最近在做一个小项目,因为要用的数据爬取,所以研究了好多天,分享一下自己的方法
目录结构:
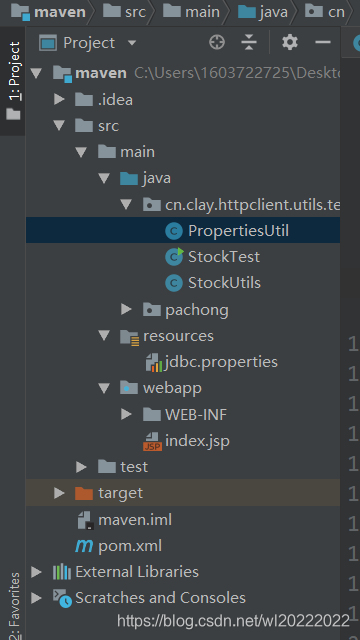
自己创建maven工程,导入相关依赖:pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>maven</groupId><artifactId>maven</artifactId><version>1.0-SNAPSHOT</version><packaging>war</packaging><name>maven Maven Webapp</name><!-- FIXME change it to the project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.7</maven.compiler.source><maven.compiler.target>1.7</maven.compiler.target></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient --><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.3</version></dependency><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.18</version></dependency><!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.8.3</version></dependency></dependencies><build><finalName>maven</finalName><pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) --><plugins><plugin><artifactId>maven-clean-plugin</artifactId><version>3.0.0</version></plugin><!-- see http://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_war_packaging --><plugin><artifactId>maven-resources-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.7.0</version></plugin><plugin><artifactId>maven-surefire-plugin</artifactId><version>2.20.1</version></plugin><plugin><artifactId>maven-war-plugin</artifactId><version>3.2.0</version></plugin><plugin><artifactId>maven-install-plugin</artifactId><version>2.5.2</version></plugin><plugin><artifactId>maven-deploy-plugin</artifactId><version>2.8.2</version></plugin></plugins></pluginManagement></build></project>
StockTest类:
import java.io.IOException;
import java.sql.*;
import org.apache.http.ParseException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/*** @author * @date 2018/12/6 */
public class StockTest {public static void main(String[] args) throws ParseException, IOException {String content = StockUtils.getHtmlByUrl("https:***需要爬取的网页****", "utf-8");parserHtml(content);}public static void parserHtml(String content) throws ParseException, IOException {Document doc = Jsoup.parse(content);//Elements links = doc.getElementsByClass("winstyle214").select("tr");Elements links = doc.getElementsByClass("winstyle614").select("tr");//line67214_0for (Element e : links) {String title = e.select("a").text().toString();System.out.println("新闻标题:" + title);//获取页面链接Elements linkHref = e.select("a");String url = linkHref.attr("href");System.out.println("新闻链接:" + url);//截取时间字符串Elements timeStr = e.select("span[class=timestyle67214]");String time = timeStr.text();System.out.println("发布时间:" + time);insert(title, url, time);}}private static void insert(String title, String urll, String date1) {Connection con = null;PreparedStatement pstm = null;PropertiesUtil.loadFile("jdbc.properties");String driver = PropertiesUtil.getPropertyValue("driver");String url = PropertiesUtil.getPropertyValue("url");String username = PropertiesUtil.getPropertyValue("username");String password = PropertiesUtil.getPropertyValue("password");try {Class.forName(driver);con = DriverManager.getConnection(url,username,password);String sql = "insert into news(title,urll,date1) value(?,?,?)";pstm = con.prepareStatement(sql);pstm.setString(1, title);pstm.setString(2, urll);pstm.setString(3, date1);} catch (SQLException e) {e.printStackTrace();} catch (ClassNotFoundException e) {e.printStackTrace();} finally {if (con != null) {try {con.close();} catch (SQLException e) {e.printStackTrace();}if (pstm != null) {try {pstm.close();} catch (SQLException e) {e.printStackTrace();}}}}}
}
StokUtils类:
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;import java.io.IOException;
/*** 传递网页链接* 返回网页源码* @author**/
public class StockUtils {//第一次获取网页源码public static String getHtmlByUrl(final String url, final String charset) throws IOException {/*RequestConfig defaultRequestConfig = RequestConfig.custom().setConnectTimeout(5000).setConnectionRequestTimeout(5000).build();*///CloseableHttpClient httpclient = HttpClients.custom().setMaxConnTotal(800).setMaxConnPerRoute(800).setDefaultRequestConfig(defaultRequestConfig).build();CloseableHttpClient httpclient = HttpClients.createDefault();try {HttpGet httpget = new HttpGet(url);//System.out.println("executing request " + httpget.getURI());ResponseHandler<String> responseHandler = new ResponseHandler<String>() {public String handleResponse(final HttpResponse response) throws ClientProtocolException, IOException {int status = response.getStatusLine().getStatusCode();//System.out.println("========responseStatusCode:"+status + " "+url);if (status == 200) {HttpEntity entity = response.getEntity();if (entity == null) {System.out.println("========entity is null:" + status + " " + url);return null;} else {String content = EntityUtils.toString(entity);if (charset != null) {content = new String(content.getBytes("ISO-8859-1"), charset);}return content;}} else {throw new ClientProtocolException("Unexpected response status: " + status);}}};String responseBody = httpclient.execute(httpget, responseHandler);return responseBody;} catch (ClientProtocolException e) {System.out.println("========ClientProtocolException====" + e.getMessage() + " " + url);//e.printStackTrace();return getHtmlByUrl(url, charset);} catch (IOException e) {System.out.println("========IOException====" + e.getMessage() + " " + url);//e.printStackTrace();return getHtmlByUrl(url, charset);} finally {httpclient.close();}}
}
配置文件 jdbc.properties(maven 工程和JAVA工程连接数据库还是有所不同的,具体自己百度):
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/zgschool?useUnicode=true&characterEncoding=utf-8&useSSL=false
username=root
password=root配置该文件后,properties类会自动生成。。。。
至此,大功告成。。