Pandas的分层索引Multilndex¶
1为什么要学习分层索引Multilndex?
1、分层索引:在一个轴向上拥有多个索引层级,可以表达更高维度数据的形式;
2、方便的进行数据筛选,如果有序则性能更好;
3、groupby等操作的结果,如果是多KEY,结果是分层索引,需要会使用。
4、一般不需要自己创建分层索引(Multilndex有构造函数但一般不用)
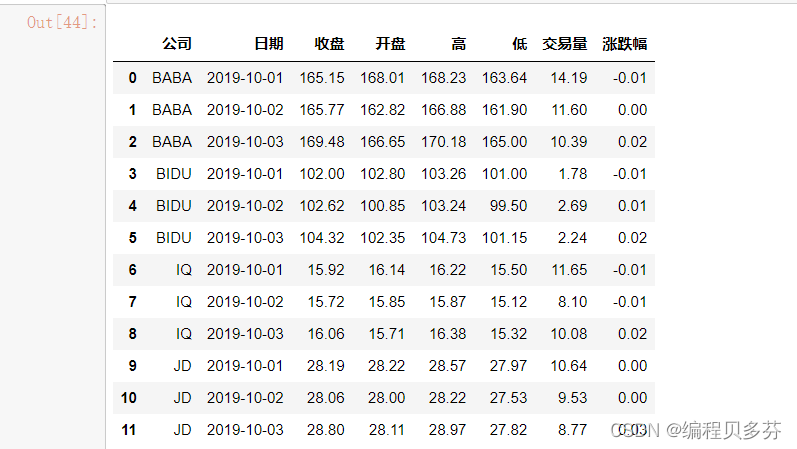
演示数据:百度、阿里巴巴、爱奇艺、京东四家公司的10天股票数据数据来自:英为财经
—、Series的分层索引Multilndex
二、Series有多层索引怎样筛选数据?
三、DataFrame的多层索引Multilndex
四、DataFrame有多层索引怎样筛选数据?
import pandas as pd
%matplotlib inline
stocks=pd.read_excel('./datas/stocks/互联网公司股票.xlsx')
stocks.shapestocks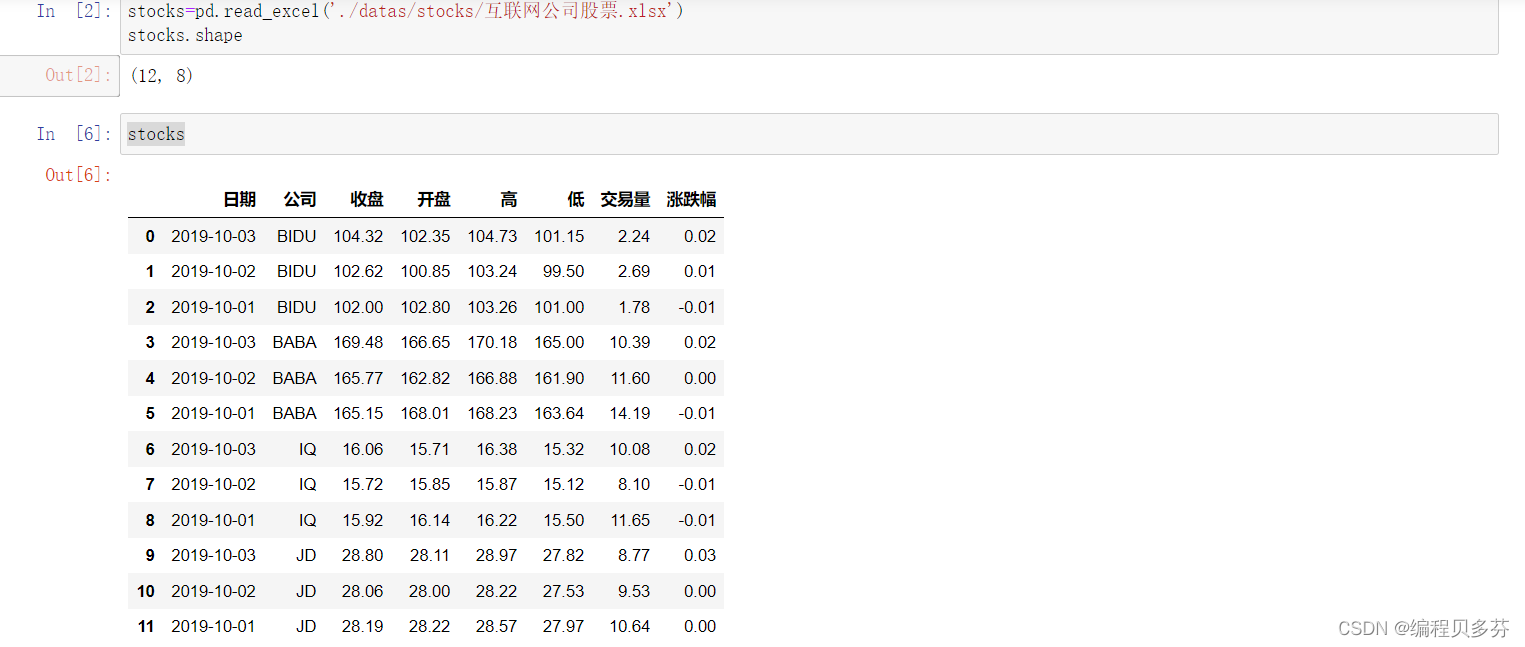
stocks['公司'].unique()
stocks.index
#计算每个公司收盘的平均值
stocks.groupby('公司')['收盘'].mean()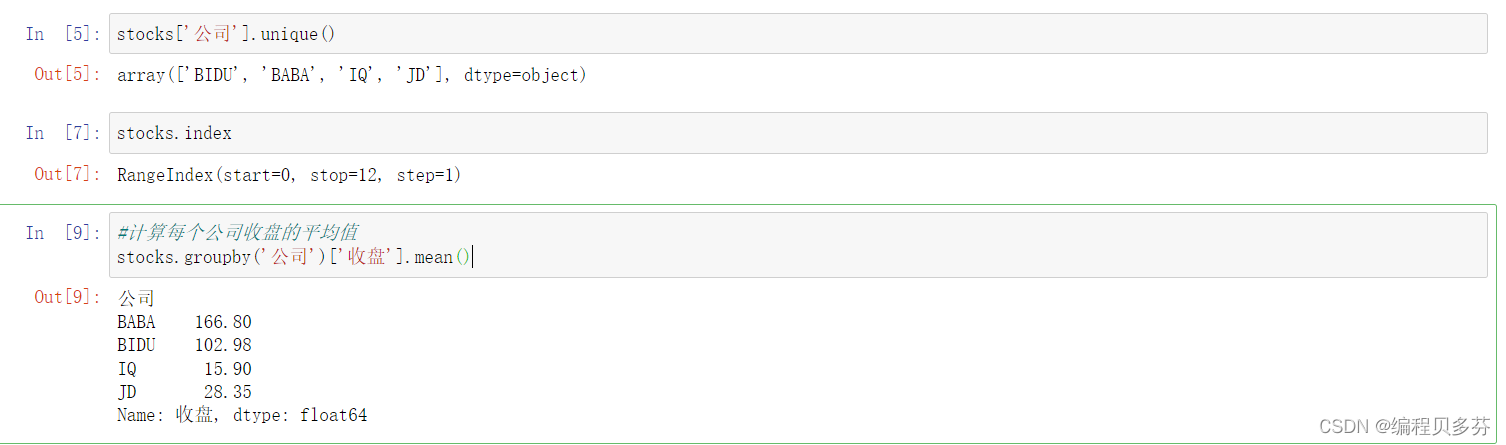
一、Series的分层索引MultiIndex
ser=stocks.groupby(['公司','日期'])['收盘'].mean()
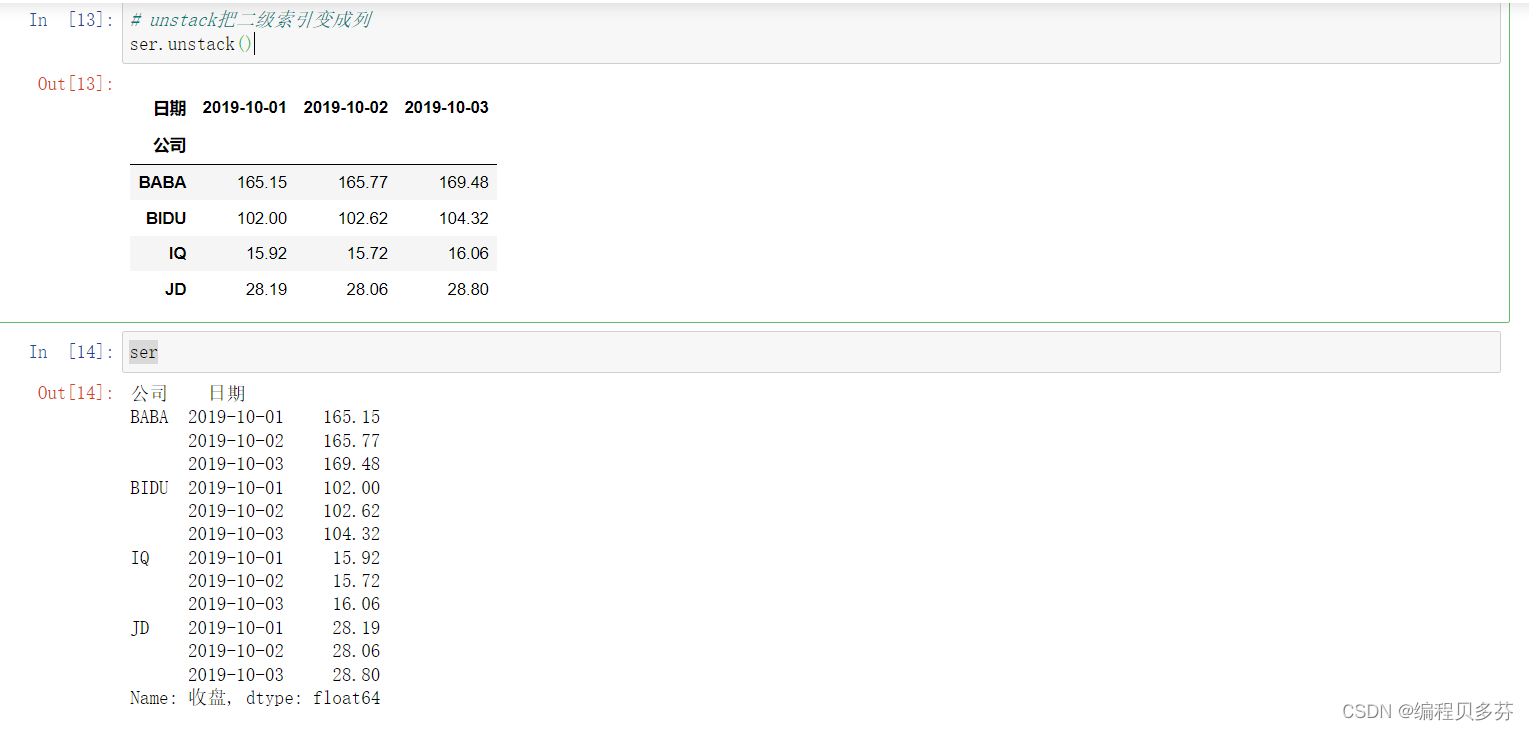
serser.index# unstack把二级索引变成列
ser.unstack()
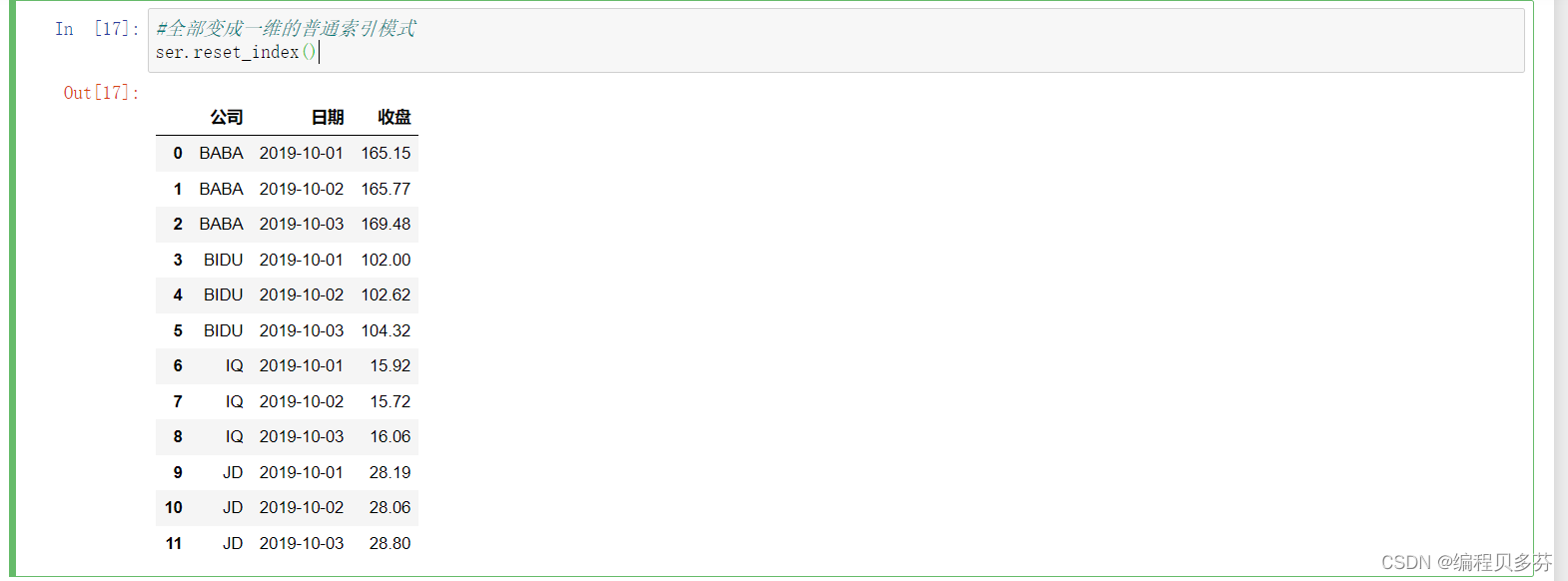
ser#全部变成一维的普通索引模式
ser.reset_index()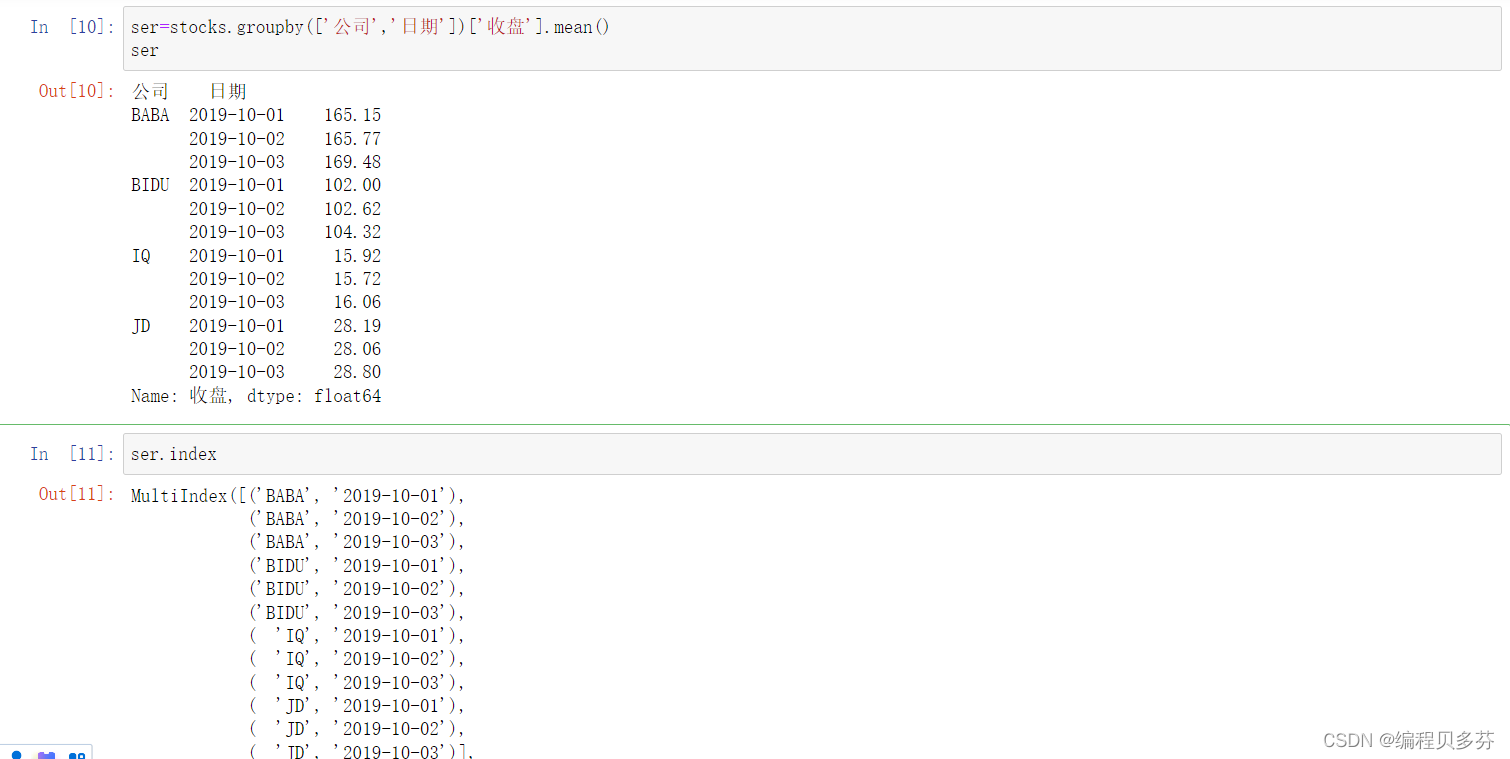
 二、Series有多层索引Multilndex怎样筛选数据?
二、Series有多层索引Multilndex怎样筛选数据?
ser
ser.loc['BIDU']
# 多层索引,可以用元组的形式进行筛选
ser.loc[('BIDU','2019-10-02')]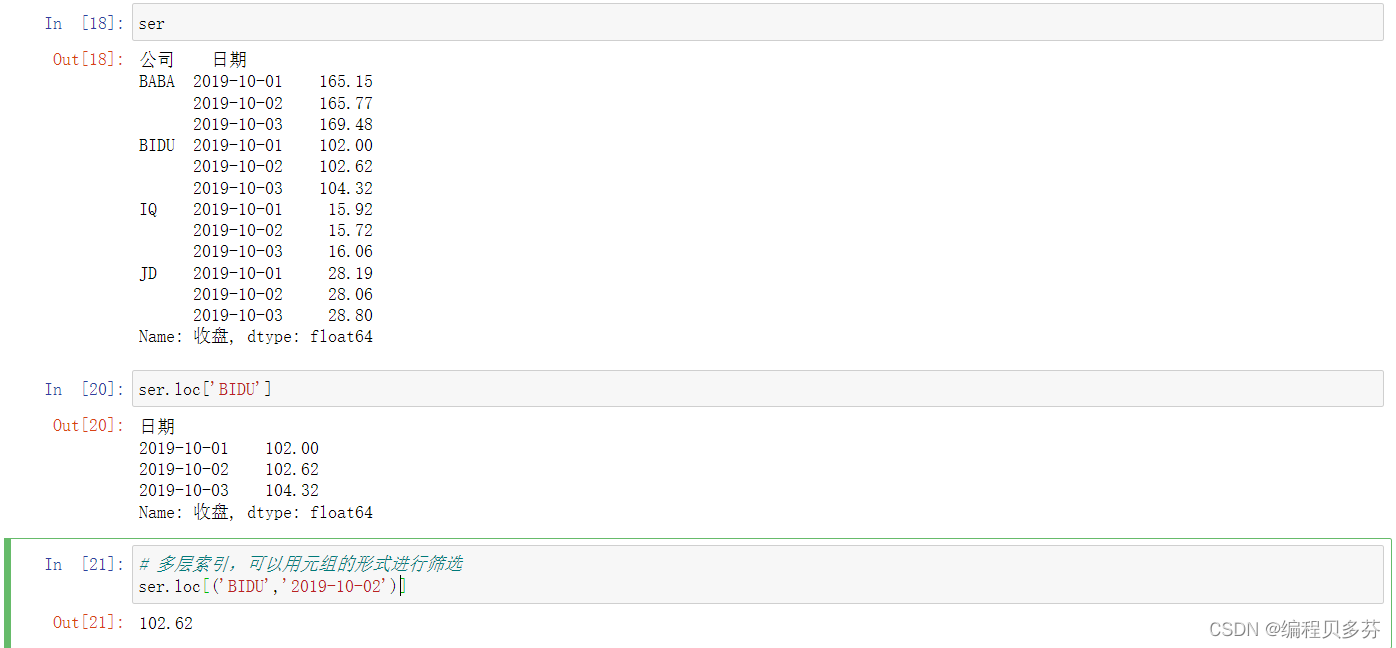
#求所有公司中指定月份的收盘价
ser.loc[:,'2019-10-02']
三、DataFrame的多层索引Multilndex
stocks.head()
stocks.set_index(['公司','日期'],inplace=True)
stocks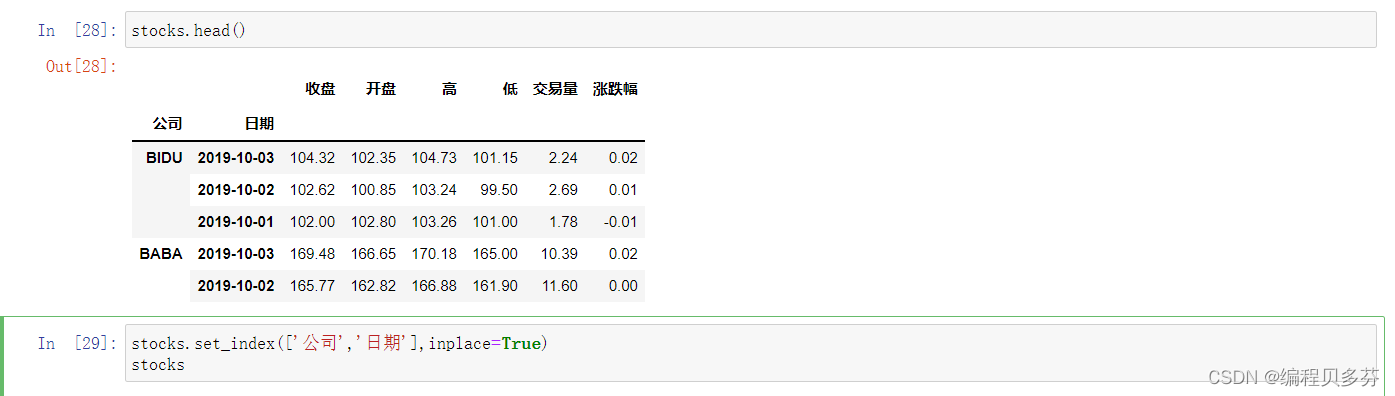
stocks.index
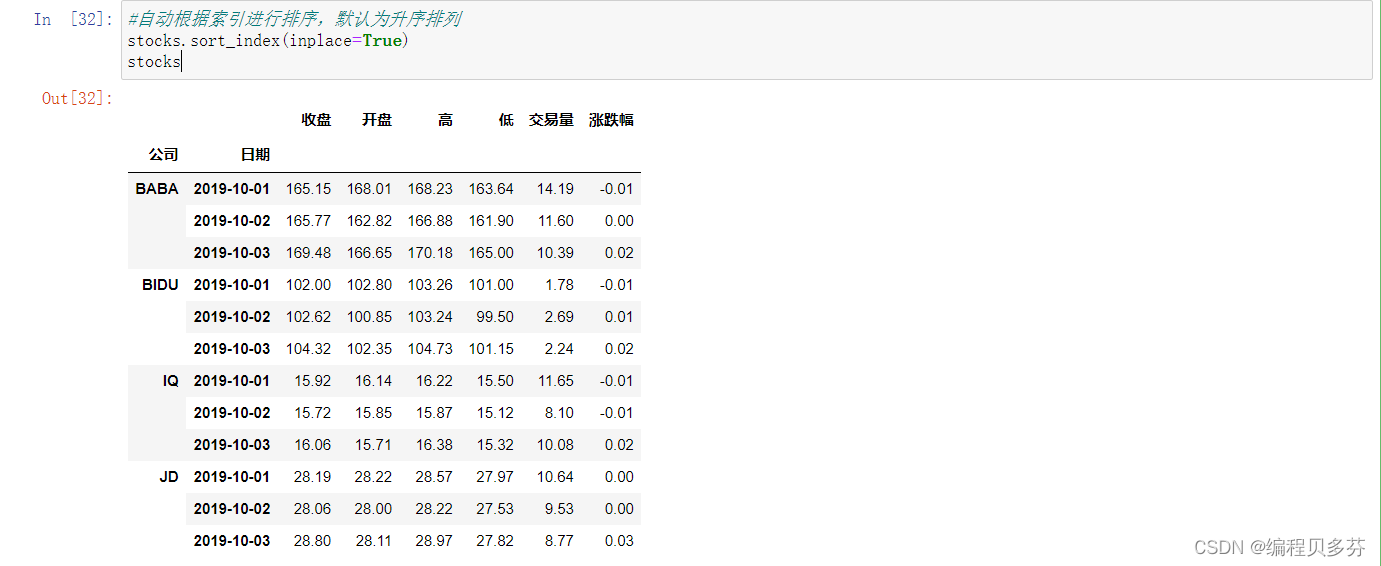
#自动根据索引进行排序,默认为升序排列
stocks.sort_index(inplace=True)
stocks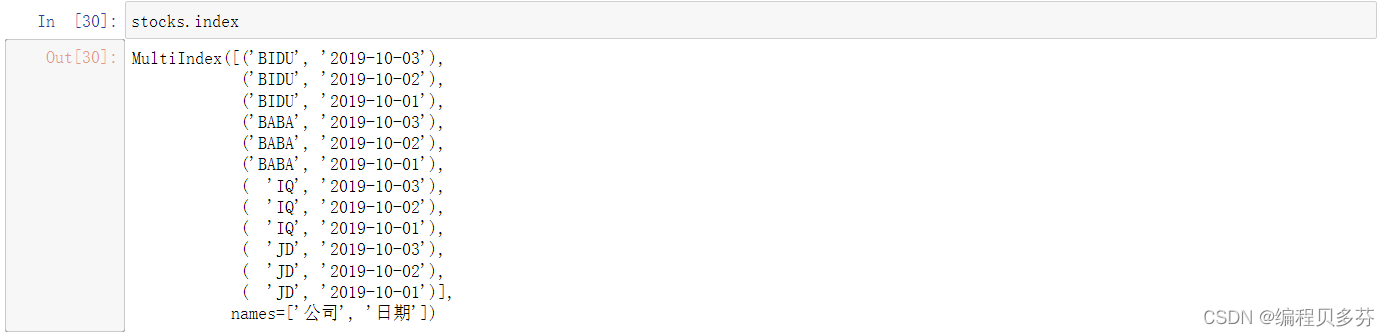
四、DataFrame有多层索引Multilndex怎样筛选数据?
【重要知识】在选择数据时:
。元组(key1.key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD, key2=2019-10-02
·列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD, key2=BIDU
stocks.loc['BIDU']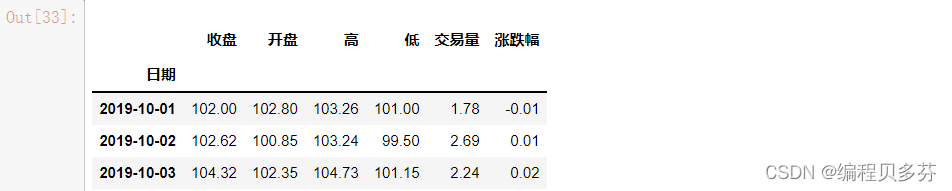
# 'BIDU'是一级索引 '2019-10-02'是二级索引
stocks.loc[('BIDU','2019-10-02'),:] 
stocks.loc[('BIDU','2019-10-02'),'开盘']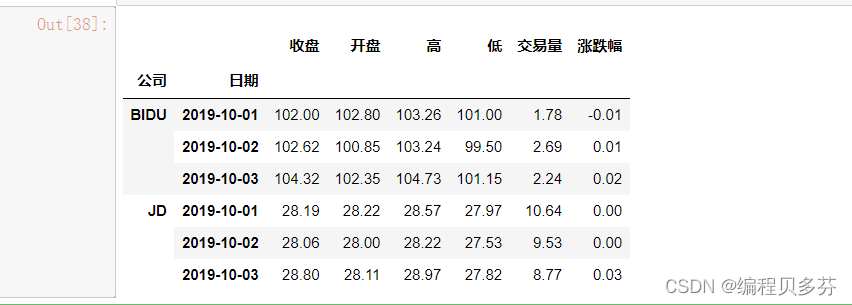
#设置日期的同一级索引的格式
stocks.loc[('BIDU',['2019-10-03','2019-10-02']),'收盘']
#slice(None)代表筛选中一索引的所有内容---在这里的意思就是筛选一级索引‘公司’的所有内容
stocks.loc[(slice(None),['2019-10-03','2019-10-02']),:]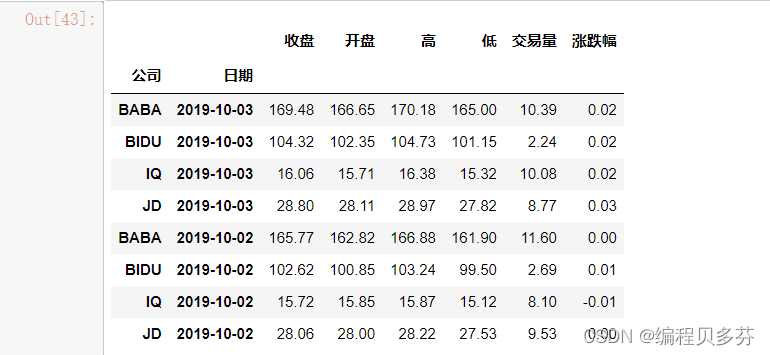
#将多重索引全部重置,转换为一维索引
stocks.reset_index()