- 👏作者简介:大家好,我是爱敲代码的小黄,阿里巴巴淘天Java开发工程师,CSDN博客专家
- 📕系列专栏:Spring源码、Netty源码、Kafka源码、JUC源码、dubbo源码系列
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
- 📝联系方式:hls1793929520,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀

文章目录
- 阿里 P7 三面凉凉,kafka Borker 日志持久化没答上来
- 一、引言
- 二、日志原理介绍
- 二、日志源码
- 1、授权校验
- 2、消息添加
- 2.1 获取 Partition
- 2.2 向 Leader 追加日志
- 2.2.1 是否创建 segment
- 2.2.2 创建 segment
- 2.2.2.1 文件路径校验
- 2.2.2.2 segment 参数
- 2.2.2.3 生成 segment
- 2.2.3 向 segment 添加日志
- 2.2.3.1 稀疏索引
- 2.2.3.2 偏移量索引
- 2.2.3.3 时间戳索引
- 2.2.3.4 索引总结
- 2.2.4 flush刷新
- 2.3 Follow 获取日志
- 三、流程图
- 四、总结
Kafka从成神到成仙系列
- 【Kafka从成神到升仙系列 一】Kafka源码环境搭建
- 【Kafka从成神到升仙系列 二】生产者如何将消息放入到内存缓冲区
- 【Kafka从成神到升仙系列 三】你真的了解 Kafka 的元数据嘛
- 【Kafka从成神到升仙系列 四】你真的了解 Kafka 的缓存池机制嘛
- 【Kafka从成神到升仙系列 五】面试官问我 Kafka 生产者的网络架构,我直接开始从源码背起…
- 【Kafka从成神到升仙系列 六】kafka 不能失去网络通信,就像西方不能失去耶路撒冷
阿里 P7 三面凉凉,kafka Borker 日志持久化没答上来
一、引言
前段时间有个朋友,去面了阿里集团的P7岗位,很遗憾的是三面没有过
其中有一个 kafka Borker 日志如何持久化的问题没有答上来
今天正好写一篇源码文章给朋友复盘一下
虽然现在是互联网寒冬,但乾坤未定,你我皆是黑马!
废话不多说,发车!
二、日志原理介绍
在讲 Kafka 日志源码之前,我们要先对 Kafka 日志有一个大体的认识
这也是阅读源码的关键,一步一步来
前面我们聊到了 Kafka 的生产端的整体架构
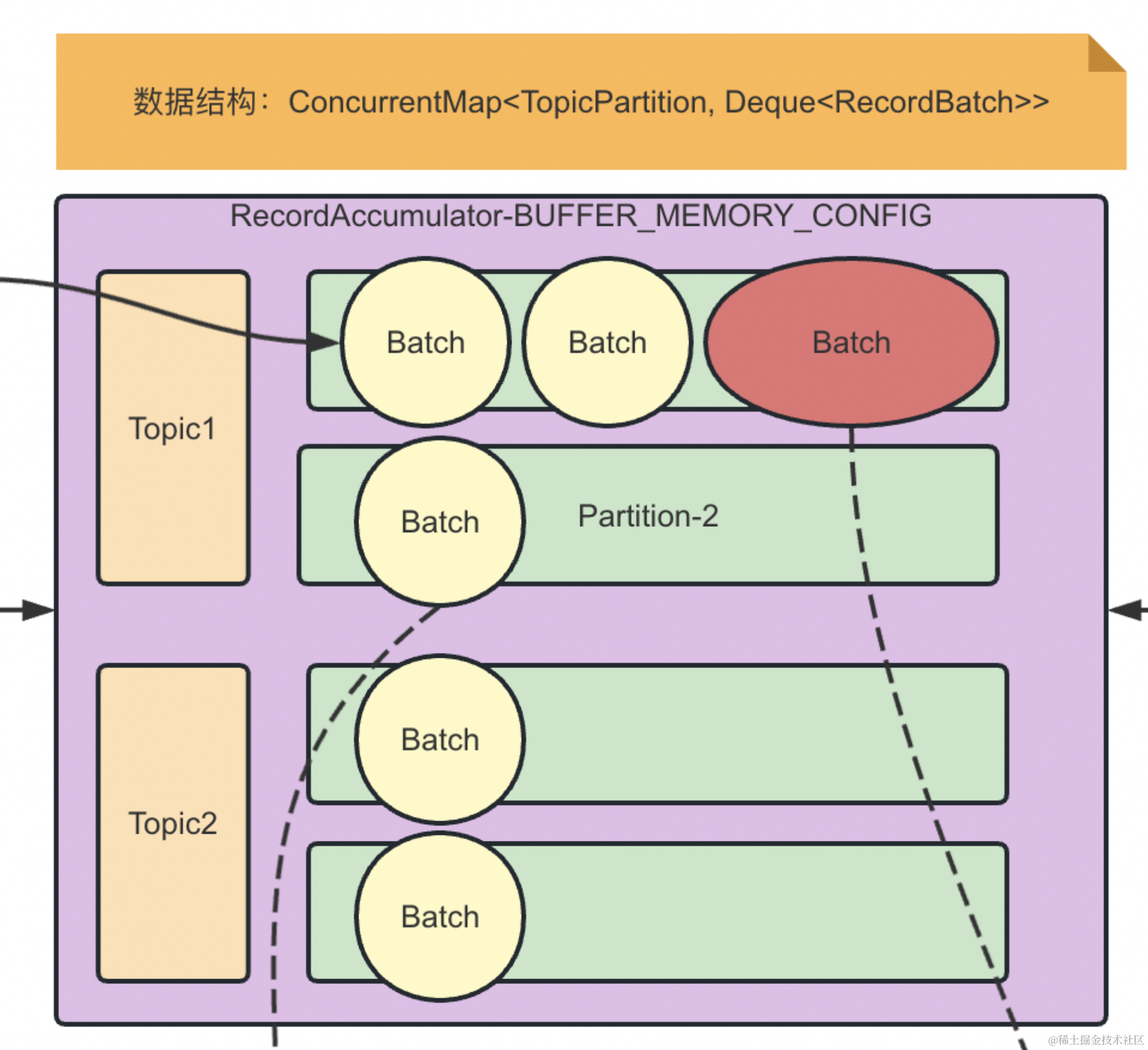
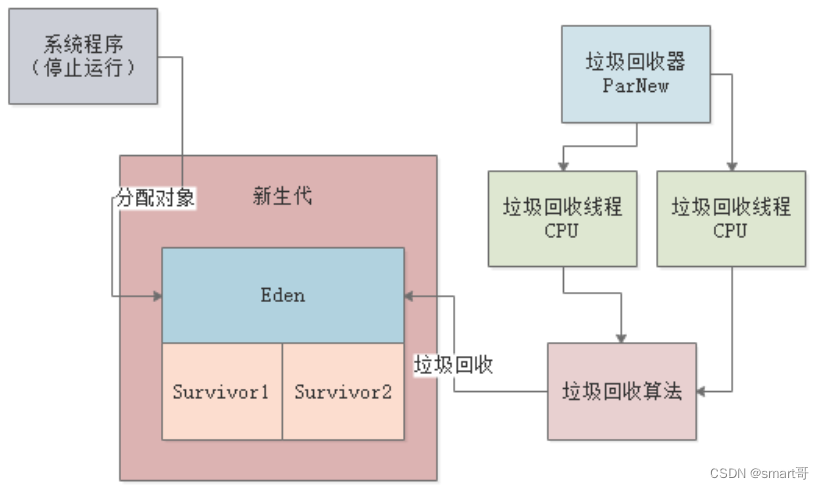
可以看到,我们每一个 Topic 都可以分为多个 Partition ,而每一个 Partition 对应着一个 Log
但这里会存在两个问题,如果我们的数据过大
- 一个
Log能装下吗? - 就算能装下,插入/查询速度怎么保证?
所以,Kafka 在这里引入了日志分段(LogSegment )的概念,将一个 Log 切割成多个 LogSegment 进行存储
实际上,这里的 Log 和 LogSegment 并不是纯粹的物理意义上的概念
Log对应的文件夹LogSegment对应磁盘上的一个日志文件和两个索引文件- 日志文件:以
.log为文件后缀 - 两个索引文件:
- 偏移量索引文件(以
.index为文件后缀) - 时间戳索引文件(以
.timeindex为文件后缀)
- 偏移量索引文件(以
- 日志文件:以
这里有个重点要记一下:每个 LogSegment 都有一个基准偏移量 baseOffset,用来表示当前 LogSegment 第一条消息的 offset
日志和索引文件命名都是按照基准偏移量进行命名,所以日志整体架构如下:
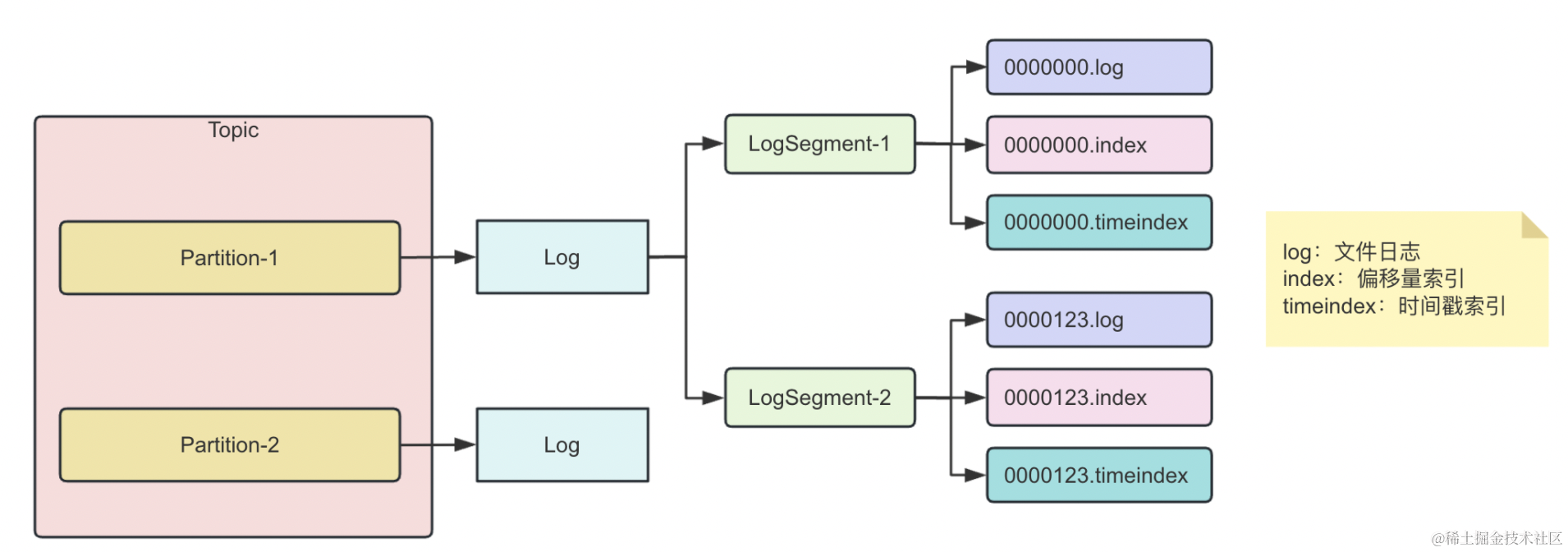
这里我们简单介绍下这个日志是怎么搜索的,后面会深入源码细聊
二、日志源码
我们回顾一下上篇文章的整体流程图:
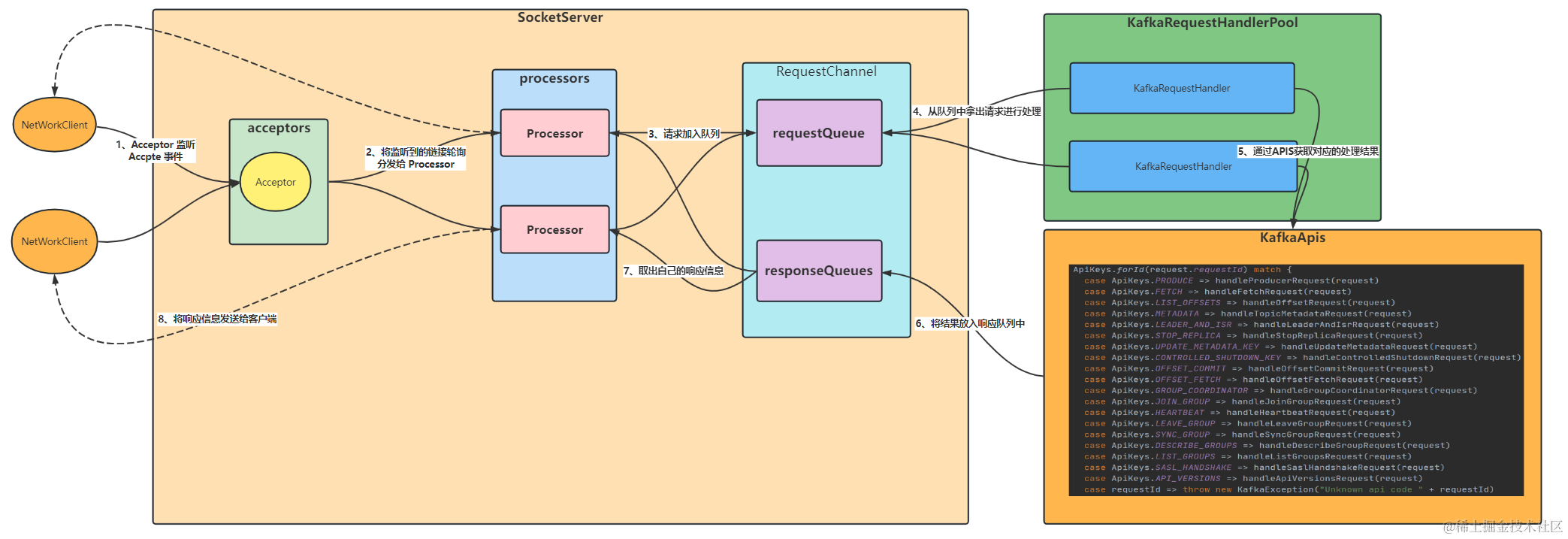
我们可以看到,消息的处理是通过 KafkaApis 来进行的,日志持久化通过 case ApiKeys.PRODUCE => handleProduceRequest(request)
本篇我们也围绕这个方法展开
1、授权校验
def handleProduceRequest(request: RequestChannel.Request) {// authorizedRequestInfo:存储通过授权验证的主题分区和对应的内存记录。val authorizedRequestInfo = mutable.Map[TopicPartition, MemoryRecords]()for ((topicPartition, memoryRecords) <- produceRequest.partitionRecordsOrFail.asScala) {if (!authorize(request.session, Write, Resource(Topic, topicPartition.topic, LITERAL)))// 未授权的unauthorizedTopicResponses += topicPartition -> new PartitionResponse(Errors.TOPIC_AUTHORIZATION_FAILED)else if (!metadataCache.contains(topicPartition))nonExistingTopicResponses += topicPartition -> new PartitionResponse(Errors.UNKNOWN_TOPIC_OR_PARTITION)elsetry {// 授权的ProduceRequest.validateRecords(request.header.apiVersion(), memoryRecords)authorizedRequestInfo += (topicPartition -> memoryRecords)} catch {case e: ApiException =>invalidRequestResponses += topicPartition -> new PartitionResponse(Errors.forException(e))}}
}
2、消息添加
- 【重点】timeout:超时时间
- 【重点】requiredAcks:指定了在记录追加到副本后需要多少个副本进行确认,才认为写操作成功
0: 不需要任何副本的确认1: 只需要主副本确认-1或all: 需要所有副本的确认
internalTopicsAllowed:是否允许将记录追加到内部主题isFromClient:请求是否来自客户端- 【重点】
entriesPerPartition:包含了通过授权验证的主题分区和对应的内存记录 responseCallback:回调函数,在记录追加完成后,会调用该回调函数发送响应给客户端。recordConversionStatsCallback:处理记录转换统计信息的逻辑
replicaManager.appendRecords(timeout = produceRequest.timeout.toLong,requiredAcks = produceRequest.acks,internalTopicsAllowed = internalTopicsAllowed,isFromClient = true,entriesPerPartition = authorizedRequestInfo,responseCallback = sendResponseCallback,recordConversionStatsCallback = processingStatsCallback)
我们主要关心这三个参数即可:timeout、requiredAcks、entriesPerPartition,其余的目前不太重要
def appendRecords(timeout: Long,requiredAcks: Short,internalTopicsAllowed: Boolean,isFromClient: Boolean,entriesPerPartition: Map[TopicPartition, MemoryRecords],responseCallback: Map[TopicPartition, PartitionResponse] => Unit,delayedProduceLock: Option[Lock] = None,recordConversionStatsCallback: Map[TopicPartition, RecordConversionStats] => Unit = _ => ()) {// 校验当前的ACKif (isValidRequiredAcks(requiredAcks)) {// 记录起始时间val sTime = time.milliseconds// 追加本地日志val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,isFromClient = isFromClient, entriesPerPartition, requiredAcks)}
}// 允许当前的ACK为1、0、-1
private def isValidRequiredAcks(requiredAcks: Short): Boolean = {requiredAcks == -1 || requiredAcks == 1 || requiredAcks == 0
}
这里的追加本地日志就是我们本篇的重点
2.1 获取 Partition
private def appendToLocalLog(internalTopicsAllowed: Boolean,isFromClient: Boolean,entriesPerPartition: Map[TopicPartition, MemoryRecords],requiredAcks: Short): Map[TopicPartition, LogAppendResult] = {val partition = getPartitionOrException(topicPartition, expectLeader = true)
}// 根据给定的主题分区获取对应的分区对象
def getPartitionOrException(topicPartition: TopicPartition, expectLeader: Boolean): Partition = {// 获取Partition并匹配getPartition(topicPartition) match {case Some(partition) =>if (partition eq ReplicaManager.OfflinePartition)throw new KafkaStorageException()elsepartitioncase None if metadataCache.contains(topicPartition) =>if (expectLeader) {throw new NotLeaderForPartitionException()} else {throw new ReplicaNotAvailableException()}}}
2.2 向 Leader 追加日志
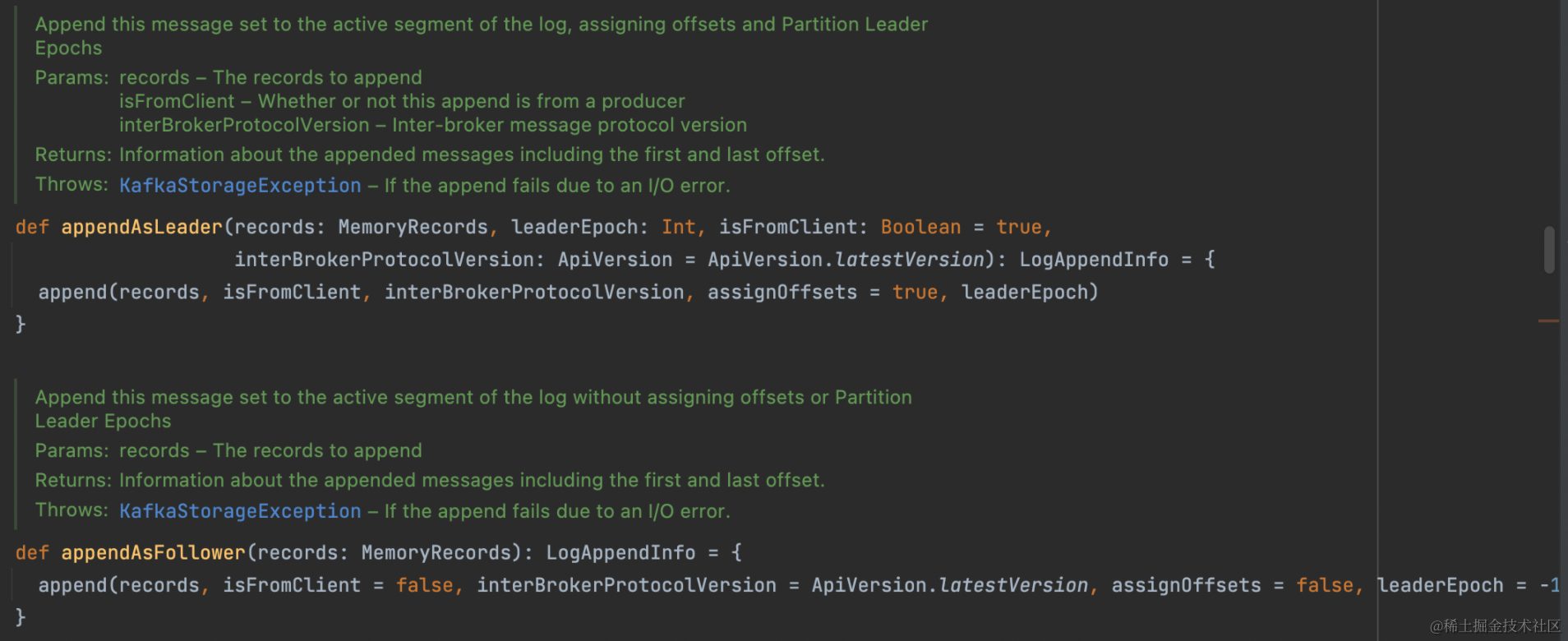
val info = partition.appendRecordsToLeader(records, isFromClient, requiredAcks);def appendRecordsToLeader(records: MemoryRecords, isFromClient: Boolean, requiredAcks: Int = 0): LogAppendInfo = {val info = log.appendAsLeader(records, leaderEpoch = this.leaderEpoch, isFromClient,interBrokerProtocolVersion)
}def appendAsLeader(records: MemoryRecords, leaderEpoch: Int, isFromClient: Boolean = true,interBrokerProtocolVersion: ApiVersion = ApiVersion.latestVersion): LogAppendInfo = {append(records, isFromClient, interBrokerProtocolVersion, assignOffsets = true, leaderEpoch)}
2.2.1 是否创建 segment
这里就到了我们一开始图中的 LogSegment
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo);private def maybeRoll(messagesSize: Int, appendInfo: LogAppendInfo): LogSegment = {// 如果应该滚动,创建一个新的segment// 反之,则返回当前的segmentif (segment.shouldRoll(RollParams(config, appendInfo, messagesSize, now))) {appendInfo.firstOffset match {case Some(firstOffset) => roll(Some(firstOffset))case None => roll(Some(maxOffsetInMessages - Integer.MAX_VALUE))}} else {segment}}
一共有六个条件,触发这六个条件,就会重新创建一个 segment
timeWaitedForRoll(rollParams.now, rollParams.maxTimestampInMessages) > rollParams.maxSegmentMs - rollJitterMs:判断时间等待是不是超时size > rollParams.maxSegmentBytes - rollParams.messagesSize:当前segment是否有充足的空间存储当前信息size > 0 && reachedRollMs:当前日志段的大小大于0,并且达到了进行日志分段的时间条件reachedRollMsoffsetIndex.isFull:偏移索引满了timeIndex.isFull:时间戳索引满了!canConvertToRelativeOffset(rollParams.maxOffsetInMessages):无法进行相对偏移的转换操作
class LogSegment private[log] (val log: FileRecords,val offsetIndex: OffsetIndex,val timeIndex: TimeIndex,val txnIndex: TransactionIndex,val baseOffset: Long,val indexIntervalBytes: Int,val rollJitterMs: Long,val time: Time) extends Logging {def shouldRoll(rollParams: RollParams): Boolean = {val reachedRollMs = timeWaitedForRoll(rollParams.now, rollParams.maxTimestampInMessages) > rollParams.maxSegmentMs - rollJitterMssize > rollParams.maxSegmentBytes - rollParams.messagesSize ||(size > 0 && reachedRollMs) ||offsetIndex.isFull || timeIndex.isFull || !canConvertToRelativeOffset(rollParams.maxOffsetInMessages)
}
整体来看,六个条件也比较简单,我们继续往后看
2.2.2 创建 segment
appendInfo.firstOffset match {// 存在第一个偏移量case Some(firstOffset) => roll(Some(firstOffset))// 不存在第一个偏移量case None => roll(Some(maxOffsetInMessages - Integer.MAX_VALUE))
}
2.2.2.1 文件路径校验
def roll(expectedNextOffset: Option[Long] = None): LogSegment = {// 获取最新的offsetval newOffset = math.max(expectedNextOffset.getOrElse(0L), logEndOffset)// 获取日志文件路径val logFile = Log.logFile(dir, newOffset)// 获取偏移量索引文件路径val offsetIdxFile = offsetIndexFile(dir, newOffset)// 获取时间戳索引文件路径val timeIdxFile = timeIndexFile(dir, newOffset)// 获取事务索引文件路径val txnIdxFile = transactionIndexFile(dir, newOffset)// 对路径列表进行遍历,如果文件存在,则将其删除。for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if file.exists) {Files.delete(file.toPath)}
}
2.2.2.2 segment 参数
- dir:日志段所在的目录
- baseOffset:日志段的基准偏移量
- config:日志的配置信息
- time:时间对象,用于处理时间相关的操作。
- fileAlreadyExists:指示日志文件是否已经存在
- initFileSize:初始文件大小
- preallocate:是否预分配文件空间
- fileSuffix:文件后缀
val segment = LogSegment.open(dir,baseOffset = newOffset,config,time = time,fileAlreadyExists = false,initFileSize = initFileSize,preallocate = config.preallocate)
2.2.2.3 生成 segment
new LogSegment(// 生成日志文件FileRecords.open(Log.logFile(dir, baseOffset, fileSuffix), fileAlreadyExists, initFileSize, preallocate),// 生成偏移量索引new OffsetIndex(Log.offsetIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),// 生成时间戳索引new TimeIndex(Log.timeIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),// 生成事务索引new TransactionIndex(baseOffset, Log.transactionIndexFile(dir, baseOffset, fileSuffix)),// 基准偏移量baseOffset,indexIntervalBytes = config.indexInterval,rollJitterMs = config.randomSegmentJitter,time)
这里有一个重点需要关注一下,那就是 mmap 的零拷贝
OffsetIndex 和 TimeIndex 他们继承 AbstractIndex ,而 AbstractIndex 中使用 mmp 作为 buffer
class OffsetIndex(_file: File, baseOffset: Long, maxIndexSize: Int = -1, writable: Boolean = true) extends AbstractIndex[Long, Int](_file, baseOffset, maxIndexSize, writable) abstract class AbstractIndex{protected var mmap: MappedByteBuffer = {};
}
另外,这里先提一个知识点,后面会专门写一篇文章来分析一下
我们索引在查询的时候,采用的是二分查找的方式,这会导致 缺页中断,于是 kafka 将二分查找进行改进,将索引区分为 冷区 和 热区,分别搜索,尽可能保证热区的页在 Page Cache 里面,从而避免缺页中断。
当我们的 segment 生成完之后,就返回了
2.2.3 向 segment 添加日志
segment.append(largestOffset = appendInfo.lastOffset,largestTimestamp = appendInfo.maxTimestamp,shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,records = validRecords)def append(largestOffset: Long,largestTimestamp: Long,shallowOffsetOfMaxTimestamp: Long,records: MemoryRecords): Unit = {if (records.sizeInBytes > 0) {// 添加日志val appendedBytes = log.append(records)}// 当累加超过多少时,才会进行索引的写入// indexIntervalBytes 默认 1048576 字节(1MB)if (bytesSinceLastIndexEntry > indexIntervalBytes) {// 添加偏移量索引offsetIndex.append(largestOffset, physicalPosition)// 添加时间戳索引timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)// 归0bytesSinceLastIndexEntry = 0}// 累加bytesSinceLastIndexEntry += records.sizeInBytes
}// lastOffset + 1
updateLogEndOffset(appendInfo.lastOffset + 1)
2.2.3.1 稀疏索引
kafka 中的偏移量索引和时间戳索引都属于稀疏索引
何为稀疏索引?
正常来说,我们会为每一个日志都创建一个索引,比如:
日志 索引
1 1
2 2
3 3
4 4
但这种方式比较浪费,于是采用稀疏索引,如下:
日志 索引
1 1
2
3
4
5 2
6
7
8
当我们根据偏移量索引查询 1 时,可以查询到日志为 1 的,然后往下遍历搜索想要的即可。
2.2.3.2 偏移量索引
offsetIndex.append(largestOffset, physicalPosition)def append(offset: Long, position: Int) {inLock(lock) {// 索引位置mmap.putInt(relativeOffset(offset))// 日志位置mmap.putInt(position)_entries += 1_lastOffset = offset}
}// 用当前offset减去基准offset
def relativeOffset(offset: Long): Int = {val relativeOffset = offset - baseOffset
}
2.2.3.3 时间戳索引
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)def maybeAppend(timestamp: Long, offset: Long, skipFullCheck: Boolean = false) {inLock(lock) {if (timestamp > lastEntry.timestamp) {// 添加时间戳mmap.putLong(timestamp)// 添加相对位移(偏移量索引)mmap.putInt(relativeOffset(offset))_entries += 1_lastEntry = TimestampOffset(timestamp, offset)}}
}
2.2.3.4 索引总结
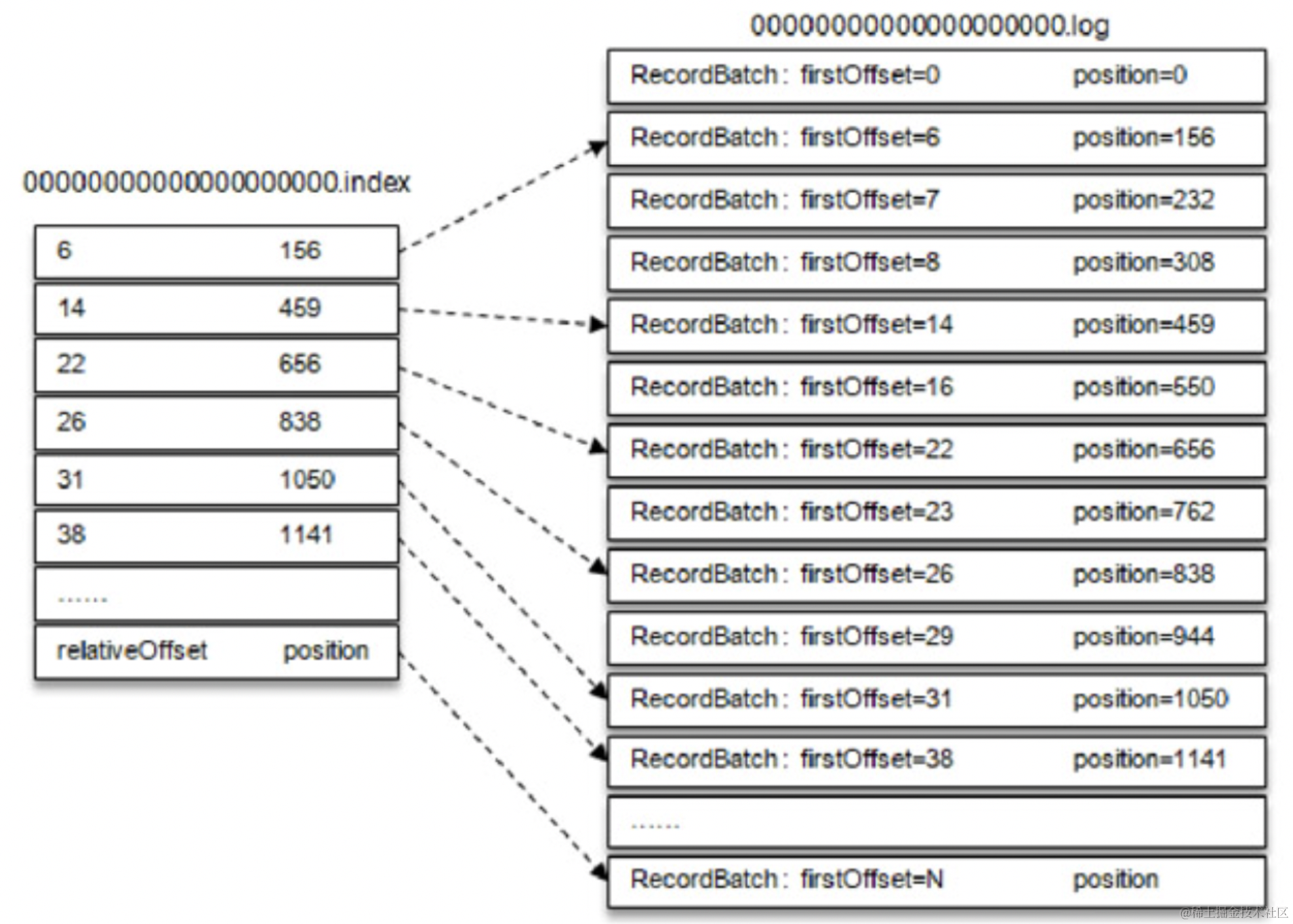
我们的偏移量索引如图下所示:
- 当我们查询一个消息时,比如消息位移为
23的- 根据二分查找找到偏移量索引下标
22 - 利用上述我们偏移量
Map的存储,得到其日志位置RecordBatch:firstOffset=23 position=762 - 再根据日志位置,找到真正存储日志的地方
- 根据二分查找找到偏移量索引下标
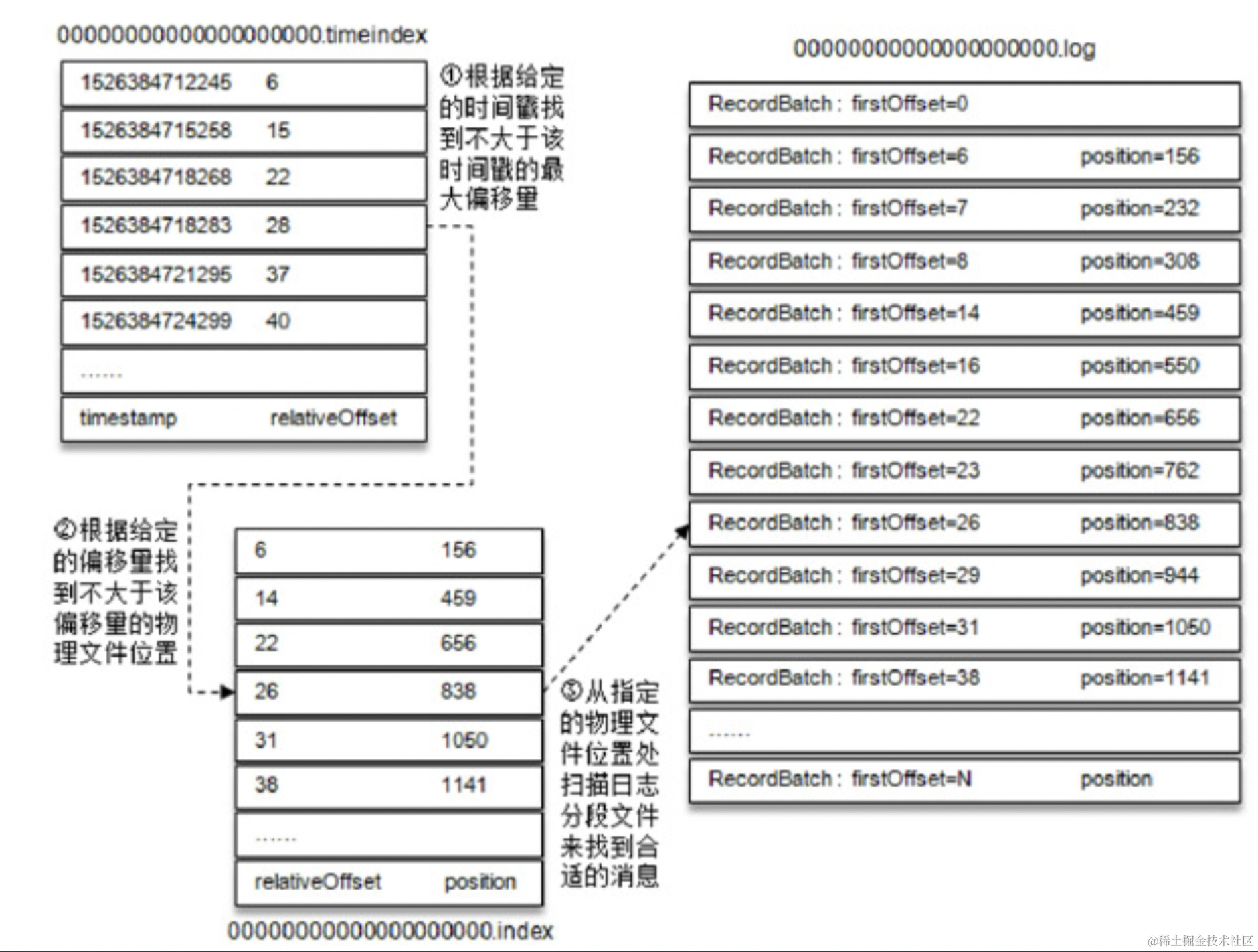
我们的时间戳索引如图下所示:
- 基本和我们的偏移量索引类似,只是增加了一层二分查找
2.2.4 flush刷新
在我们前面添加完之后,我们的数据仅仅是写到 PageCache 里面,需要进行 flush 将其刷新到磁盘中
// 未刷新消息数(unflushedMessages)超过配置的刷新间隔(flushInterval)
if (unflushedMessages >= config.flushInterval){flush()
}def flush() {LogFlushStats.logFlushTimer.time {// 日志刷新log.flush()// 偏移量索引刷新offsetIndex.flush()// 时间戳索引刷新timeIndex.flush()// 事务索引刷新txnIndex.flush()}}
2.3 Follow 获取日志
同样,我们的 Follow 在获取日志时,和我们 Leader 添加日志时一样的方法
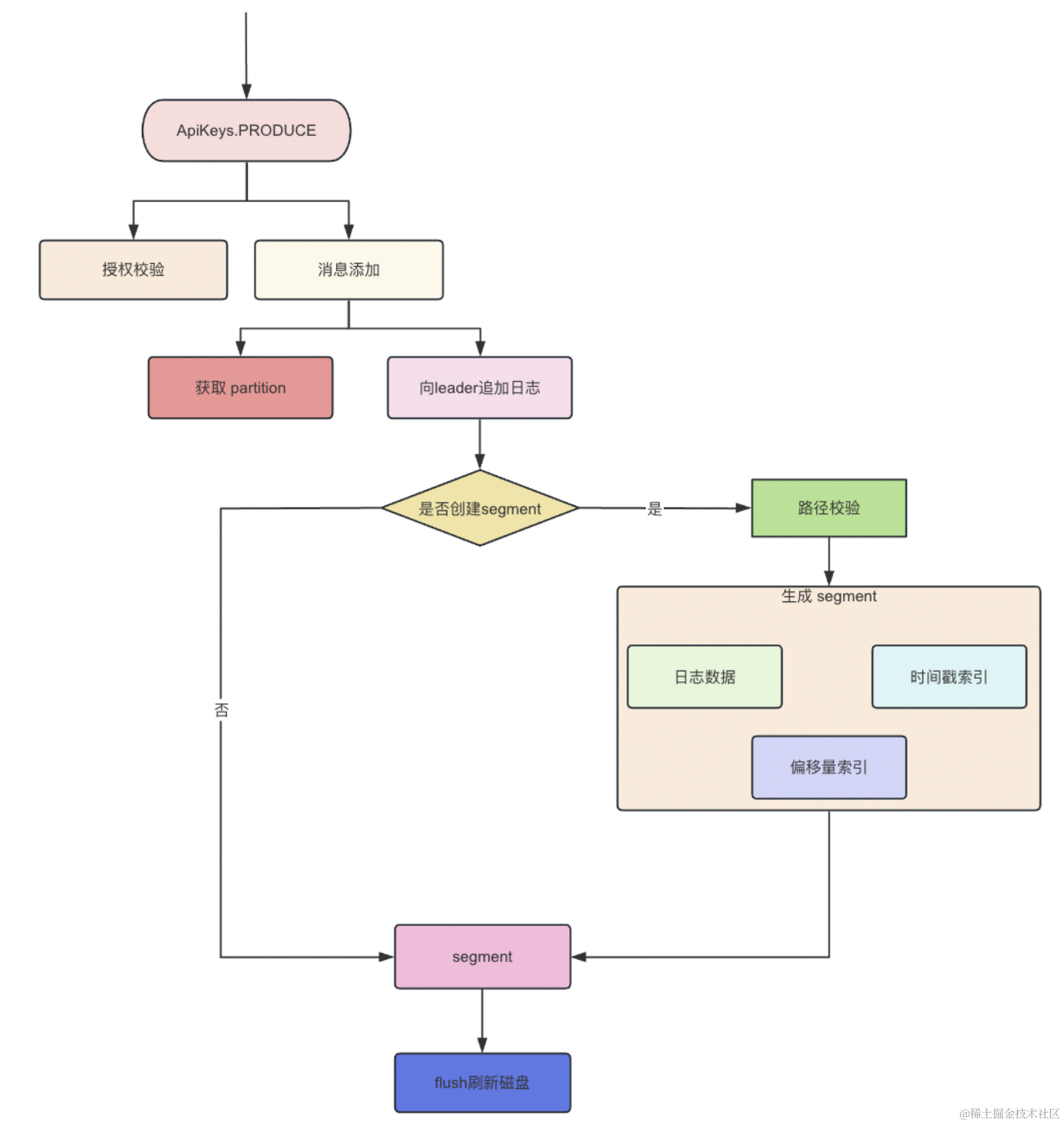
三、流程图
四、总结
这一篇我们介绍了 Kafka 中日志时如何持久化的以及 Kafka 日志中包括什么数据
鲁迅先生曾说:独行难,众行易,和志同道合的人一起进步。彼此毫无保留的分享经验,才是对抗互联网寒冬的最佳选择。
其实很多时候,并不是我们不够努力,很可能就是自己努力的方向不对,如果有一个人能稍微指点你一下,你真的可能会少走几年弯路。
如果你也对 后端架构 和 中间件源码 有兴趣,欢迎添加博主微信:hls1793929520,一起学习,一起成长
我是爱敲代码的小黄,阿里巴巴淘天集团Java开发工程师,双非二本,培训班出身
通过两年努力,成功拿下阿里、百度、美团、滴滴等大厂,想通过自己的事迹告诉大家,努力是会有收获的!
双非本两年经验,我是如何拿下阿里、百度、美团、滴滴、快手、拼多多等大厂offer的?
我们下期再见。
从清晨走过,也拥抱夜晚的星辰,人生没有捷径,你我皆平凡,你好,陌生人,一起共勉。