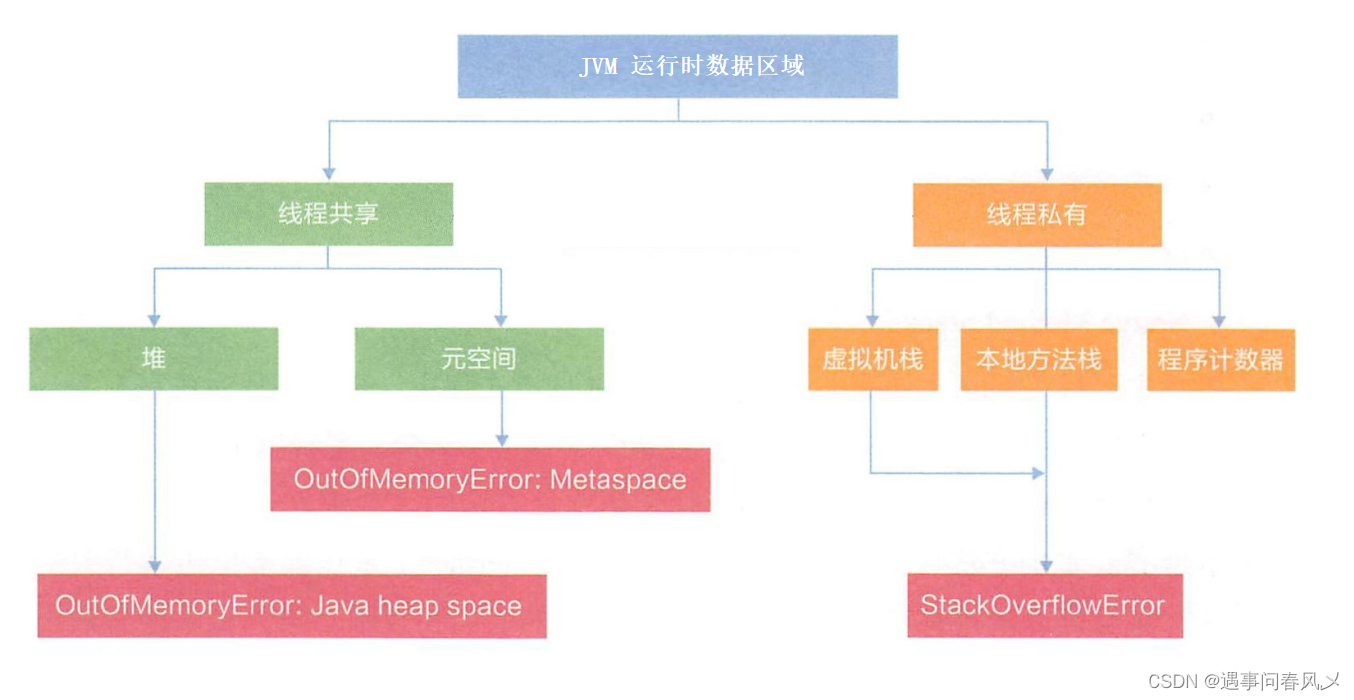
Linux系统中,AWK 是一个非常强大的文本处理工具,它的内置函数使得对文本数据进行处理更加高效和便捷。
本文将介绍 AWK 内置函数的几种主要类型:
- 算数函数
- 字符串函数
- 时间函数
- 位操作函数
- 其他常用函数
我们将使用一个示例文本文件来演示这些函数的用法,并提供详细的注释说明,继续分享。
基础学习,可以回头查看:Linux文本处理三剑客:awk(结构化命令)
1.算数函数
| 函数名 | 功能 | 参数 | 示例 | 输出 |
| atan2(y,x) | 返回正切值 y/x 的角度值,角度以弧度为单位 | y, x | atan2(10, -10) * 180 / PI | 135 |
| cos(expr) | 返回 expr 的余弦值,输入参数以弧度为单位 | expr | cos(60 * PI / 180.0) | 0.5 |
| exp(expr) | 返回自然数 e 的 expr 次幂 | expr | exp(5) | 148.413159 |
| int(expr) | 返回数值 expr 的整数部分 | expr | int(5.12345) | 5 |
| log(expr) | 计算 expr 自然对数 | expr | log(5.5) | 1.704748 |
| rand | 返回一个大于等于 0 小于 1 的随机数 | - | rand() | 0.237788 |
| sin(expr) | 返回角度 expr 的正弦值,角度以弧度为单位 | expr | sin(30 * PI / 180) | 0.5 |
| sqrt(expr) | 计算 expr 的平方根 | expr | sqrt(1024.0) | 32 |
| srand([expr]) | 使用种子值生成随机数 | expr | srand(10) | 1417959587 |
注释:
- 以上表格仅列出了 AWK 提供的内置算术函数。
- 算术函数的参数必须是数值。
- 算术函数的返回值是数值。
# 反正切函数
awk 'BEGIN {PI = 3.14159265x = -10y = 10result = atan2 (y,x) * 180 / PI;printf "对于 (x=%f, y=%f),反正切值为 %f 度\n", x, y, result
}'# 余弦函数
awk 'BEGIN {PI = 3.14159265param = 60result = cos(param * PI / 180.0);printf "%f 度的余弦值为 %f\n", param, result
}'# 自然指数函数
awk 'BEGIN {param = 5result = exp(param);printf "%f 的自然指数值为 %f\n", param, result
}'# 取整函数
awk 'BEGIN {param = 5.12345result = int(param)print "Truncated value =", result
}'# 自然对数函数
awk 'BEGIN {param = 5.5result = log (param)printf "log(%f) = %f\n", param, result
}'# 随机数函数
awk 'BEGIN {print "Random num1 =" , rand()print "Random num2 =" , rand()print "Random num3 =" , rand()
}'#正弦函数
awk 'BEGIN {PI = 3.14159265param = 30.0result = sin(param * PI /180)printf "The sine of %f degrees is %f.\n", param, result
}'# 平方根函数
awk 'BEGIN {param = 1024.0result = sqrt(param)printf "sqrt(%f) = %f\n", param, result
}'# 设置随机数种子
awk 'BEGIN {param = 10printf "srand() = %d\n", srand()printf "srand(%d) = %d\n", param, srand(param)
}'2.字符串函数
| 函数名 | 功能 | 参数 | 示例 | 输出 |
| asort(arr, [d [, how]]) | 使用 GAWK 值比较的一般规则排序 arr 中的内容 | arr, d, how | asort(arr) | - |
| asorti(arr, [d [, how]]) | 对数组的索引排序 | arr, d, how | asorti(arr) | - |
| gsub(regexp, replacement [, target]) | 全局替换子串 | regexp, replacement, target | gsub("World", "Jerry", str) | Hello, Jerry |
| index(str, sub) | 检测子串是否存在 | str, sub | index(str, subs) | 5 |
| length(str) | 返回字符串长度 | str | length(str) | 16 |
| match(str, regex) | 搜索与正则表达式匹配的子串 | str, regex | match(str, subs) | 5 |
| split(str, arr, regex) | 分割字符串 | str, arr, regex | split(str, arr, ",") | One, Two, Three, Four |
| sprintf(format, expr-list) | 按指定格式构造字符串 | format, expr-list | sprintf("%s", "Hello, World !!!") | Hello, World !!! |
| strtonum(str) | 将字符串转换为数值 | str | strtonum("123") | 123 |
| sub(regex, sub, string) | 执行一次子串替换 | regex, sub, string | sub("World", "Jerry", str) | Hello, Jerry |
| substr(str, start, l) | 返回子串 | str, start, l | substr(str, 1, 5) | Hello |
| tolower(str) | 将所有大写字母转换为小写字母 | str | tolower(str) | hello, world !!! |
| toupper(str) | 将所有小写字母转换为大写字母 | str | toupper(str) | HELLO, WORLD !!! |
注释:
- 以上表格仅列出了 AWK 提供的内置字符串函数。
- 字符串函数的参数可以是字符串或变量。
- 字符串函数的返回值是字符串。
# 按字母顺序排列数组元素
$ awk 'BEGIN {arr[0] = "Three"arr[1] = "One"arr[2] = "Two"print "排序前数组元素:"for (i in arr) {print arr[i]}asort(arr)print "排序后数组元素:"for (i in arr) {print arr[i]}
}'# 按索引顺序排列数组元素
awk 'BEGIN {arr["Two"] = 1arr["One"] = 2arr["Three"] = 3asorti(arr)print "排序后数组索引:"for (i in arr) {print arr[i]}
}'# 替换字符串
awk 'BEGIN {str = "Hello, World"print "替换前字符串 = " strgsub("World", "Jerry", str)print "替换后字符串 = " str
}'# 查找子串的位置
awk 'BEGIN {str = "One Two Three"subs = "Two"ret = index(str, subs)printf "子串 \"%s\" 在第 %d 个位置找到.\n", subs, ret
}'# 获取字符串长度
awk 'BEGIN {str = "Hello, World !!!"print "长度 = ", length(str)
}'# 使用正则表达式匹配子串
awk 'BEGIN {str = "One Two Three"subs = "Two"ret = match(str, subs)printf "子串 \"%s\" 在第 %d 个位置找到.\n", subs, ret
}'# 将字符串分割为数组
awk 'BEGIN {str = "One,Two,Three,Four"split(str, arr, ",")print "数组包含以下元素:"for (i in arr) {print arr[i]}
}'# 使用 sprintf() 格式化字符串
awk 'BEGIN {str = sprintf("%s", "Hello, World !!!")print str
}'# 将字符串转换为数字
awk 'BEGIN {print "Decimal num = " strtonum("123")print "Octal num = " strtonum("0123")print "Hexadecimal num = " strtonum("0x123")
}'# 使用 sub() 替换字符串
awk 'BEGIN {str = "Hello, World"print "替换前字符串 = " strsub("World", "Jerry", str)print "替换后字符串 = " str
}'# 获取子字符串
awk 'BEGIN {str = "Hello, World !!!"subs = substr(str, 1, 5)print "Substring = " subs
}'# 小写转换
awk 'BEGIN {str = "HELLO, WORLD !!!"print "Lowercase string = " tolower(str)
}'# 大写转换
awk 'BEGIN {str = "hello, world !!!"print "Uppercase string = " toupper(str)
}'3.时间函数
| 函数名 | 功能 | 参数 | 示例 | 输出 |
| systime | 返回从 Epoch 以来到当前时间的秒数 | - | systime() | 1418574432 |
| mktime(datespec) | 将字符串转换为时间戳 | datespec | mktime("2014 12 14 30 20 10") | 1418604610 |
| strftime([format [, timestamp[, utc-flag]]]) | 格式化时间戳 | format, timestamp, utc-flag | strftime("Time = %m/%d/%Y %H:%M:%S", systime()) | Time = 12/14/2014 22:08:42 |
注释:
- 以上表格仅列出了 AWK 提供的内置时间函数。
- 时间戳是一个数值,表示从 Epoch 以来经过的秒数。
- Epoch 是 Unix 时间的起点,为 1970 年 1 月 1 日 00:00:00 UTC。
# 获取当前时间戳
awk 'BEGIN {print "Number of seconds since the Epoch = " systime()
}'
# 将字符串转换为时间戳
awk 'BEGIN {print "Number of seconds since the Epoch = " mktime("2014 12 14 30 20 10")
}'# 格式化时间戳
awk 'BEGIN {print strftime("Time = %m/%d/%Y %H:%M:%S", systime())
}'# 打印当前星期几
awk 'BEGIN {print strftime("%A")
}'4.位操作函数
| 函数名 | 功能 | 参数 | 示例 | 输出 |
| and | 执行位与操作 | num1, num2 | and(10, 6) | 2 |
| compl | 按位求补 | num1 | compl(10) | 9.0072E+15 |
| lshift | 左移位操作 | num1, shift | lshift(10, 1) | 20 |
| rshift | 向右移位操作 | num1, shift | rshift(10, 1) | 5 |
| or | 按位或操作 | num1, num2 | or(10, 6) | 14 |
| xor | 按位异或操作 | num1, num2 | xor(10, 6) | 12 |
注释:
- 以上表格仅列出了 AWK 提供的内置位操作函数。
- 位操作函数的参数必须是整数。
- 位操作函数的返回值是整数。
# 位与操作
awk 'BEGIN {num1 = 10num2 = 6printf "(%d AND %d) = %d\n", num1, num2, and(num1, num2)
}'# 按位求补
awk 'BEGIN {num1 = 10printf "compl(%d) = %d\n", num1, compl(num1)
}'# 左移位操作
awk 'BEGIN {num1 = 10printf "lshift(%d) by 1 = %d\n", num1, lshift(num1, 1)
}'# 向右移位操作。
awk 'BEGIN {num1 = 10printf "rshift(%d) by 1 = %d\n", num1, rshift(num1, 1)
}'# 按位或操作。
awk 'BEGIN {num1 = 10num2 = 6printf "(%d OR %d) = %d\n", num1, num2, or(num1, num2)
}'# 按位异或操作
[jerry]$ awk 'BEGIN {num1 = 10num2 = 6printf "(%d XOR %d) = %d\n", num1, num2, xor(num1, num2)
}'5.其他常用函数
| 函数名 | 功能 | 参数 | 示例 | 输出 |
| close(expr) | 关闭管道的文件 | expr | close(cmd, "to") | - |
| delete | 从数组中删除元素 | 数组索引 | delete arr[0] | - |
| exit([expr]) | 终止脚本执行 | expr | exit 10 | - |
| fflush([output-expr]) | 刷新打开文件或管道的缓冲区 | output-expr | fflush() | - |
| getline | 读入下一行 | - | getline < file | - |
| next | 停止处理当前记录,进入下一条记录的处理过程 | - | if ($0 ~/Shyam/) next | - |
| nextfile | 停止处理当前文件,从下一个文件第一个记录开始处理 | - | if ($0 ~ /file1:str2/) nextfile | - |
| return([expr]) | 从用户自定义的函数中返回值 | expr | return result | - |
| system(cmd) | 执行特定的命令 | cmd | system("date") | 0 |
注释:
- 以上表格仅列出了 AWK 提供的其它内置函数。
- 每个函数的具体使用方法请参考 AWK 官方文档。
# 关闭管道
awk 'BEGIN {cmd = "tr [a-z] [A-Z]"print "hello, world !!!" |& cmdclose(cmd, "to")cmd |& getline outprint out;close(cmd);
}'# 从数组中删除元素
awk 'BEGIN {arr[0] = "One"arr[1] = "Two"arr[2] = "Three"arr[3] = "Four"print "删除前:"for (i in arr) {print arr[i]}delete arr[0]delete arr[1]print "删除后:"for (i in arr) {print arr[i]}
}'# 终止脚本执行
awk 'BEGIN {print "Hello, World !!!"exit 10print "AWK never executes this statement."
}'# 刷新打开文件或管道的缓冲区
fflush([output-expr])# 读入下一行
awk '{getline; print $0}' file.txt # 执行特定的命令然后返回其退出状态。返回值为 0 表示命令执行成功;非 0 表示命令执行失败。
awk 'BEGIN { ret = system("date"); print "Return value = " ret }'如果您觉得有些用处,熟练操作这些代码后,相信你会有一些收获。
欢迎在评论区留言,关注。谢谢您的阅读!
敬请关注!
往期学习笔记:
Windows系统开启Linux子系统(Ubuntu)
Linux常用命令(目录操作命令)
Linux常用命令:文件的创建、复制、移动、查找和删除命令
Linux常用命令:文本文件的查看与编辑
Linux常用命令:文本文件的拼接与分割
Linux常用命令:文件的权限管理
Linux常用命令:文件的下载、压缩与解压
Linux常用命令:常见的操作符
Linux常用命令:系统操作命令
Linux文本处理三剑客:grep
Linux文本处理三剑客:sed
Linux文本处理三剑客:awk
Linux文本处理三剑客:awk(常用匹配模式)
Linux文本处理三剑客:awk(结构化命令)
Linux文本处理三剑客:awk(对具体文本的示例代码)