一、为什么使用线程池
大家都知道C++支持多线程开发,也就是支持多个任务并行运行,我们也知道线程的生命周期中包括创建、就绪、运行、阻塞、销毁等阶段,所以如果要执行的任务很多,每个任务都需要一个线程的话,那么频繁的创建、销毁线程会比较耗性能。
有了线程池就不用创建更多的线程来完成任务,它可以:
①降低资源的消耗,通过重复利用已经创建的线程降低线程创建和销毁造成的消耗。
②提高相应速度,当任务到达的时候,任务可以不需要等到线程创建就能立刻执行。
③提高线程的可管理性,线程是稀缺资源,使用线程池可以统一的分配、调优和监控。
二、线程池的原理
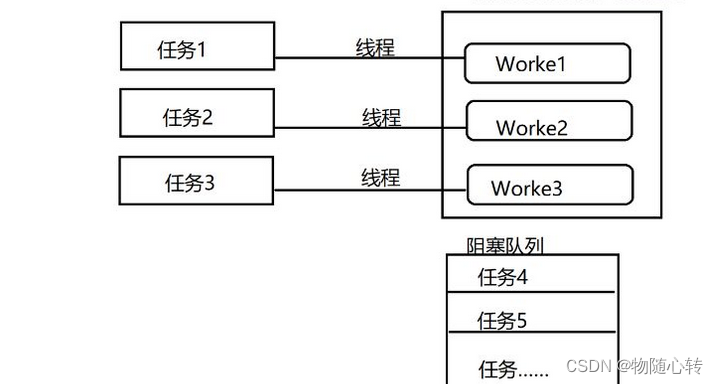
通俗的讲,线程池就是一个线程集合,里面已经提前创建好了若干个线程,当需要线程的时候到线程集合里获取一个即可,这样省去了创建线程的时间,当然也省去了系统回收线程的时间,当线程池里的线程都被使用了后,只能阻塞等待了,等待获取线程池后被释放的线程。
当线程池提交一个任务到线程池后,执行流程如下:

线程池先判断核心线程池里面的线程是否都在执行任务。如果不是都在执行任务,则创建一个新的工作线程来执行任务。如果核心线程池中的线程都在执行任务,则判断工作队列是否已满。如果工作队列没有满,则将新提交的任务存储到这个工作队列中,如果工作队列满了,线程池则判断线程池的线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理 ,也就是拒接策略。
一句话:管理一个任务队列,一个线程队列,然后每次去一个任务分配给一个线程去做,循环往复。
三、代码实现
有什么问题?线程池一般是要复用线程,所以如果是取一个task分配给某一个thread,执行完之后再重新分配,在语言层面这是基本不能实现的:C++的thread都是执行一个固定的task函数,执行完之后线程也就结束了。所以该如何实现task和thread的分配呢?
让每一个thread创建后,就去执行调度函数:循环获取task,然后执行。
这个循环该什么时候停止呢?
很简单,当线程池停止使用时,循环停止。
这样一来,就保证了thread函数的唯一性,而且复用线程执行task。
总结一下,我们的线程池的主要组成部分有二:
- 任务队列(Task Queue)
- 线程池(Thread Pool)
//*****************ThreadPool.h**********************
#ifndef THREAD_POOL_H
#define THREAD_POOL_H#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>class ThreadPool {
public:ThreadPool(size_t);template<class F, class... Args>auto enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>;~ThreadPool();
private:// need to keep track of threads so we can join themstd::vector< std::thread > workers;// the task queuestd::queue< std::function<void()> > tasks;// synchronizationstd::mutex queue_mutex;std::condition_variable condition;bool stop;
};// the constructor just launches some amount of workers
inline ThreadPool::ThreadPool(size_t threads): stop(false)
{for(size_t i = 0;i<threads;++i)workers.emplace_back([this]{for(;;){std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queue_mutex);this->condition.wait(lock,[this]{ return this->stop || !this->tasks.empty(); });if(this->stop && this->tasks.empty())return;task = std::move(this->tasks.front());this->tasks.pop();}task();}});
}// add new work item to the pool
template<class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>
{using return_type = typename std::result_of<F(Args...)>::type;auto task = std::make_shared< std::packaged_task<return_type()> >(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queue_mutex);// don't allow enqueueing after stopping the poolif(stop)throw std::runtime_error("enqueue on stopped ThreadPool");tasks.emplace([task](){ (*task)(); });}condition.notify_one();return res;
}// the destructor joins all threads
inline ThreadPool::~ThreadPool()
{{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}condition.notify_all();for(std::thread &worker: workers)worker.join();
}#endif
参考:
基于C++11实现线程池 - 知乎
C++多线程编程中std::future的使用_Junyuan12的博客-CSDN博客
C++实现线程池_晓枫寒叶的博客-CSDN博客_c++ 线程池








![[ web基础篇 ] Burp Suite 爆破 Basic 认证密码](https://img-blog.csdnimg.cn/ce5f519f3cf2432caa55d787e0a4b11e.png)


