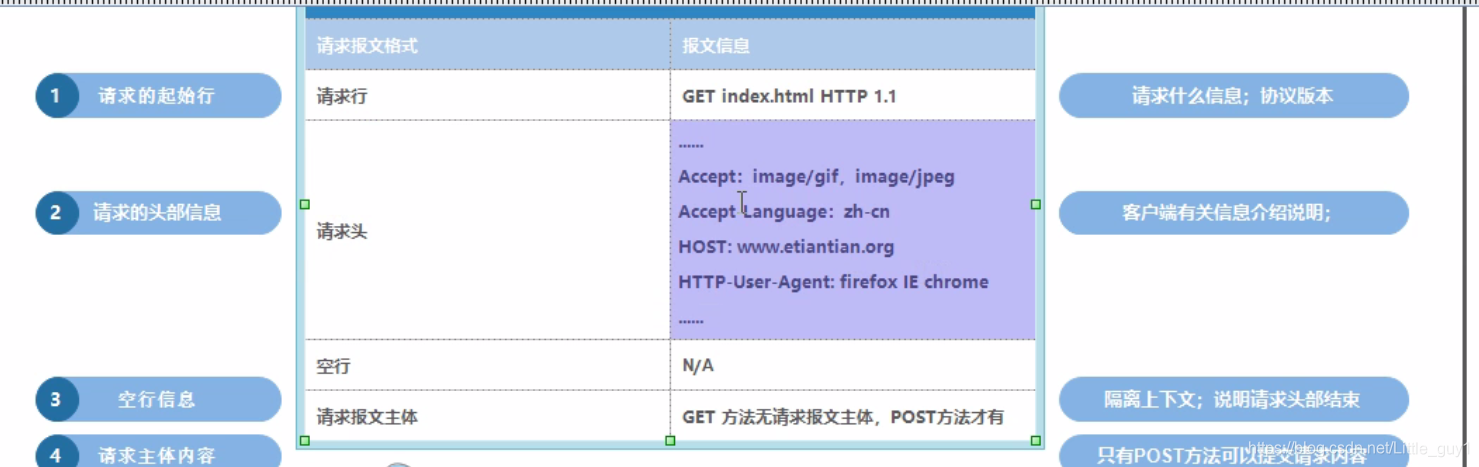
from bs4 import BeautifulSoup import requests import osdef getdepotdetailcontent(title,url):#爬取每个仓库列表的详情r=requests.get("https://www.50yc.com"+url).contentsoup = BeautifulSoup(r,"html.parser")result = soup.find(name='div',attrs={"class":"sm-content"})#返回元素集content = result.find_all("li")#返回元素集with open(os.getcwd()+"\\depot\\"+title+"\\depotdetail.txt","w") as f :for i in content:b = i.find("span").textbr = i.find("div").textf .write(b.replace(" ","").replace("\n","")+br.replace(" ","")+"\n"+"****************************"+"\n")f.close()def getdepot(page):#爬取仓库列表信息depotlisthtml = requests.get("https://www.50yc.com/xan"+page).contentcontent = BeautifulSoup(depotlisthtml,"html.parser")tags = content.find_all(name="div",attrs={"class":"bg-hover"})for i in tags:y = i.find_all(name="img")#返回tag标签for m in y:if m["src"].startswith("http"):imgurl = m["src"]print(imgurl)title = i.strong.textdepotdetailurl = i.a['href']# print(depotdetailurl)os.mkdir(os.getcwd()+'\\depot\\'+title+'\\')with open(os.getcwd()+'\\depot\\'+title+'\\'+"depot.jpg","wb") as d :d.write(requests.get(imgurl).content)with open(os.getcwd()+'\\depot\\'+title+'\\'+"depot.txt","w") as m:m.write(i.text.replace(" ",""))m.close()getdepotdetailcontent(title,depotdetailurl)for i in range(1,26):#爬取每页的仓库列表与仓库详情getdepot("/page"+str(i))print("/page"+str(i))
爬取内容为:
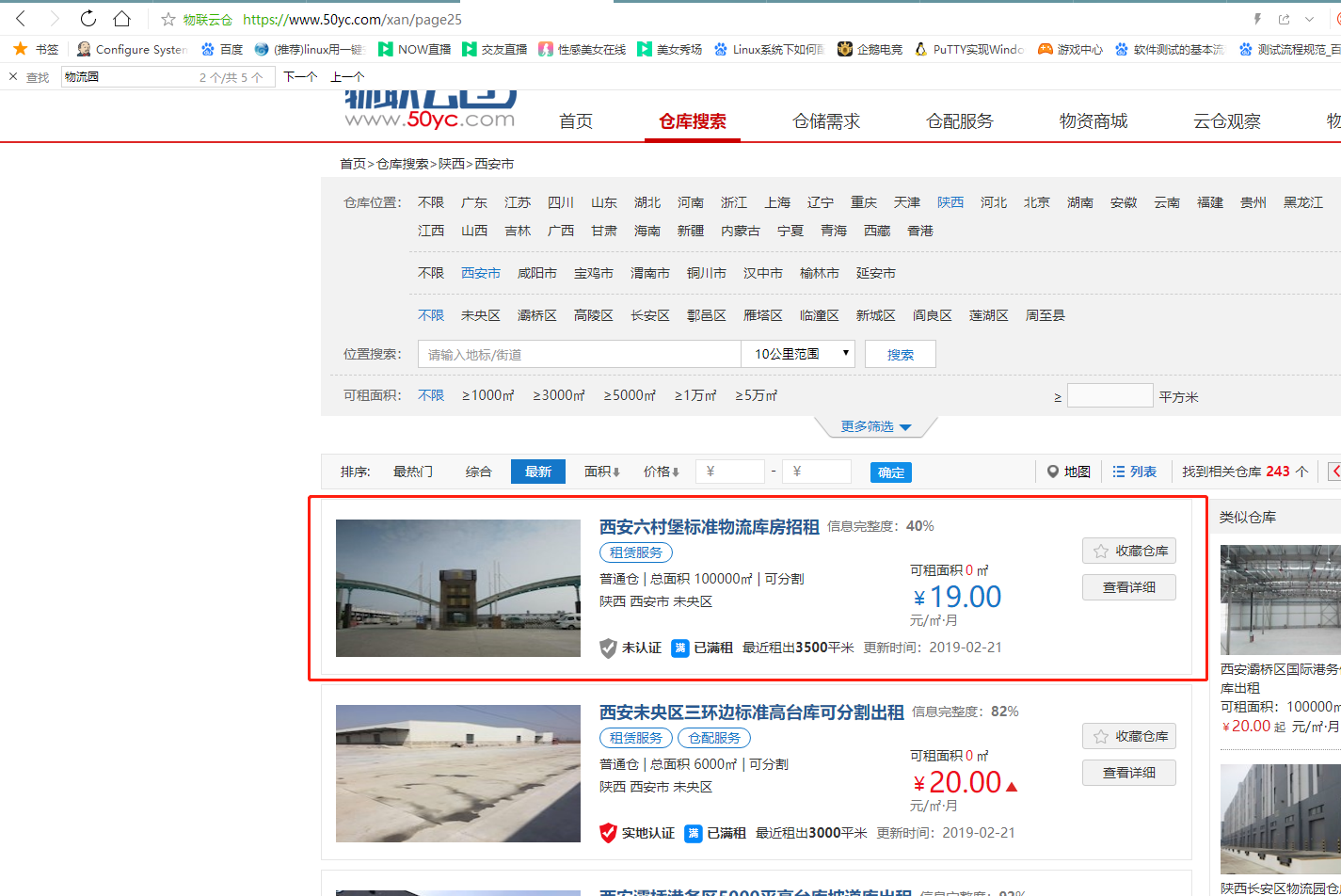
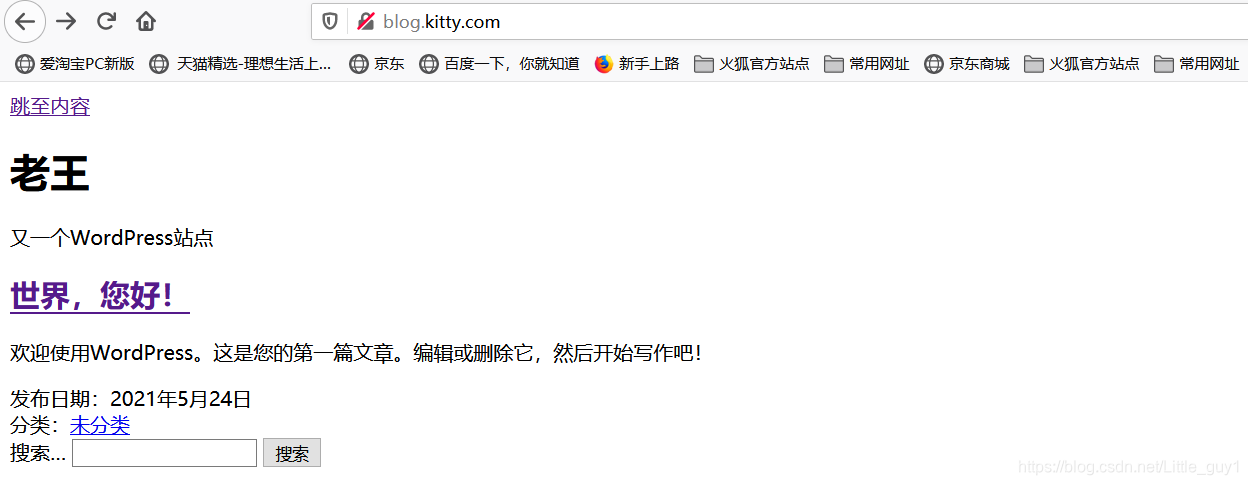
爬取结果如下: