 的维数扩大到768(原来为512),将 Attention 的头数增加到12层(原来为8层),将 Feed Forward 层的隐层维数增加到3072(原来为2048),总参数达到1.5亿。
BERT与GPT的区别
- BERT是用了Transformer中的Encoder部分,它更类似完形填空,根据上下文来确定中间词(在预测词的时候既能看到前面的也能看后面的)
- GPT用了Transformer中Decoder部分,它是标准的语言模型。通过给出的上文预测下一个词,类似预测未来。
对于位置编码的部分,实际上GPT和普通的Transformer的区别还是很大的,普通的Transformer的位置编码,是由余弦+正弦的方式学习出来的,而GPT中,采用与词向量相似的随机初始化,并在训练中进行更新,即是把每一个位置当做一个要学习的embedding来做。
1.2 预训练+微调
GPT属于自监督预训练 (语言模型)+微调的范式。
1.2.1 预训练
- 预训练:用的是标准的语言模型的目标函数,即似然函数,根据前k个词预测下一个词的概率。
假设有一个没有标号的文本,GPT使用一个标准语言模型的目标函数来最大化下面的似然函数:
其中,是上下文窗口大小。
其中,第一步:
是对词嵌入进行投影,
代表位置信息的编码,两者相加得到第一层输出
。第二步:n层第一部的transformer块,每一层把上一层的输出作为输入经过计算得到输出,因为Transformer不会影响输入输出的形状。第三步:拿到最后的输出做一个投影利用softmax就会得到概率分布。
1.2.2 微调
- 微调:用的是完整的输入序列+标签。目标函数=有监督的目标函数+λ*无监督的目标函数。
在微调任务里是有标号的数据集。具体来说,每次输入一个长为m的词序列,序列的标号为
。通过输入的序列去预测标号
。
把训练好的序列给GPT模型,拿到transformer快的最后一层输出,乘以输出层
,得到的结果做一个softmax就得到所需要的概率了。
把所有带有标号的序列对输入后,通过计算真实的标号概率,最后进行最大化。
如果把有监督的分类和之前的无监督语言模型放在一起,效果会更好。
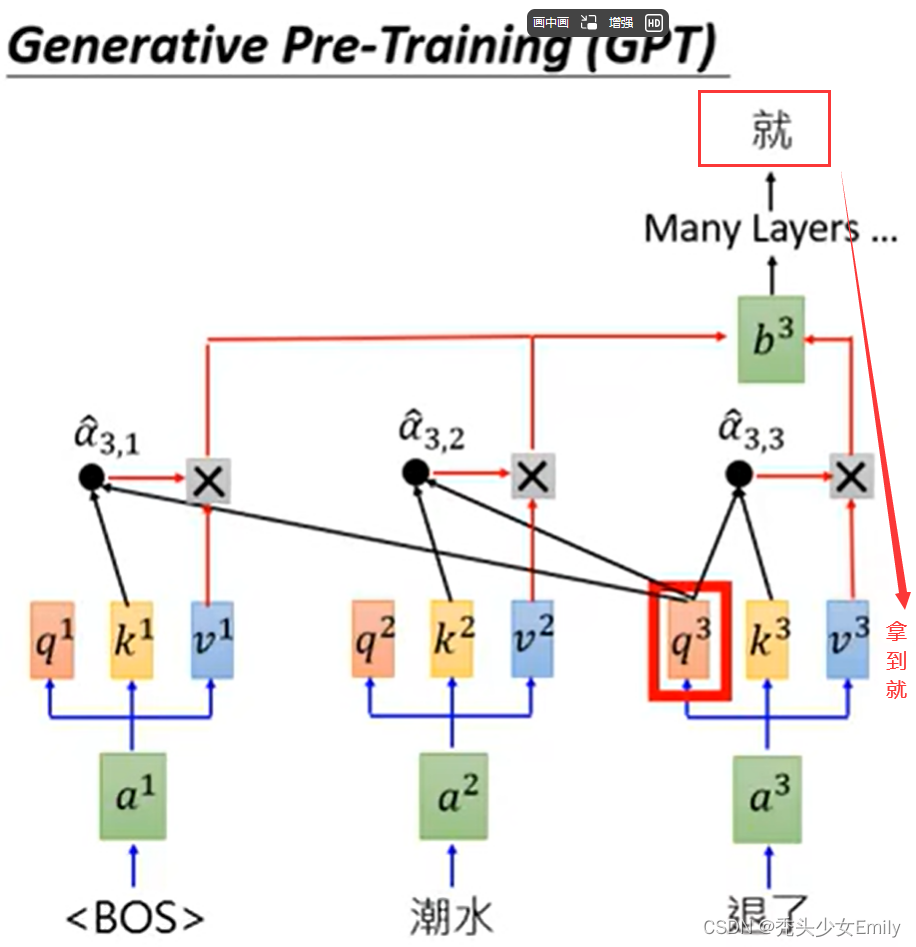
1.3 不同下游任务的输入转换
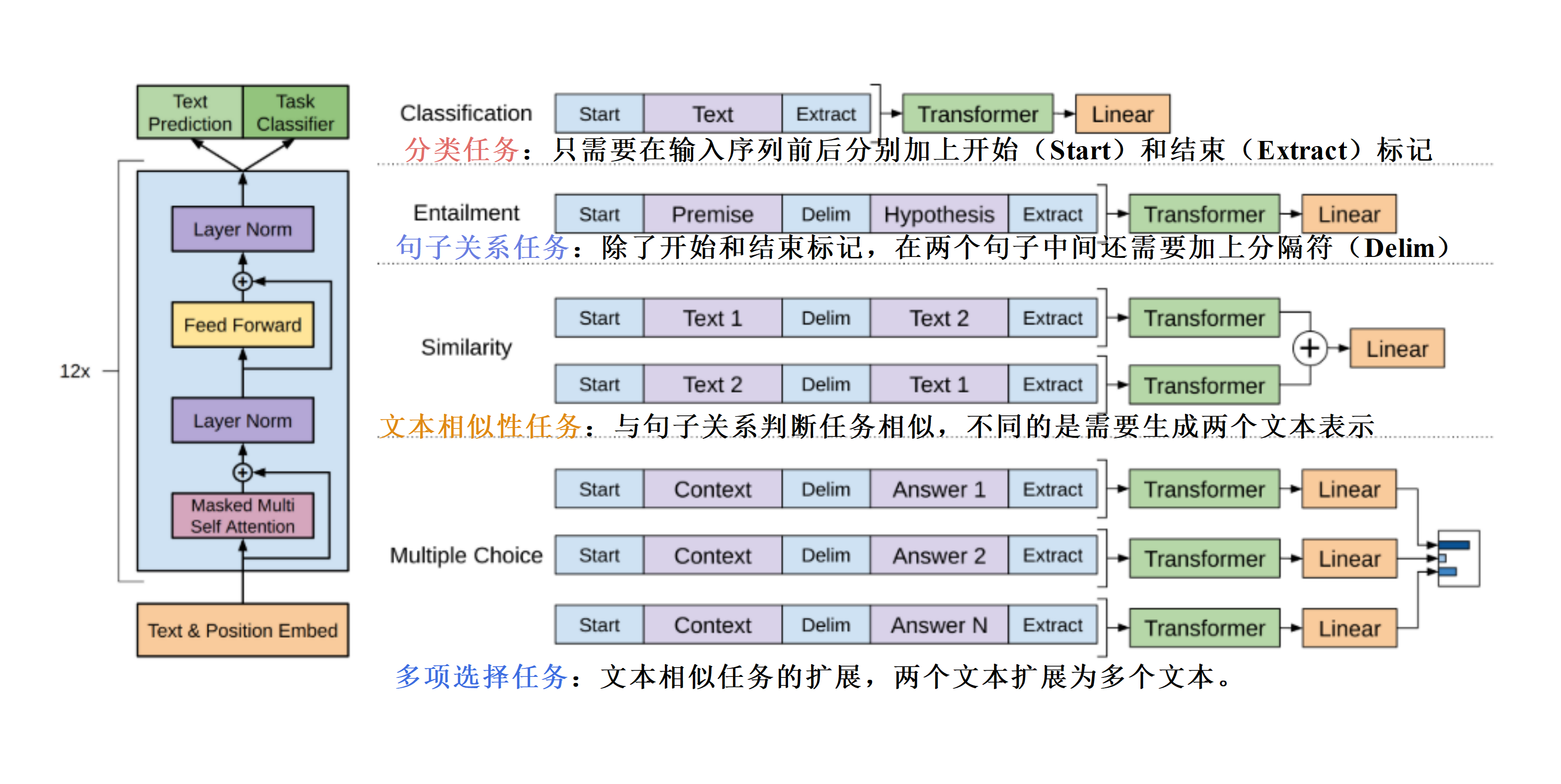
GPT的Decoder运作例子

二、GPT-2
GPT-2与GPT的区别:
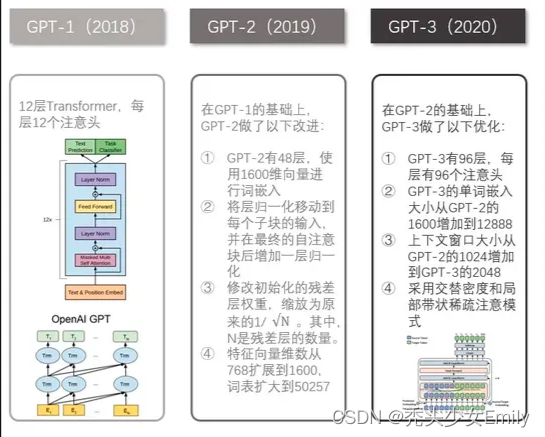
GPT-2和GPT的区别在于GPT-2使用了更多的网络参数和更大的数据集,以此来训练一个泛化能力更强的词向量模型。GPT-2相比于GPT有如下几点区别:
- 主推zero-shot,而GPT-1为pre-train+fine-tuning;
- 模型更大,参数量达到了15亿个,而GPT-1只有1.17亿个;
- 数据集更大,WebText数据集包含了40GB的文本数据,而GPT-1只有5GB;
- 训练参数变化,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024;
所以GPT-2的核心思想就是,当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。
2.1 模型结构
在模型结构方面,整个GPT-2的模型框架与GPT相同,只是做了几个地方的调整,这些调整更多的是被当作训练时的trick,而不作为GPT-2的创新,具体为以下几点:
- 后置层归一化( post-norm )改为前置层归一化( pre-norm );
- 在模型最后一个自注意力层之后,额外增加一个层归一化;
- 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为;
- 输入序列的最大长度从 512 扩充到 1024;
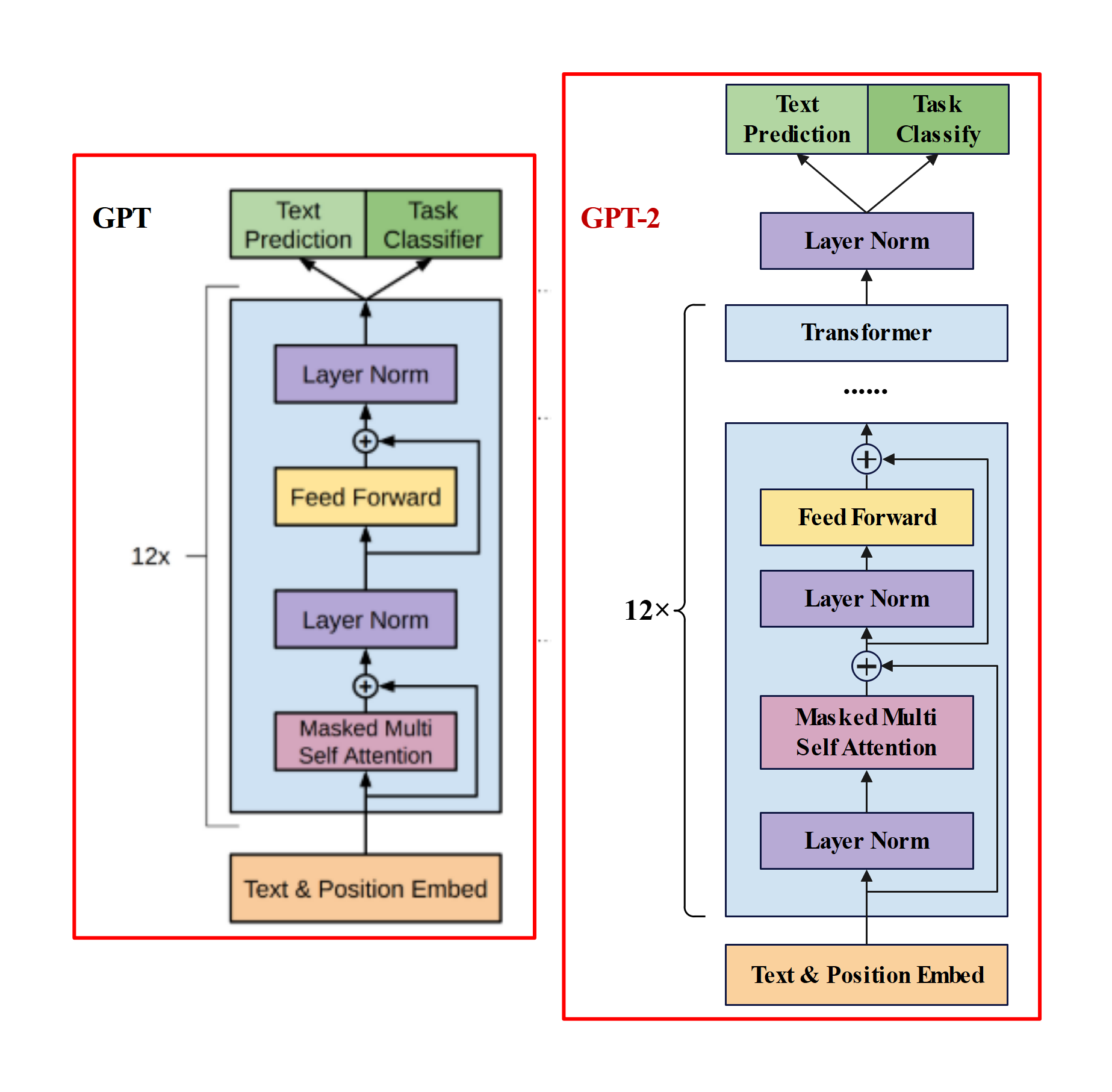
GPT-2 进行上述模型调整的主要原因在于,随着模型层数不断增加,梯度消失和梯度爆炸的风险越来越大,这些调整能够减少预训练过程中各层之间的方差变化,使梯度更加稳定。最终 GPT-2 提供了四种规模的模型。
2.2 预训练+zero-shot
预训练和GPT基本没什么区别,但是对下游任务用了zero-shot。
- GPT-2可以在zero-shot设定下实现下游任务,即不需要用有标签的数据再微调训练。
- 为实现zero-shot,下游任务的输入就不能像GPT那样在构造输入时加入开始、中间和结束的特殊字符,这些是模型在预训练时没有见过的,而是应该和预训练模型看到的文本一样,更像一个自然语言。
- 可以通过做prompt的方式来zero-shot。例如机器翻译和阅读理解,可以把输入构造成,“请将下面的一段英语翻译成法语,英语,法语”。
- 为何zero-shot这种方式是有效的呢?从一个尽可能大且多样化的数据集中一定能收集到不同领域不同任务相关的自然语言描述示例,数据集里就存在展示了这些prompt示例,所以训练出来就自然而然有一定zero-shot的能力了。
2.2.1 zero-shot
在GPT中,模型预训练完成之后会在下游任务上微调,在构造不同任务的对应输入时,我们会引入开始符(Start)、分隔符(Delim)、结束符(Extract)。虽然模型在预训练阶段从未见过这些特殊符号,但是毕竟有微调阶段的参数调整,模型会学着慢慢理解这些符号的意思。
在GPT-2中,要做的是zero-shot,也就是没有任何调整的过程了。这时我们在构造输入时就不能用那些在预训练时没有出现过的特殊符号了。所幸自然语言处理的灵活性很强,我们只要把想要模型做的任务 “告诉” 模型即可,如果有足够量预训练文本支撑,模型想必是能理解我们的要求的。
举个机器翻译的例子,要用GPT-2做zero-shot的机器翻译,只要将输入给模型的文本构造成translate english to chinese, [englist text], [chinese text] 就好了。比如:translate english to chinese, [machine learning], [机器学习] 。这种做法就是日后鼎鼎大名的prompt。
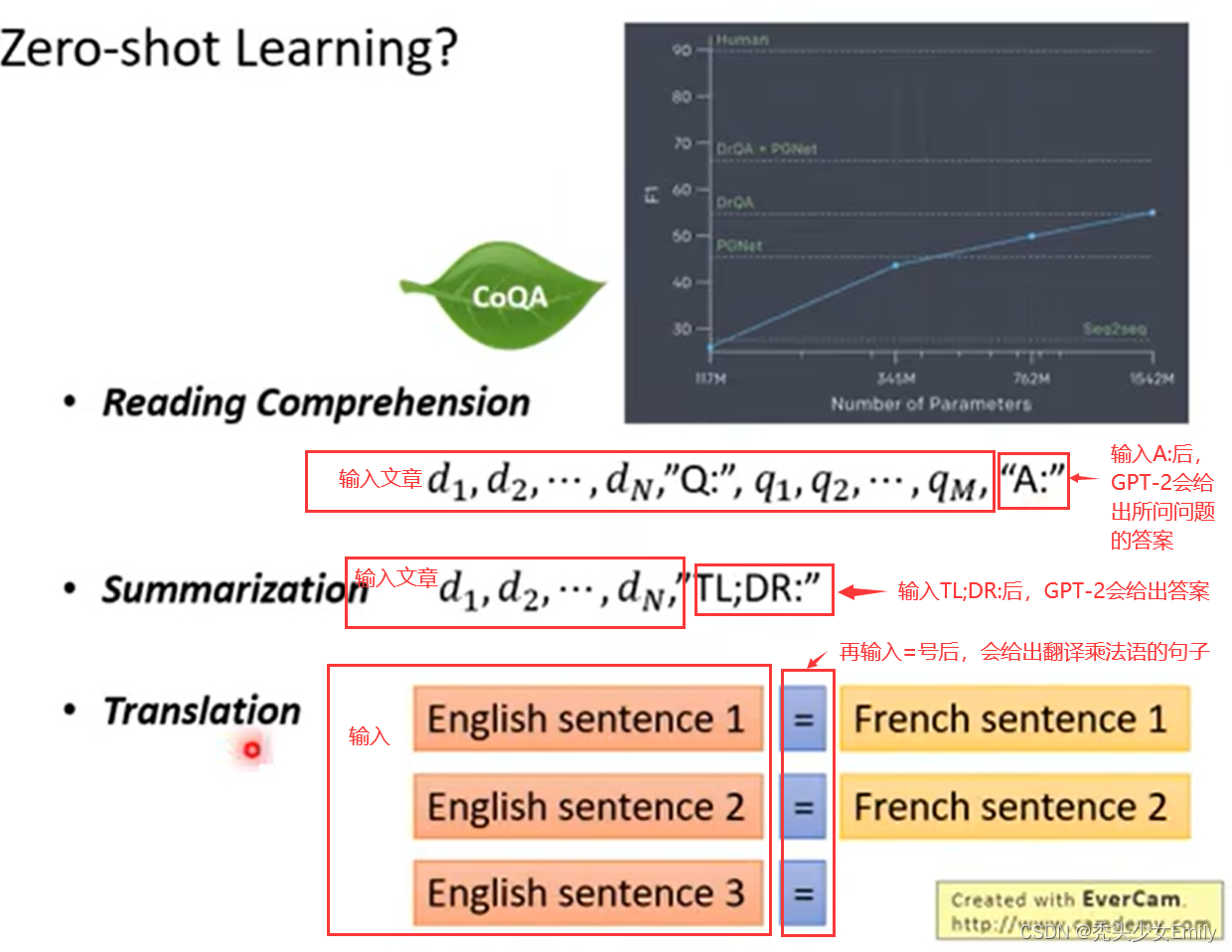
下面还有其他任务的zero-shot形式:
问答:question answering prompt+文档+问题+答案: answer the question, document, question, answer。
文档总结:summarization prompt+文档+总结:summarize the document, document, summarization。
zero-shot例子(这就可以看到ChatGPT雏形了):
三、GPT-3
GPT-2虽然提出zero-shot,比bert有新意,但是有效性方面不佳。GPT-3考虑few-shot,用少量文本提升有效性。
GPT-3希望训练出的模型能一定程度上理解语句本身的意思,所以对于下游问题,不更新原训练出模型的参数(不用计算梯度),而是通过改变下游问题的格式,给出提示,让模型能够理解下游任务并做出回答。
3.1 模型结构
- GPT基于transformer的decoder结构。
- GPT-3模型和GPT-2一样,但GPT-3应用了Sparse Transformer中的attention结构。
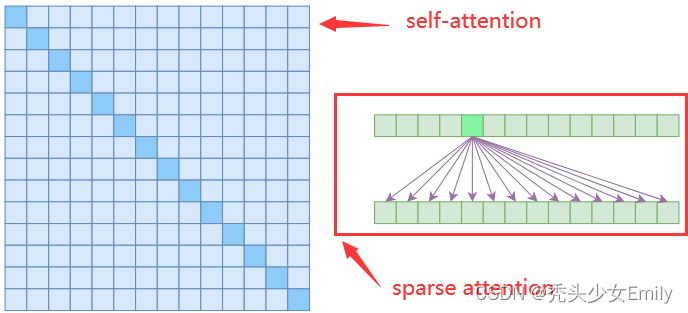
sparse attention与传统self-attention(称为 dense attention)的区别在于:
- dense attention:每个token之间两两计算attention,复杂度 O(n²)
- sparse attention:每个token只与其他token的一个子集计算attention,复杂度 O(n*logn)
具体来说,sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,... 的 token,其他所有 token 的注意力都设为 0,如下图所示:
实际途中sparse attention部分的第二行就是涉及到的attention的token内容,可以看出首先关注了附近四个token,其次是2k,3k距离的token。
使用sparse attention的好处主要有以下两点:
- 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
- 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
3.2 预训练+few-shot
3.2.1 few-shot
论文尝试了如下下游任务的评估方法:few-shot learning(10-100个小样本);one-shot learning(1个样本);zero-shot(0个样本);其中few-shot效果最佳。
- fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数
- zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数
- one-shot:预训练 + task description + example + prompt,预测。不更新模型参数
- few-shot(又称为in-context learning):预训练 + task description + examples + prompt,预测。不更新模型参数
zero-shot、one-shot和few-shot的区别:



其中 Few-shot 也被称为in-context learning,虽然它与fine-tuning一样都需要一些有监督标注数据,但是两者的区别是:
- fine-tuning基于标注数据对模型参数进行更新,而 in-context learning 使用标注数据时不做任何的梯度回传,模型参数不更新;
- in-context learning 依赖的数据量(10~100)远远小于fine-tuning一般的数据量;
3.3 GPT-3与GPT-2的区别
- 模型结构上来看,在GPT-2的基础上,将attention改为了sparse attention。
- 效果上远超GPT-2,生成的内容更为真实。
- GPT-3主推few-shot,而GPT-2主推zero-shot。
- 数据量远大于GPT-2:GPT-3(45T,清洗后570G),GPT-2(40G)。
- GPT-3最大模型参数为1750亿,GPT-2最大为15亿。
3.4 GPT-3的局限性
- 数据量和参数量的骤增并没有带来智能的体感。从参数量上看,从GPT2 1.5B到GPT3 175B约116倍参数量的增加,从数据量上看,GPT2 40G到GPT3 570G近15倍训练数据增加,带来的“更”智能,或者简单点说“更few/zero-shot”的能力。
- GPT-3的训练数据是从互联网上爬取的,因此可能存在一些错误或不准确的数据。
- GPT-3在处理某些任务时可能会出现错误或不准确的结果,以及不合理或不合逻辑的结果。
- 文本生成方面;结构和算法上的局限性(采用的是decoder,不像BERT可以向前向后看)。
- 样本有效性不够 。
- 语言模型是很均匀的训练下一个词,没有权重。