文章目录
- 1 问题假设
- 2 步骤
- 3 学习使用Pytorch的API来搭建模型
- 3.1 nn.Model
- 3.2 优化器类
- 3.3 评估模式和训练模式
- 3.4 使用GPU
- data和item的区别
1 问题假设
假设我们的基础模型就是y = wx+b,其中w和b均为参数,我们使用y = 3x+0.8来构造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8。
2 步骤
- 准备数据: x就是随机生成的数,y=3*x+0.8 得到的数据。(也就是说,这里使用的y真实值 是无噪声的,那么可以知道只要epoch次数够就能训练出比较真实的值)
- 初始化要训练的参数;
- 带入参数计算,并且用均方差代表loss
- 梯度清零,反向传播,
tensor.grad中保存的是梯度,更新参数
import torchlearning_rate = 0.01
# 1 准备数据
# y = 3x+0.8x = torch.rand([500, 1]) # 500行1列的随机数,范围是0-1
y_true = x*3 + 0.8# 初始化两个要训练的参数
w = torch.rand([1, 1], requires_grad=True) # 1行1列
b = torch.zeros(1, requires_grad=True)
# 或者写成这样: b = torch.tensor(0, requires_grad=True, dtype=torch.float32)print(w, b)
# 4 通过循环,反向传播,更新参数for i in range(2500):# 2 通过模型计算y_pred# 3 计算lossy_predict = torch.matmul(x, w) + bloss = (y_true - y_predict).pow(2).mean() # 均方误差if w.grad is not None:w.grad.data.zero_() # 归零 (就地修改)if b.grad is not None:b.grad.data.zero_()loss.backward() # 反向传播w.data = w.data - learning_rate * w.gradb.data = b.data - learning_rate * b.gradprint("w, b, loss", w.item(), b.item(), loss.item())
以上代码就是一个模型训练的过程,训练模型的本质就是训练了参数w和b。
输出如下:(因为输出有2500行+,所以只截取最后的结果)
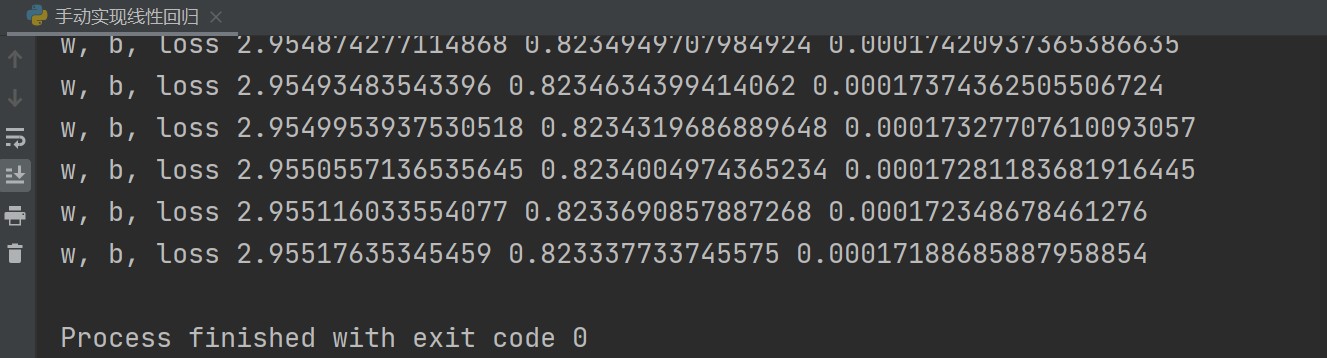
可以看到,最后w收敛到了2.95517635345459, b最后收敛到了0.823337733745575,非常接近w=3 和 b=0.8 。
3 学习使用Pytorch的API来搭建模型
3.1 nn.Model
nn.Model 是torch.nn 提供的一个类,是Pytorch中 微我们自定义网络的一个基类,在这个类中定义了很多有用的方法,让我们在继承这个类 定义网路的时候非常简单。
__init__需要 调用super方法,继承附列的属性和方法。forward方法必须实现,用来定义我们的网络的前向计算的过程。
- 用y = wx+b 的模型举例如下:
import torch
from torch import nnclass Lr(nn.Module):def __init__(self):super(lr, self).__init__() # 继承父类的init的参数self.linear = nn.Linear(1, 1)def forward(self, x):out = self.linear(x)return out
其中:这一行代码是固定的。
super(lr, self).__init__() # 继承父类的init的参数
nn.Linear为 torch 预定好的线性模型,也被称为全连接层,传入的参数为输入的数量和输出的数量(in_features, out_features),是不算(batch_size)的列数的。nn.Module定义了__call__方法,即类Lr的实例,实现的就是调用forward方法,能够直接被传入参数调用,实际上调用的是forward方法并传入参数。
示例:
model = Lr() # 实例化模型
pred = model(x) # 传入数据,计算结果
3.2 优化器类
优化器(optimizer),可以理解为pytorch中封装好了的用来更新参数的方法,比如常见的随机下降(SGD)和Adam。
- 优化器都是由torch.optim提供的:
torch.optim.SGD(参数,学习率)
torch.optim.Adam(参数,学习率)
- 参数可以使用
model.parameters()来获取,获取模型中所有requires_grad=True的参数。 - 优化器使用方法:
①实例化
②所有参数的梯度置零
③反向传播计算梯度
④更新参数值
optimizer = optim.SGD(model.parameters(), lr=1e-3) # 1. 实例化
optimizer.zero_grad() # 2. 梯度置零
loss.backward() # 3. 计算梯度
optimizer.step() # 4. 更新参数的值
- 写代码——调用API来实现线性模型
import torch
import torch.nn as nn
from torch.optim import SGD# 0. 准备数据
x = torch.rand([500, 1])
y_true = 3*x + 0.8# 1. 定义模型
class MyLinear(nn.Module):def __init__(self):super(MyLinear, self).__init__()self.linear = nn.Linear(1, 1)def forward(self, x):out = self.linear(x)return out# 2. 实例化模型,优化器实例化,loss实例化
my_linear = MyLinear()
optimizer = SGD(my_linear.parameters(), 0.001)
loss_fn = nn.MSELoss()# 3. 循环,进行梯度下降,参数的更新
for i in range(5000):# 得到预测值y_predict = my_linear(x)loss = loss_fn(y_predict, y_true)# 梯度置零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()if i%200 == 0:print(loss.item(), list(my_linear.parameters()))

可以看到,用API来实现线性回归的收敛效果没有手动实现的好。(不知道为啥)
3.3 评估模式和训练模式
model.eval() # 表示设置模型为评估模式,即预测模式
model.train(mode=True) # 表示设置模型为训练模式
在目前的线性模型中上述没有什么区别,但是在一些训练和预测时参数不同的模型中,比如说是Dropout, BatchNorm 等存在时,就需要告诉模型是训练还是在预测。
3.4 使用GPU
- 判断GPU是否可用:
torch.cuda.is_available()
torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(device)
>> device(type='cuda', index=0) # 使用GPU
>> device(type='cpu') # 使用CPU
- 把模型参数和 input数据转换为cuda的支持类型 ( 要转的话要一起转,不能一个在cpu上跑 一个在GPU上跑)
model.to(device)
x_true.to(device)
- 在GPU上计算结果也为cuda的数据类型,需要转化为numpy或者cpu的tensor类型(就是说 要把gpu上的值转到cpu上进行一些求均值等等的操作)
predict = predict.cpu().detach().numpy()
detach() 的作用相当于 data,但是detach()是深拷贝,data是取值是浅拷贝。
- 总结:模型放到GPU,那么输入x和输出y_true也要放在GPU,模型的参数也要GPU(如果是内部参数就不需要),最后得到的输出 y_predict 也是GPU类型的。
在GPU上执行程序:
(1)自定义的参数和数据,需要转化为cuda支持的tensor
(2)model需要转化为cuda支持的model
(3)执行的结果需要和cpu的tensor进行计算的时候:
a. tensor.cpu() 把cuda的tensor转化为CPU的tensor
data和item的区别
.data返回的是一个tensor
而.item()返回的是一个具体的数值。
注意:对于元素不止一个的tensor列表,使用item()会报错
list(my_linear.parameters()