网站行为日志信息统计分析
- 一、开发环境
- 二、项目思路
- 三、系统实现
- (一)、原始数据上传hdfs
- (二)、数据清洗(第一遍)
- (三)、数据清洗(第二遍)
- (三)、通过hive对数据分析
- 四、总结
- 五、完整代码:
- (一)、pom.xml文件
- (二)、初始数据清洗:截取需要字段
- (三)、数据清洗:清理网络连接中的资源文件和清洗不完整数据
一、开发环境
(一)、开发环境:
Windows + JDK1.8 + Hadop-2.9.2+Eclipse+linux
(二)、需要的只知识:
hdfs、mapreduce、hive、简单正则表达式、用户画像等等
(三)、开发时间:2019年1月
二、项目思路
(一)、对以采集的信息先上传到hdfs上
(二)、通过打标签,对网站进行用指标画像,提取出最能描述网站指标的字段,对网站性能负载进行综合调整、评估、优化!
(三)、根据对网站指标画提取出的特征字段,对数据进行清洗
(四)、分析网站的访问量,跳出率,网络连接状态,单个ip流量的总和等 ,对网站进行研究和分析
三、系统实现
(一)、原始数据上传hdfs
1、原始数据格式

2、上传到hdfs上:
hadoop dfs -put ./access_2015_03_30.log /
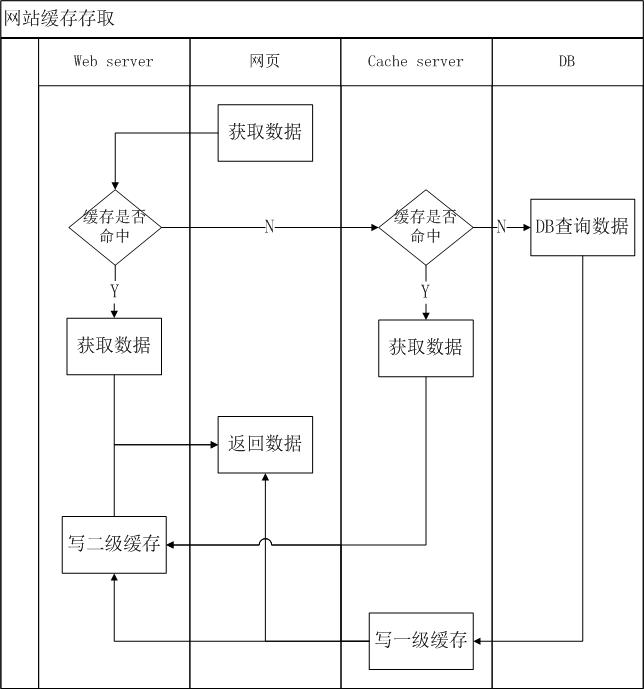
(二)、数据清洗(第一遍)
1、利用正则表达式对原始数据处理,提取出想要的字段:
我对网址指标画像的字段是:
ip,time,timeArea,request,url,state,dataSize
public String[] parser(String line) {String str="27.19.74.143 - - [30/Mar/2015:17:38:20 +0800] \"GET /static/image/common/faq.gif HTTP/1.1\" 200 1127";//Pattern.compile("(27.19.74.143) - - \\[(30/Mar/2015:17:38:20) ( +0800)\\] \"(GET) (.*) HTTP/1.1\" (200) (1127)");Pattern compile = Pattern.compile("([0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}) - - \\[(.*) ([-|+][0-9]{1,4})\\] \"([A-Z]{1,4}) (.*) HTTP/1.1\" ([0-9]*) ([0-9]*)");Matcher matcher = compile.matcher(line);//System.out.println(matcher.find());while(matcher.find()){if (matcher.group() != null) {System.out.println("成功!");String ip = matcher.group(1);String time = matcher.group(2);String timeArea = matcher.group(3);String request = matcher.group(4);String url = matcher.group(5);String state = matcher.group(6);String dataSize = matcher.group(7);SimpleDateFormat sdf1 = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.ENGLISH);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");Date date;try {date = sdf1.parse(time);time = sdf.format(date);} catch (ParseException e) {// TODO Auto-generated catch blocke.printStackTrace();}return new String[]{ip,time,timeArea,request,url,state,dataSize};}}return new String[]{};}(三)、数据清洗(第二遍)
1、通过mapreduce对已经提取出的字段再次清洗:清理网络连接中的资源文件和清理不完整数据
public class clean {static final String INPUT_PATH = "hdfs://192.168.56.30:9000/access_2015_03_30.log";static final String OUT_PATH = "hdfs://192.168.56.30:9000/user/hive/warehouse/t1";public static void main(String[] args) throws Exception {String str="27.19.74.143 - - [30/Mar/2015:17:38:20 +0800] \"GET /static/image/common/faq.gif HTTP/1.1\" 200 1127";System.out.println("==========================数据清洗============================");String[] parser = new LongParser().parser(str);for (int i = 0; i < parser.length; i++) {System.out.println("字段:"+(i+1)+" : "+parser[i]);}System.out.println("==========================数据清洗============================");Configuration conf = new Configuration();Job job =Job.getInstance(conf,clean.class.getSimpleName());job.setJarByClass(clean.class);//打jar包必须在这一行//文件的输入格式FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));job.setInputFormatClass(TextInputFormat.class);//map序列化job.setMapperClass(MyMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Text.class);//reduce序列化job.setReducerClass(MyReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//文件的输出格式String OUT_DIR =OUT_PATH;FileOutputFormat.setOutputPath(job, new Path(OUT_DIR));job.setOutputFormatClass(TextOutputFormat.class);//判断输出文件是否存在,若存在,则删除deleteOutDir(conf, OUT_DIR);job.waitForCompletion(true);}private static void deleteOutDir(Configuration conf, String OUT_DIR) throws IOException, URISyntaxException {FileSystem fileSystem = FileSystem.get(new URI(OUT_DIR), conf);if(fileSystem.exists(new Path(OUT_DIR))){fileSystem.delete(new Path(OUT_DIR), true);}}public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text>{@Overrideprotected void map(LongWritable key, Text value,org.apache.hadoop.mapreduce.Mapper<LongWritable,Text,LongWritable,Text>.Context context)throws IOException ,InterruptedException {String line = value.toString();String[] parser = new LongParser().parser(line);//清理网络连接中的资源文件if (line.contains(".gif")||line.contains("jpg")||line.contains("png")||line.contains(".css")||line.contains(".js")) {return;}//清理不完整数据if(parser.length != 7){return;}Text text = new Text();text.set(parser[0]+"\t"+parser[1]+"\t"+parser[2]+"\t"+parser[3]+"\t"+parser[4]+"\t"+parser[5]+"\t"+parser[6]+"\t");context.write(key, text);}}public static class MyReducer extends Reducer<LongWritable,Text, Text, NullWritable>{@Overrideprotected void reduce(LongWritable arg0, Iterable<Text>text,Reducer<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// TODO Auto-generated method stubfor (Text value : text) {context.write(value, NullWritable.get());}}}}
(三)、通过hive对数据分析
1、创建表
create table t1(ip String,
time String,
timeArea String,
request String,
url String,
State String,
dataSize int
)row format delimited fields terminated by "\t";
2、pageview:用户的总访问量
select count(1) as PV from t1;
3、uv:独立用户(去重)
select count(distinct ip) as UV from t1;
4、只浏览了一次就离开的用户
select count(1) from t1 group by ip having count(1)=1;
5、只浏览了一次就离开用户的总数
select count(1) from (select count(1) from t1 group by ip having count(1)=1) nums;
6、所有浏览的总数
select ip,count(1) as nums from t1 group by ip;
7、跳出率
select sum(case when a.nums=1 then 1 else 0 end)/sum(1)
from(select count(1) as nums from t1 group by ip) a;
结果:7348/21645=0.33947793947793947
跳出率(取精度):round()
select round(sum(case when a.nums=1 then 1 else 0 end)/sum(1)*100,2)
from(select count(1) as nums from t1 group by ip) a;
结果:33.95
跳出率(字符转换):concat()
select concat(round(sum(case when a.nums=1 then 1 else 0 end)/sum(1)*100,2),"%")
from(select count(1) as nums from t1 group by ip) a;
结果:33.95%
8、ip浏览量的top100
select ip,count(1) as nums from t1 group by ip sort by nums desc limit 100;
9、统计时区
select timeArea,count(1) from t1 group by timeArea;
10、统计页面热点
select url,count(1) as nums from t1 group by url sort by nums desc limit 100;
11、网站用户连接状态
select state,count(1) as nums from t1 group by state;
12、单个ip流量的总和
select ip,sum(dataSize) as totalSize from t1 group by ip sort by totalSize desc limit 100;
四、总结
通过完成此次项目,学到了很多东西!我觉得最难的地方是正则表达式,因为以前用正则表达式较少,所以就没有学习正则表达式,真到用的时候不会,很着急!就只好现学了,通过本次项目,对正则表达式有了新的认识和理解。通过这次项目对用户画像,如何给某一事物打标签有了深刻的了解,同时也对mapreduce这一知识进行了复习掌握,最终要的是对hive的掌握也有了一定程度上的提升!真的是受益颇多!
五、完整代码:
(一)、pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>Clean</groupId><artifactId>clean</artifactId><version>0.0.1-SNAPSHOT</version><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.2.0</version></dependency><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>D:/java/jdk1.8/lib/tools.jar</systemPath></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.2.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.2.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.2.0</version></dependency><!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version>
</dependency><!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope>
</dependency></dependencies></project>
初始数据清洗:截取需要字段
(二)、初始数据清洗:截取需要字段
package data;import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class LongParser {public String[] parser(String line) {String str="27.19.74.143 - - [30/Mar/2015:17:38:20 +0800] \"GET /static/image/common/faq.gif HTTP/1.1\" 200 1127";//Pattern.compile("(27.19.74.143) - - \\[(30/Mar/2015:17:38:20) ( +0800)\\] \"(GET) (.*) HTTP/1.1\" (200) (1127)");Pattern compile = Pattern.compile("([0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}) - - \\[(.*) ([-|+][0-9]{1,4})\\] \"([A-Z]{1,4}) (.*) HTTP/1.1\" ([0-9]*) ([0-9]*)");Matcher matcher = compile.matcher(line);//System.out.println(matcher.find());while(matcher.find()){if (matcher.group() != null) {System.out.println("成功!");String ip = matcher.group(1);String time = matcher.group(2);String timeArea = matcher.group(3);String request = matcher.group(4);String url = matcher.group(5);String state = matcher.group(6);String dataSize = matcher.group(7);SimpleDateFormat sdf1 = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.ENGLISH);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");Date date;try {date = sdf1.parse(time);time = sdf.format(date);} catch (ParseException e) {// TODO Auto-generated catch blocke.printStackTrace();}return new String[]{ip,time,timeArea,request,url,state,dataSize};}}return new String[]{};}}(三)、数据清洗:清理网络连接中的资源文件和清洗不完整数据
package data;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;public class clean {static final String INPUT_PATH = "hdfs://192.168.56.30:9000/access_2015_03_30.log";static final String OUT_PATH = "hdfs://192.168.56.30:9000/user/hive/warehouse/t1";public static void main(String[] args) throws Exception {String str="27.19.74.143 - - [30/Mar/2015:17:38:20 +0800] \"GET /static/image/common/faq.gif HTTP/1.1\" 200 1127";System.out.println("==========================数据清洗============================");String[] parser = new LongParser().parser(str);for (int i = 0; i < parser.length; i++) {System.out.println("字段:"+(i+1)+" : "+parser[i]);}System.out.println("==========================数据清洗============================");Configuration conf = new Configuration();Job job =Job.getInstance(conf,clean.class.getSimpleName());job.setJarByClass(clean.class);//打jar包必须在这一行//文件的输入格式FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));job.setInputFormatClass(TextInputFormat.class);//map序列化job.setMapperClass(MyMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Text.class);//reduce序列化job.setReducerClass(MyReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//文件的输出格式String OUT_DIR =OUT_PATH;FileOutputFormat.setOutputPath(job, new Path(OUT_DIR));job.setOutputFormatClass(TextOutputFormat.class);//判断输出文件是否存在,若存在,则删除deleteOutDir(conf, OUT_DIR);job.waitForCompletion(true);}private static void deleteOutDir(Configuration conf, String OUT_DIR) throws IOException, URISyntaxException {FileSystem fileSystem = FileSystem.get(new URI(OUT_DIR), conf);if(fileSystem.exists(new Path(OUT_DIR))){fileSystem.delete(new Path(OUT_DIR), true);}}public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text>{@Overrideprotected void map(LongWritable key, Text value,org.apache.hadoop.mapreduce.Mapper<LongWritable,Text,LongWritable,Text>.Context context)throws IOException ,InterruptedException {String line = value.toString();String[] parser = new LongParser().parser(line);//清理网络连接中的资源文件if (line.contains(".gif")||line.contains("jpg")||line.contains("png")||line.contains(".css")||line.contains(".js")) {return;}//清理不完整数据if(parser.length != 7){return;}Text text = new Text();text.set(parser[0]+"\t"+parser[1]+"\t"+parser[2]+"\t"+parser[3]+"\t"+parser[4]+"\t"+parser[5]+"\t"+parser[6]+"\t");context.write(key, text);}}public static class MyReducer extends Reducer<LongWritable,Text, Text, NullWritable>{@Overrideprotected void reduce(LongWritable arg0, Iterable<Text>text,Reducer<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// TODO Auto-generated method stubfor (Text value : text) {context.write(value, NullWritable.get());}}}}