本文讲解的第一个机器学习算法是k-近邻算法(kNN),它的工作原理是:存在一个样本数
据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据
与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的
特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们
只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。
最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
导入模块
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
import time
import numpy as np
import operator
创建数据集
group- 数据集
labels-分类标签
def createDataSet():# 四组二维特征group = np.array([[1,101],[5,89],[108,5],[115,8]])# 四组特征的标签labels = ['爱情片','爱情片','动作片','动作片']return group, labels
KNN算法(分类器)
对未知类别属性的数据集中的每个点依次执行以下操作:
(1) 计算已知类别数据集中的点与当前点之间的距离;
(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的k个点;
(4) 确定前k个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类。
def classify0(inX, dataSet, labels, k):dataSetSize = dataSet.shape[0]diffMat = np.tile(inX, (dataSetSize, 1)) - dataSetsqDiffMat = diffMat**2sqDistances = sqDiffMat.sum(axis=1)distances = sqDistances**0.5sortedDistIndicies = distances.argsort()classCount = {}for i in range(k):voteIlabel = labels[sortedDistIndicies[i]]classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1), reverse = True)return sortedClassCount[0][0]
打开解析文件,对数据进行分类
1代表不喜欢,2代表魅力一般,3代表极具魅力
def file2matrix(filename):fr = open(filename)arrayOlines = fr.readlines()numberOfLines = len(arrayOlines)returnMat = np.zeros((numberOfLines, 3))classLabelVector = []index = 0for line in arrayOlines:line = line.strip()listFromLine = line.split('\t')returnMat[index,:] = listFromLine[0:3]if listFromLine[-1] == 'didntLike':classLabelVector.append(1)elif listFromLine[-1] == 'smallDoses':classLabelVector.append(2)elif listFromLine[-1] == 'largeDoses':classLabelVector.append(3)index += 1return returnMat, classLabelVector
可视化数据
def showdatas(datingDataMat, datingLabels):font = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=14)fig, axs = plt.subplots(nrows=2, ncols=2, sharex=False, sharey=False, figsize=(13, 8))LabelsColors = []for i in datingLabels:# didntLikeif i == 1:LabelsColors.append('black')# smallDosesif i == 2:LabelsColors.append('orange')# largeDosesif i == 3:LabelsColors.append('red')axs[0][0].scatter(x=datingDataMat[:,0], y=datingDataMat[:,1], color=LabelsColors, s=15, alpha=.5)axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font)axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占比', FontProperties=font)plt.setp(axs0_title_text, size=9, weight='bold', color='red')plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')axs[0][1].scatter(x=datingDataMat[:,0], y=datingDataMat[:,2], color=LabelsColors, s=15, alpha=.5)axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰淇淋公升数', FontProperties=font)axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰淇淋公升数', FontProperties=font)plt.setp(axs1_title_text, size=9, weight='bold', color='red')plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')axs[1][0].scatter(x=datingDataMat[:,1], y=datingDataMat[:,2], color=LabelsColors, s=15, alpha=.5)axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰淇淋公升数', FontProperties=font)axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比', FontProperties=font)axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰淇淋公升数', FontProperties=font)plt.setp(axs2_title_text, size=9, weight='bold', color='red')plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')didntLike = mlines.Line2D([], [], color='black', marker='.', markersize=6, label='didntLike')smallDoses = mlines.Line2D([], [], color='orange', marker='.', markersize=6, label='smallDoses')largeDoses = mlines.Line2D([], [], color='red', marker='.', markersize=6, label='largeDoses')axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])plt.show()
对数据进行归一化
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
def autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormDataSet = np.zeros(np.shape(dataSet))m = dataSet.shape[0]normDataSet = dataSet - np.tile(minVals, (m, 1))normDataSet = normDataSet / np.tile(ranges, (m, 1))return normDataSet, ranges, minVals
分类器测试函数
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
def datingClassTest():filename = "datingTestSet.txt"datingDataMat, datingLabels = file2matrix(filename)hoRatio = 0.10normMat, ranges, minVals = autoNorm(datingDataMat)m = normMat.shape[0]numTestVecs = int(m * hoRatio)errorCount = 0.0for i in range(numTestVecs):classifierResult = classify0(normMat[i,:], normMat[numTestVecs:m,:],\datingLabels[numTestVecs:m], 4)print("分类结果:%d\t真实类别:%d" % (classifierResult, datingLabels[i]))if classifierResult != datingLabels[i]:errorCount += 1.0print("错误率:%f%%" % (errorCount/float(numTestVecs)*100))
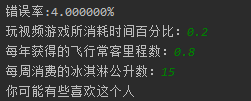
通过输入一个人的三围特征,进行分类输出
def classifyPerson():resultList = ['讨厌', '有些喜欢', '非常喜欢']percentTats = float(input("玩视频游戏所消耗时间百分比:"))ffMiles = float(input("每年获得的飞行常客里程数:"))iceCream = float(input("每周消费的冰淇淋公升数:"))filename = "datingTestSet.txt"datingDataMat, datingLabels = file2matrix(filename)normMat, ranges, minVals = autoNorm(datingDataMat)inArr = np.array([percentTats, ffMiles, iceCream])norminArr = (inArr - minVals) / rangesclassifierResult = classify0(norminArr, normMat, datingLabels, 4)print("你可能%s这个人" % (resultList[classifierResult - 1]))