如何使用 UMAP 降维来显示多个评估问题及其与 Ragas、OpenAI、Langchain 和 ChromaDB 的源文档的关系
检索增强生成(RAG)在工作流中增加了一个检索步骤LLM,使其能够在回答问题和查询时从其他来源(如私人文档)查询相关数据[1]。此工作流程不需要昂贵的培训或对其他文档进行微调LLMs。文档被拆分为多个片段,然后通常使用紧凑的 ML 生成的向量表示(嵌入)对这些片段进行索引。在此嵌入空间中,具有相似内容的片段将彼此靠近。
RAG 应用程序将用户提供的问题投影到嵌入空间中,以根据它们与问题的距离检索相关文档片段。LLM可以使用检索到的信息来回答查询,并通过将片段作为参考来证实其结论。

维基百科一级方程式文章的 UMAP [3] 降维迭代的动画,在嵌入空间中带有手动标记的集群 — 由作者创建。
RAG应用的评估具有挑战性[2]。存在不同的方法:一方面,有些方法必须由开发人员提供作为基本事实的答案;另一方面,答案(和问题)也可以由另一个 LLM.Ragas [4](Retrieval-Augmented Generation Assessment)是最大的开源应答系统LLM之一,它提供
- 基于文档生成测试数据的方法和
- 基于不同指标的评估,用于逐个和端到端地评估检索和生成步骤。
在本文中,您将了解
- 如何简要构建一级方程式赛车的 RAG 系统(详见上一篇文章可视化 RAG 数据 — EDA for Retrieval-Augmented Generation)
- 生成问题和答案
- 使用 Ragas 评估 RAG 系统
- 最重要的是如何使用 Renumics Spotlight 可视化结果并解释结果。
该代码可在 Github 上找到
准备好您的环境
启动笔记本并安装所需的 python 包
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">!pip install langchain langchain-openai chromadb renumics-spotlight
%env OPENAI_API_KEY=<your-api-key></span></span></span></span>本教程使用以下 python 包:
- Langchain:一个集成语言模型和 RAG 组件的框架,使设置过程更加顺畅。
- Renumics-Spotlight:一种可视化工具,用于以交互方式探索非结构化 ML 数据集。
- Ragas:一个帮助您评估 RAG 管道的框架
免责声明:本文作者也是 Spotlight 的开发者之一。
为数据集准备文档和嵌入
您可以使用自己的 RAG 应用程序,跳到下一部分以了解如何评估、提取和可视化。
或者,您可以将上一篇文章中的 RAG 应用程序与我们准备好的维基百科所有一级方程式文章的数据集一起使用。在那里,您还可以将自己的文档插入到“docs/”子文件夹中。
该数据集基于维基百科上的文章,并根据知识共享署名-相同方式共享许可获得许可。原始文章和作者列表可以在相应的维基百科页面上找到。
现在,您可以使用 Langchain DirectoryLoader 从 docs 子目录加载所有文件,并使用 RecursiveCharacterTextSpliter .您可以使用 OpenAIEmbeddings 创建嵌入并将它们存储在 ChromaDB 作为向量存储中。对于链本身,您可以使用 LangChains ChatOpenAI 和 ChatPromptTemplate .
本文的链接代码包含所有必要的步骤,您可以在上一篇文章中找到上述所有步骤的详细说明。
重要的一点是,您应该使用哈希函数为 ChromaDB 中的代码段创建 ID。如果您只有包含其内容和元数据的文档,则允许在数据库中找到嵌入。这样就可以跳过数据库中已存在的文档。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">import</span> hashlib
<span style="color:#aa0d91">import</span> json
<span style="color:#aa0d91">from</span> langchain_core.documents <span style="color:#aa0d91">import</span> Document<span style="color:#aa0d91">def</span> stable_hash_meta(<span style="color:#5c2699">doc: Document</span>) -> <span style="color:#5c2699">str</span>:<span style="color:#c41a16">"""Stable hash document based on its metadata."""</span><span style="color:#aa0d91">return</span> hashlib.sha1(json.dumps(doc.metadata, sort_keys=<span style="color:#aa0d91">True</span>).encode()).hexdigest()...
splits = text_splitter.split_documents(docs)
splits_ids = [{<span style="color:#c41a16">"doc"</span>: split, <span style="color:#c41a16">"id"</span>: stable_hash_meta(split.metadata)} <span style="color:#aa0d91">for</span> split <span style="color:#aa0d91">in</span> splits
]existing_ids = docs_vectorstore.get()[<span style="color:#c41a16">"ids"</span>]
new_splits_ids = [split <span style="color:#aa0d91">for</span> split <span style="color:#aa0d91">in</span> splits_ids <span style="color:#aa0d91">if</span> split[<span style="color:#c41a16">"id"</span>] <span style="color:#aa0d91">not</span> <span style="color:#aa0d91">in</span> existing_ids]docs_vectorstore.add_documents(documents=[split[<span style="color:#c41a16">"doc"</span>] <span style="color:#aa0d91">for</span> split <span style="color:#aa0d91">in</span> new_splits_ids],ids=[split[<span style="color:#c41a16">"id"</span>] <span style="color:#aa0d91">for</span> split <span style="color:#aa0d91">in</span> new_splits_ids],
)
docs_vectorstore.persist()</span></span></span></span>评估问题
对于像一级方程式这样的常见话题,也可以直接使用 ChatGPT 来生成一般问题。在本文中,使用了四种问题生成方法:
- GPT4:使用 ChatGPT 4 生成了 30 个问题,提示如下“写 30 个关于一级方程式的问题”
– 随机示例:“哪支一级方程式车队以其跃马标志而闻名? - GPT3.5:ChatGPT 3.5 生成了另外 199 个问题,提示“写 100 个关于一级方程式的问题”并重复“谢谢,请再写 100 个”
– 示例:“”哪位车手在 1950 年赢得了首届一级方程式世界锦标赛? - Ragas_GPT4:使用 Ragas 生成了 113 个问题。Ragas 再次利用文档和自己的嵌入模型来构建一个向量数据库,然后用于使用 GPT4 生成问题。
– 示例:“您能告诉我更多关于 Jordan 198 F1 赛车在 1998 年世界锦标赛中的表现吗? - Rags_GPT3.5:Ragas 生成了 226 个额外的问题——这里我们使用 GPT3.5
– 示例:“2014 年比利时大奖赛上发生了什么事件导致汉密尔顿退出比赛?
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">from</span> ragas.testset <span style="color:#aa0d91">import</span> TestsetGeneratorgenerator = TestsetGenerator.from_default(openai_generator_llm=<span style="color:#c41a16">"gpt-3.5-turbo-16k"</span>, openai_filter_llm=<span style="color:#c41a16">"gpt-3.5-turbo-16k"</span>
)testset_ragas_gpt35 = generator.generate(docs, <span style="color:#1c00cf">100</span>)</span></span></span></span>问题和答案未经任何审查或修改。所有问题都与列 id 、 question 、 ground_truth 和 question_by answer 合并到一个数据框中。

接下来,将向 RAG 系统提出问题。对于超过 500 个问题,这可能需要一些时间并产生成本。如果您逐行提出问题,您可以暂停并继续该过程或从崩溃中恢复,而不会丢失到目前为止的结果:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">for</span> i, row <span style="color:#aa0d91">in</span> df_questions_answers.iterrows():<span style="color:#aa0d91">if</span> row[<span style="color:#c41a16">"answer"</span>] <span style="color:#aa0d91">is</span> <span style="color:#aa0d91">None</span> <span style="color:#aa0d91">or</span> pd.isnull(row[<span style="color:#c41a16">"answer"</span>]):response = rag_chain.invoke(row[<span style="color:#c41a16">"question"</span>])df_questions_answers.loc[df_questions_answers.index[i], <span style="color:#c41a16">"answer"</span>] = response[<span style="color:#c41a16">"answer"</span>]df_questions_answers.loc[df_questions_answers.index[i], <span style="color:#c41a16">"source_documents"</span>] = [stable_hash_meta(source_document.metadata)<span style="color:#aa0d91">for</span> source_document <span style="color:#aa0d91">in</span> response[<span style="color:#c41a16">"source_documents"</span>]]
</span></span></span></span>不仅存储答案,还存储检索到的文档片段的源 ID 及其文本内容作为上下文:

此外,所有问题的嵌入也会生成并存储在数据帧中。这允许将它们与文档一起可视化。
使用 Ragas 进行评估
Ragas 提供了用于单独评估 RAG 管道的每个组件的指标,以及整体性能的端到端指标:
- 上下文精度:使用
question和 检索contexts来测量信噪比。 - 上下文相关性:衡量检索到的上下文与问题的相关性,使用
question和contexts计算。 - 上下文调用:基于
ground truth和contexts检查是否检索到答案的所有相关信息。 - 忠实度:利用
contexts和answer来衡量生成的答案的事实准确性。 - 答案相关性:使用
question和answer计算,以评估生成的答案与问题的相关性(不考虑事实性)。 - 答案语义相似性:使用
ground truth和answer进行评估,以评估生成的答案与正确答案之间的语义相似性。 - 答案正确性:依靠
ground truth和answer来衡量生成的答案与正确答案的准确性和对齐。 - 方面批评:涉及分析
answer以根据预定义或自定义方面(例如正确性或有害性)评估提交的内容。
目前,我们专注于答案正确性的端到端指标。根据 Ragas API 复制和调整数据帧中的列名和内容,以满足命名和格式要求:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># prepare the dataframe for evaluation</span>
df_qa_eval = df_questions_answers.copy()<span style="color:#007400"># adapt the ground truth to the ragas naming and format</span>
df_qa_eval.rename(columns={<span style="color:#c41a16">"ground_truth"</span>: <span style="color:#c41a16">"ground_truths"</span>}, inplace=<span style="color:#aa0d91">True</span>)
df_qa_eval[<span style="color:#c41a16">"ground_truths"</span>] = [[gt] <span style="color:#aa0d91">if</span> <span style="color:#aa0d91">not</span> <span style="color:#5c2699">isinstance</span>(gt, <span style="color:#5c2699">list</span>) <span style="color:#aa0d91">else</span> gt <span style="color:#aa0d91">for</span> gt <span style="color:#aa0d91">in</span> df_qa_eval[<span style="color:#c41a16">"ground_truths"</span>]
]</span></span></span></span>这再次需要一些时间,甚至比仅仅查询您的 RAG 系统还要多。让我们逐行应用评估,以便能够从崩溃中恢复,而不会丢失到目前为止的结果:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># evaluate the answer correctness if not already done</span>
fields = [<span style="color:#c41a16">"question"</span>, <span style="color:#c41a16">"answer"</span>, <span style="color:#c41a16">"contexts"</span>, <span style="color:#c41a16">"ground_truths"</span>]
<span style="color:#aa0d91">for</span> i, row <span style="color:#aa0d91">in</span> df_qa_eval.iterrows():<span style="color:#aa0d91">if</span> row[<span style="color:#c41a16">"answer_correctness"</span>] <span style="color:#aa0d91">is</span> <span style="color:#aa0d91">None</span> <span style="color:#aa0d91">or</span> pd.isnull(row[<span style="color:#c41a16">"answer_correctness"</span>]):evaluation_result = evaluate(Dataset.from_pandas(df_qa_eval.iloc[i : i + <span style="color:#1c00cf">1</span>][fields]),[answer_correctness],)df_qa_eval.loc[i, <span style="color:#c41a16">"answer_correctness"</span>] = evaluation_result[<span style="color:#c41a16">"answer_correctness"</span>]
</span></span></span></span>之后,您可以将结果存储在 DataFrame 中 df_questions_answer :
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">df_questions_answers[<span style="color:#c41a16">"answer_correctness"</span>] = df_qa_eval[<span style="color:#c41a16">"answer_correctness"</span>]</span></span></span></span>准备可视化效果
为了在可视化中包含文档片段,我们将文档中的引用添加到使用文档作为源的问题中。此外,还存储了引用文档的问题计数:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># Explode 'source_documents' so each document ID is in its own row alongside the question ID</span>
df_questions_exploded = df_qa_eval.explode(<span style="color:#c41a16">"source_documents"</span>)<span style="color:#007400"># Group by exploded 'source_documents' (document IDs) and aggregate</span>
agg = (df_questions_exploded.groupby(<span style="color:#c41a16">"source_documents"</span>).agg(num_questions=(<span style="color:#c41a16">"id"</span>, <span style="color:#c41a16">"count"</span>), <span style="color:#007400"># Count of questions referencing the document</span>question_ids=(<span style="color:#c41a16">"id"</span>,<span style="color:#aa0d91">lambda</span> x: <span style="color:#5c2699">list</span>(x),), <span style="color:#007400"># List of question IDs referencing the document</span>).reset_index().rename(columns={<span style="color:#c41a16">"source_documents"</span>: <span style="color:#c41a16">"id"</span>})
)<span style="color:#007400"># Merge the aggregated information back into df_documents</span>
df_documents_agg = pd.merge(df_docs, agg, on=<span style="color:#c41a16">"id"</span>, how=<span style="color:#c41a16">"left"</span>)<span style="color:#007400"># Use apply to replace NaN values with empty lists for 'question_ids'</span>
df_documents_agg[<span style="color:#c41a16">"question_ids"</span>] = df_documents_agg[<span style="color:#c41a16">"question_ids"</span>].apply(<span style="color:#aa0d91">lambda</span> x: x <span style="color:#aa0d91">if</span> <span style="color:#5c2699">isinstance</span>(x, <span style="color:#5c2699">list</span>) <span style="color:#aa0d91">else</span> []
)
<span style="color:#007400"># Replace NaN values in 'num_questions' with 0</span>
df_documents_agg[<span style="color:#c41a16">"num_questions"</span>] = df_documents_agg[<span style="color:#c41a16">"num_questions"</span>].fillna(<span style="color:#1c00cf">0</span>)</span></span></span></span>现在将问题的数据帧与文档的数据帧连接起来
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">df = pd.concat([df_qa_eval, df_documents_agg], axis=<span style="color:#1c00cf">0</span>)</span></span></span></span>此外,让我们准备一些不同的 UMAP [3] 映射。您可以稍后在 Spotlight GUI 中执行相同的操作,但预先执行可以节省时间。
- umap_all:在所有文档和问题嵌入上应用拟合和转换的 UMAP
- umap_questions:UMAP 的拟合仅适用于问题嵌入,转换应用于两者
- umap_docs:UMAP 仅在文档嵌入上应用适合,并在两者上应用转换
我们准备每个 UMAP 转换,如下所示:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">
umap = UMAP(n_neighbors=20, min_dist=0.15, metric=<span style="color:#c41a16">"cosine"</span>, random_state=42).fit
umap_all = umap.transform(<span style="color:#5c2699">df</span>[<span style="color:#c41a16">"embedding"</span>].values.tolist())
<span style="color:#5c2699">df</span>[<span style="color:#c41a16">"umap"</span>] = umap_all.tolist()
</span></span></span></span>每个文档片段的另一个有趣的指标是其嵌入与最近问题的嵌入之间的距离
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">question_embeddings = np.array(df[df[<span style="color:#c41a16">"question"</span>].notna()][<span style="color:#c41a16">"embedding"</span>].tolist())
df[<span style="color:#c41a16">"nearest_question_dist"</span>] = [ <span style="color:#007400"># brute force, could be optimized using ChromaDB</span>np.<span style="color:#5c2699">min</span>([np.linalg.norm(np.array(doc_emb) - question_embeddings)])<span style="color:#aa0d91">for</span> doc_emb <span style="color:#aa0d91">in</span> df[<span style="color:#c41a16">"embedding"</span>].values
]</span></span></span></span>此指标有助于查找问题未引用的文档。
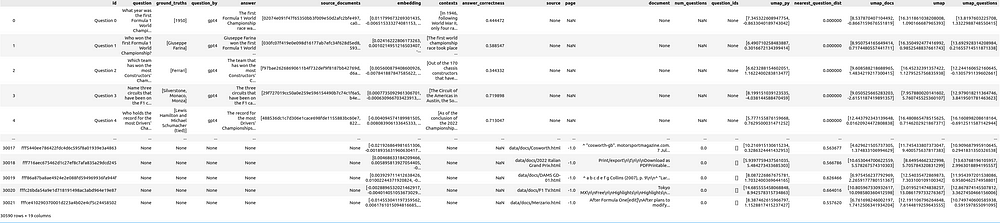
可视化结果
如果跳过了前面的步骤,则可以下载数据帧并使用以下命令加载它:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">import</span> pandas as <span style="color:#5c2699">pd</span>
<span style="color:#3f6e74">df</span> = pd.read_parquet(<span style="color:#c41a16">"df_f1_rag_docs_and_questions.parquet"</span>)</span></span></span></span>并启动 Renumics Spotlight 以通过以下方式将其可视化:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">from</span> renumics <span style="color:#aa0d91">import</span> spotlightspotlight.show(df)
spotlight.show(df,layout=<span style="color:#c41a16">"/home/markus/Downloads/layout_rag_1.json"</span>,dtype={x: Embedding <span style="color:#aa0d91">for</span> x <span style="color:#aa0d91">in</span> df.keys() <span style="color:#aa0d91">if</span> <span style="color:#c41a16">"umap"</span> <span style="color:#aa0d91">in</span> x},
)</span></span></span></span>它将打开一个新的 brwoser 窗口:
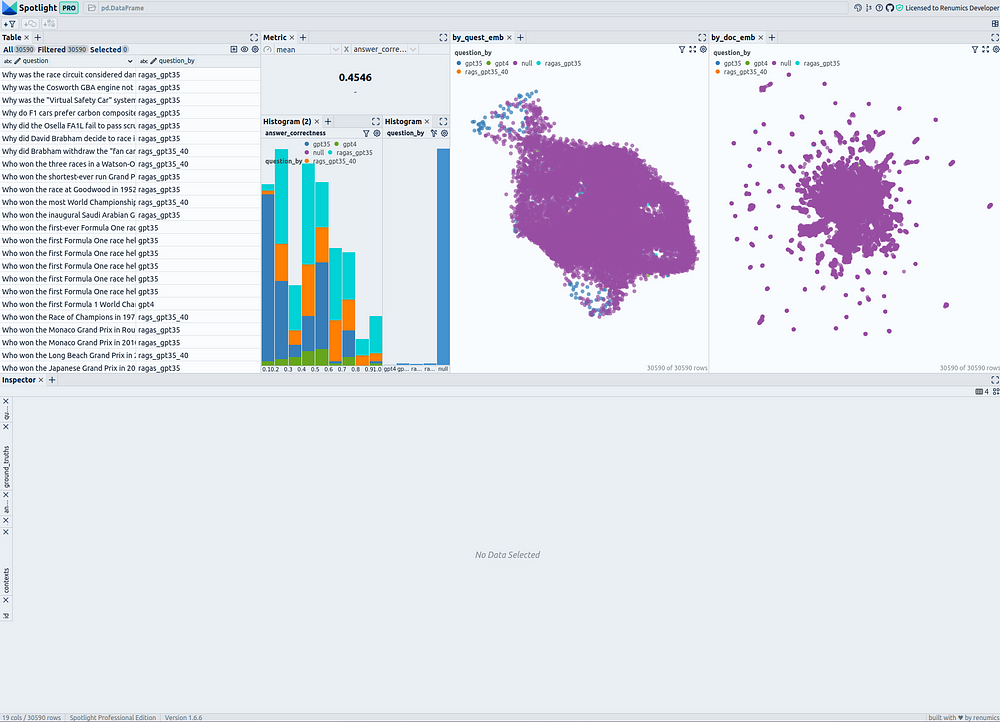
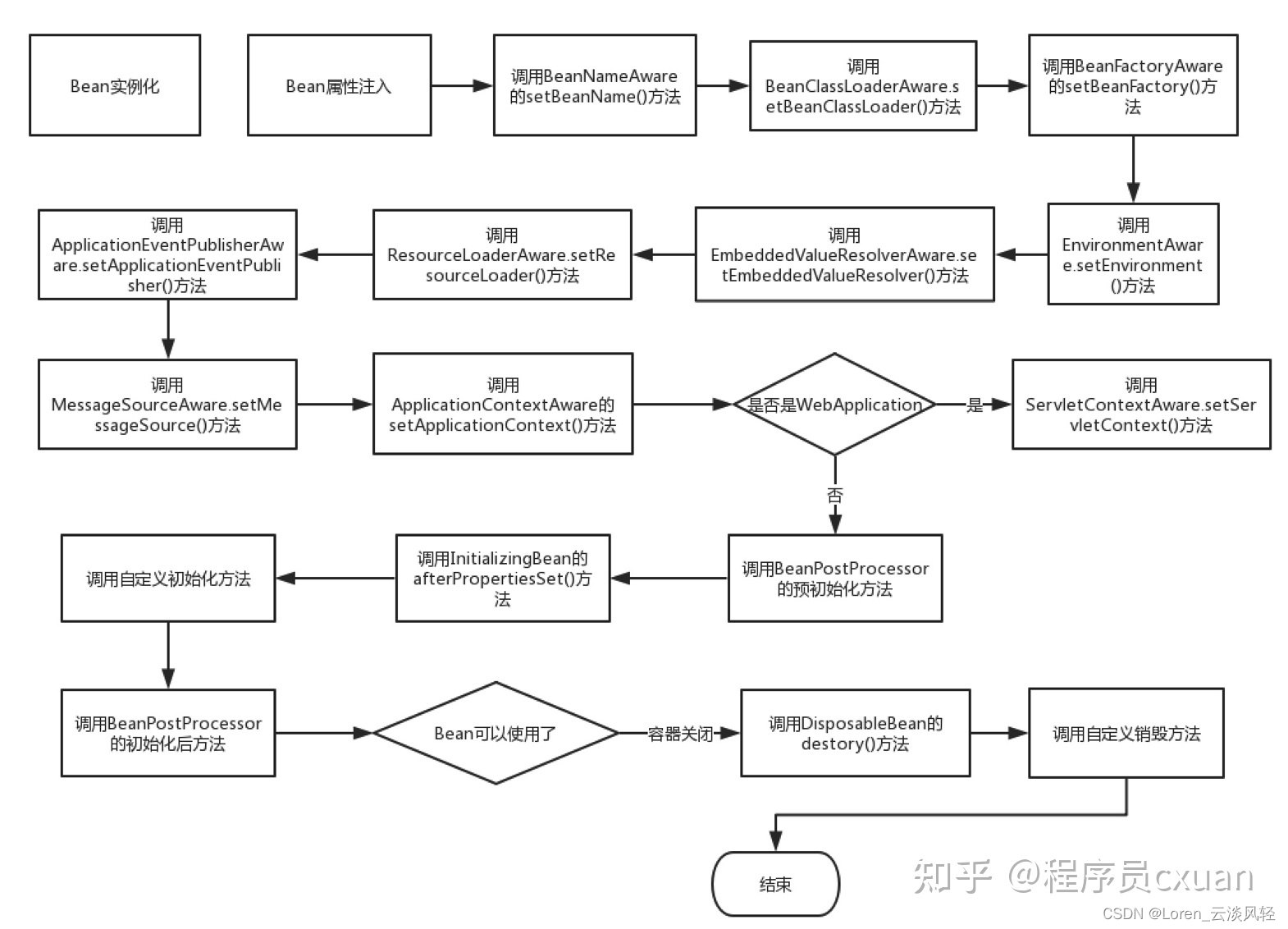
一级方程式文件和评估问题统计和相似性地图——由作者使用 Renumics Spotlight 创建
在左上角,您可以看到包含所有问题和所有文档片段的表格。您可以使用“可见列”按钮来控制表中显示数据框的哪些列。直接创建一个筛选器,仅选择问题,以便能够在可视化效果中打开和关闭问题,这很有用:选择所有问题,然后使用“从所选行创建筛选器”按钮创建筛选器。
在表格的右侧,显示 answer correctness 为所有问题的指标。下面有两个直方图;左边的图显示了分为不同问题生成方法的 answer correctness 分布。右边显示了问题生成方法的分布。在这里,建议使用过滤器按钮为问题创建一个过滤器,以便在需要时仅显示选定的行(问题)。
在右侧,有两个相似性图。第一个使用列 umap_questions ,并根据仅应用于问题的转换显示问题和文档。它有助于独立于关联文档查看问题的分布,因为这种方法允许分析师识别问题本身中的模式或集群。
第二个相似性图显示基于仅应用于文档 ( ) 的转换的问题和文档 umap_docs 。它有助于在相关文档的上下文中查看问题。事实证明,同时转换问题和文档的相似性图对大量问题的帮助不大,因为或多或少的问题聚集在一起,并且往往与文档分开。因此,此处省略了此表示形式。
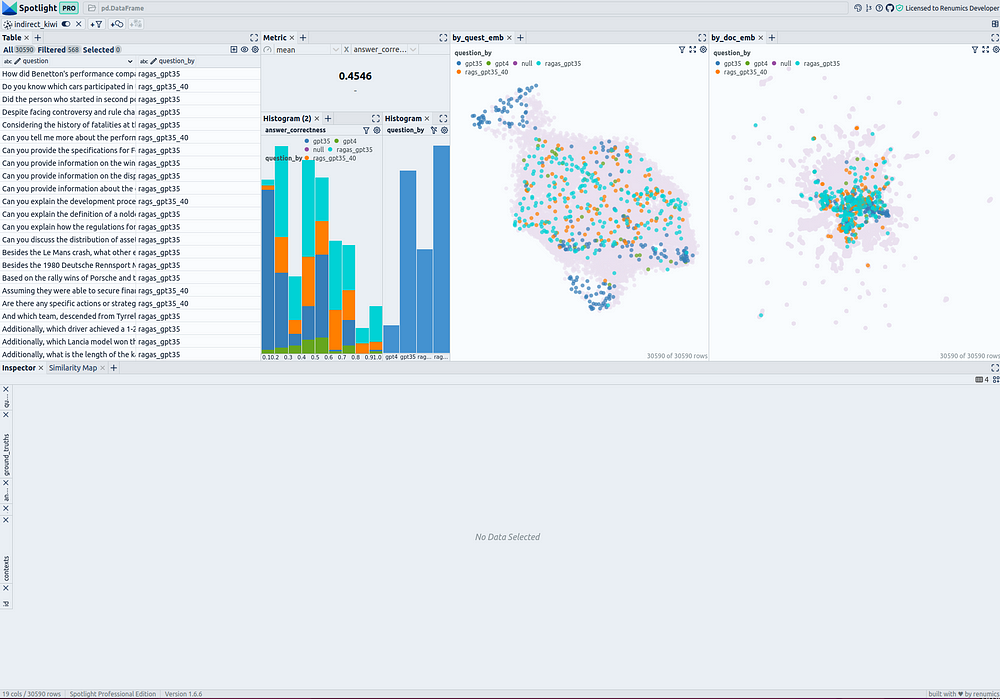
一级方程式评估问题统计和相似性图——由作者使用 Renumics Spotlight 创建
文档嵌入相似性图:观测值
在相似性图 umap_docs 中,您可以识别文档嵌入空间中没有相邻问题的区域。在选择 nearest_question_dist 着色时,它甚至能更好地识别。
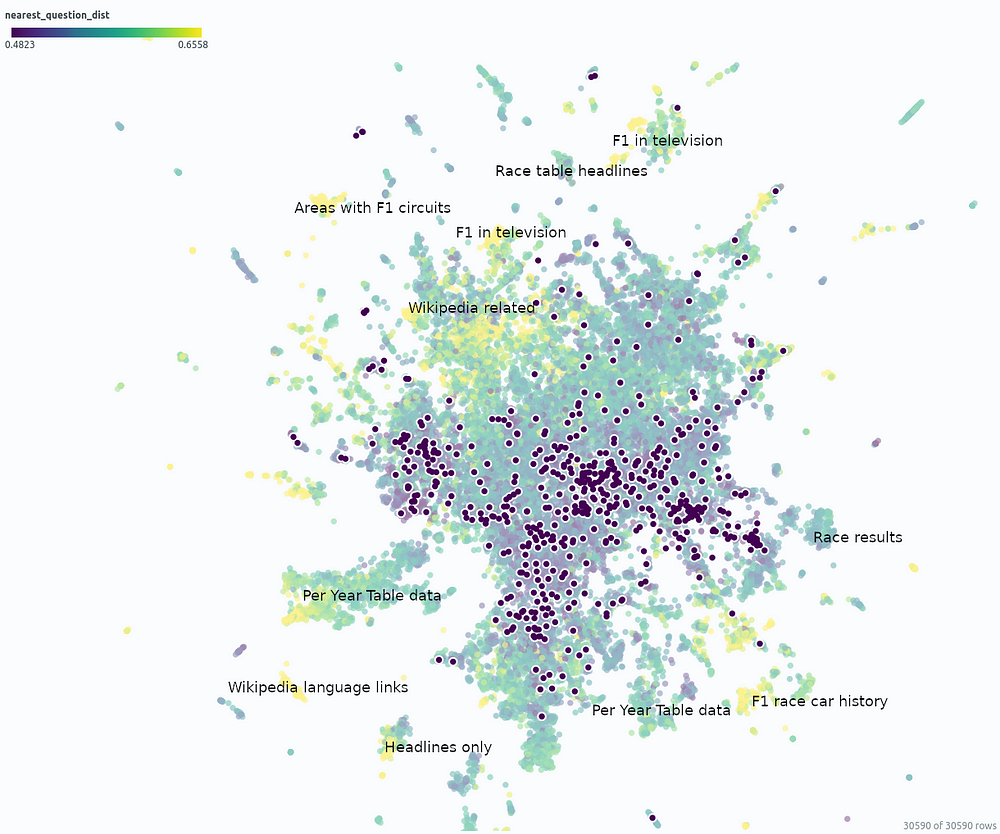
一级方程式文件和问题的相似性图(突出显示)——由作者使用 Renumics Spotlight 创建
可以识别某些聚类,包括仅包含标题的片段或仅逐页包含数字的表格数据,其含义在拆分过程中丢失。此外,许多不包含相关信息的维基百科特定文本添加,例如指向其他语言的链接或编辑注释,形成没有相邻问题的集群。
使用Wikipedia API时,以维基百科相关文本的形式消除噪音非常简单。这可能不是特别必要,因为它主要需要一些空间——预计 RAG 结果不会因此而特别恶化。然而,RAG 系统很难捕获大表中包含的数据,使用用于表提取的高级预处理方法提取这些数据并将它们连接到 RAG 系统可能是有益的。
您可以在 umap_docs 相似性图中观察到的另一点是来自不同来源的问题是如何分布的。
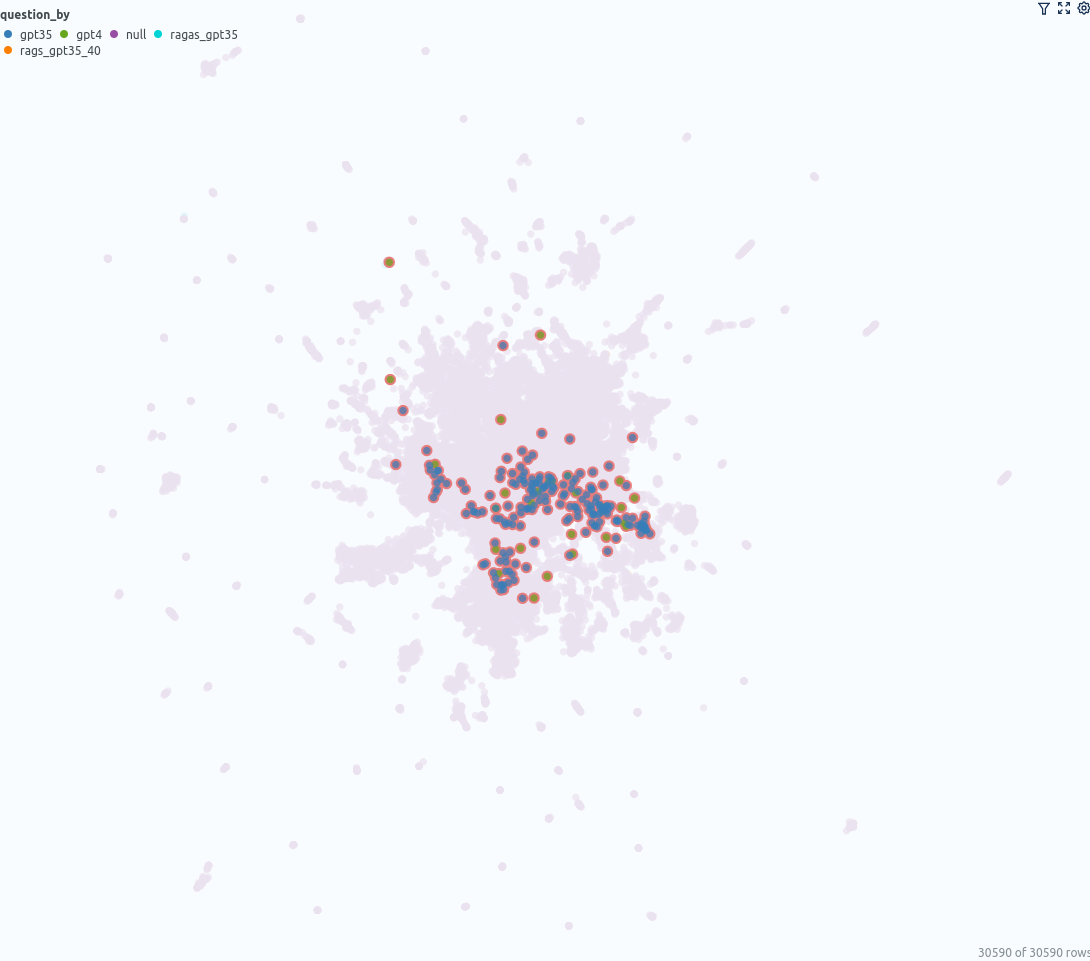
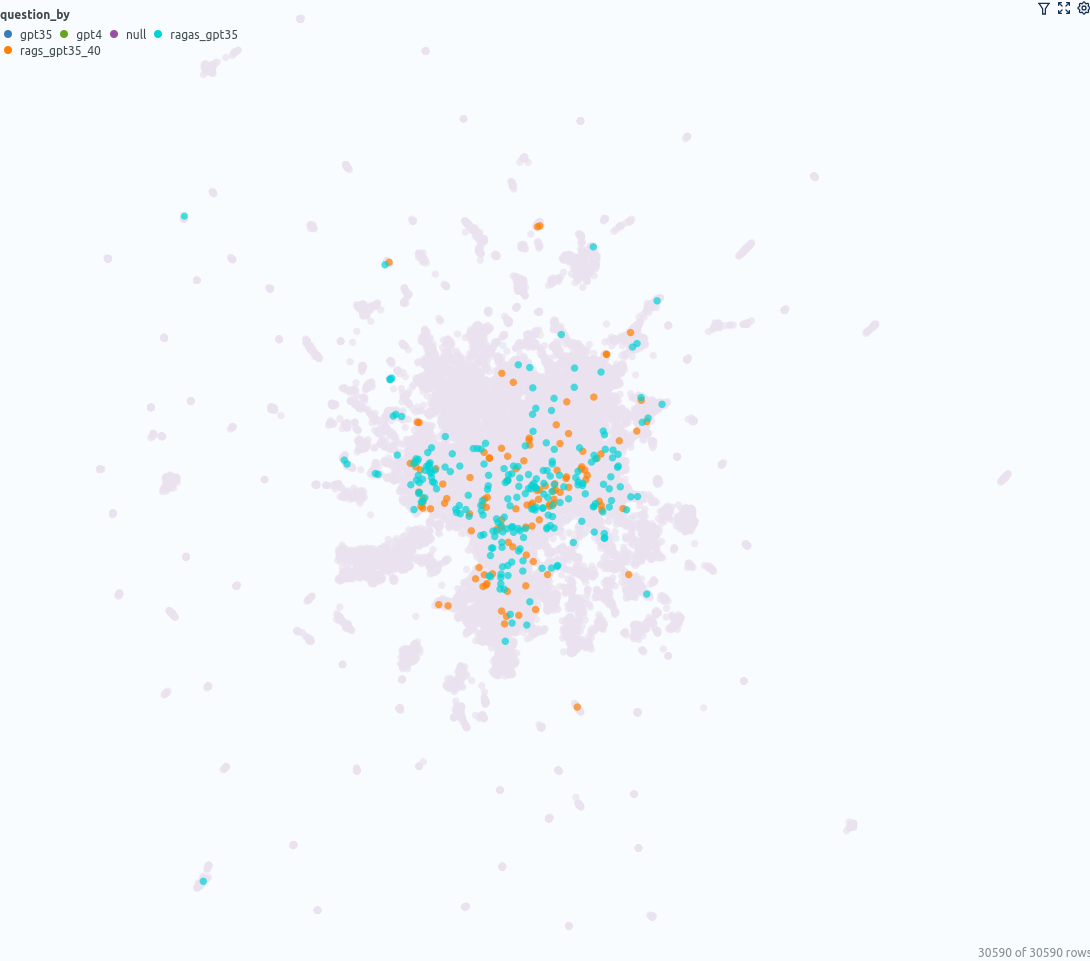
左:ChatGPT(GPT-3.5 和 GPT-4)生成的问题,右:使用 GPT-3.5 和 GPT-4 使用 ragas 生成的问题——由作者使用 Renumics Spotlight 创建
ChatGPT(GPT-3.5、GPT-4)直接生成的问题位于中心更狭窄的区域,而基于文档的ragas生成的问题覆盖了更大的区域。
答案正确性直方图
直方图可以用作起点,以获得数据的全局统计的初步印象。总体而言,在所有问题中, answer correctness 该值为0.45。对于没有 ragas 的问题,它是 0.36,对于有 ragas 的问题,它是 0.52。预计该系统在处理 ragas 生成的问题时会表现得更好,因为这些问题是基于可用数据的,而 ChatGPT 直接生成的问题可能来自训练 ChatGPT 的所有数据。

答案正确性的直方图由问题的来源着色 - 由作者创建
对一些问题/答案和基本事实进行快速、随机的手动审查表明,在 0.3-0.4 的 answer correctness 区间内,大多数问题仍然根据基本事实得到正确回答。在 0.2–0.3 的区间中,存在许多不正确的答案。在区间 0.1–0.2 中,大多数答案都是不正确的。值得注意的是,这个范围内几乎所有的问题都来自GPT-3.5。GPT-4 生成的这个区间内的两个问题得到了正确的回答,即使它们得到的分数 answer correctness 低于 0.2。
嵌入相似性图的问题:观察结果
问题嵌入相似性图有助于通过检查可能导致类似问题的相似问题集群来更深入地挖掘 answer correctness 。
- 集群“驾驶员/流程/汽车术语”:平均
answer correctness0.23:答案通常不够精确。例如,底盘调整与底盘弯曲或制动调整与制动偏置调整。这些类型的问题是否适合评估系统是值得怀疑的,因为似乎很难判断答案。 - 集群“燃料战略条款:”平均
answer correctness为0.44,与全球answer correctness相似。 - 集群“曲目名称”:平均
answer correctness0.49,与全局answer correctnes. - 集群“Who keep the record for...”:平均
answer correctness0.44,与全局answer correctness. - 集群“赢得冠军...”:平均
answer correctnes0.26 — 看起来很有挑战性。有许多条件的问题,例如,“谁是唯一一位以英国赛车执照赢得一级方程式世界锦标赛的车手,为拥有美国发动机的意大利车队驾驶。扩展的 RAG 方法(如 Multi Query)可能有助于改进此处。 - 集群“谁是唯一获胜的车手......一辆带有数字“的汽车:平均
answer correctness0.23——看起来 GPT-3.5 在这里很懒惰,用不同的数字重复同一个问题,即使大多数地面实况条目都是错误的!
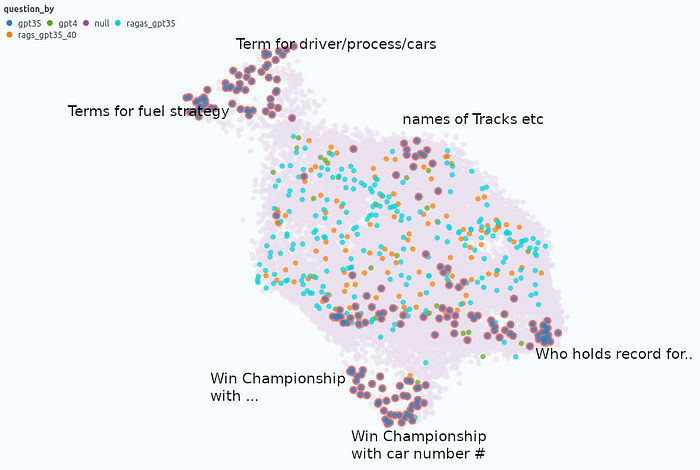
一级方程式问题(突出显示)和文档的相似性图——由作者创建
结论
总之,利用基于UMAP的可视化提供了一种有趣的方法,可以更深入地挖掘,而不仅仅是分析全局指标。嵌入相似性图的文档给出了一个很好的概述,说明了相似文档的聚类及其与评估问题的关系。问题相似性图揭示了允许区分和分析问题的模式,并结合质量指标进行分析,从而产生洞察力。按照“可视化结果”部分,将可视化应用于评估策略 - 您将发现哪些见解?
![[Unity3d] 网络开发基础【个人复习笔记/有不足之处欢迎斧正/侵删】](https://img-blog.csdnimg.cn/direct/f8d1c73dfde143618e9e8074fd31067a.png)