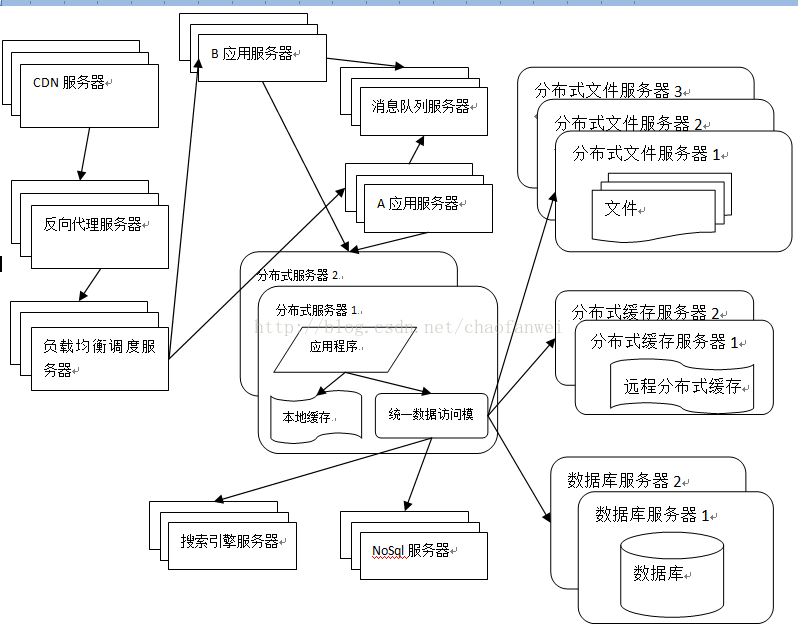
在平时的运维工作中,我们运维人员需要清楚自己网站每天的总访问量、总带宽、ip统计和url统计等。
虽然网站已经在服务商那里做了CDN加速,所以网站流量压力都在前方CDN层了
像每日PV,带宽,ip统计等数据也都可以在他们后台里查看到的。
======================================================================
通过下面的方法,可以快速根据子网掩码算出它的掩码位:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | 子网掩码 掩码位
255.255.255.0 24位 (最后一个数是0,则256-0=256=2^8,一共32位,则该掩码位是32-8=24)
255.255.255.248 29位 (256-248=8=2^3,则该掩码位是32-3=29)
255.255.255.224 27位 (256-224=32=2^5,则该掩码位是32-5=27)
255.255.252.0 22位 (256-0=256=2^8,256-252=4=2^2,则该掩码位是32-8-2=22位)
255.255.224.0 19位 (256-0=256=2^8,256-224=32=2^5,则该掩码位是32-8-5=19位)
也可以根据掩码位快速算出它的子网掩码
掩码位 子网掩码
28位 255.255.255.240 (32-28=4,2^4=16,256-16=240,则该子网掩码为255.255.255.240)
30位 255.255.255.252 (32-30=2,2^2=4,256-4=252,则该子网掩码为255.255.255.252)
21位 255.255.248.0 (32-21=11=3+8,2^3=8,256-8=248,2^8=256,256-256=0,则该子网掩码为255.255.248.0)
18位 255.255.192.0 (32-18=14=6+8,2^6=64,256-64=192,2^8=256,256-256=0,则该子网掩码为255.255.192.0)
11位 255.224.0.0 (32-11=21=5+8+8,2^5=32,256-32=224,2^8=256,256-256=0,2^8=256,256-256=0,则该子网掩码为255.224.0.0)
------------------------------------------------------------------------------------------------------------------------
192.168.10.8/16
192.168.8./16
172.16.50.5/24
172.16.51.7/24
以上两组ip,其中:
第一组是同网段ip,因为子网掩码是16,即255.255.0.0,前两个是网络地址,后两个机器地址,只要前两个数字相同就是同网段ip。
第一组不是同网段ip,因为子网掩码是24,即255.255.255.0,前三个是网络地址,后两个机器地址,只要前三个数字不相同就不是同网段ip。
简单来说:
不同网段的ip相互通信,需要经过三层网络。即三层网络可以跨多个冲突域,可以组大型的网络。
相同网段的ip相互通信,经过大二层网络。即二层网络仅仅是同一个冲突域内,组网能力非常有限,一般只是小局域网
|
---------------------------------------------------------------------------------------------------------------------
在这里,还是分享一个很早前用到过的shell统计脚本,可以结合crontab计划任务,每天给你的邮箱发送一个统计报告~【前提是本机已安装sendmail并启动】
脚本统计了:
1)总访问量
2)总带宽
3)独立访客量
4)访问IP统计
5)访问url统计
6)来源统计
7)404统计
8)搜索引擎访问统计(谷歌,百度)
9)搜索引擎来源统计(谷歌,百度)
[root@115r ~]# cat tongji.sh //脚本如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #!/bin/bash
log_path=/Data/logs/nginx/www.huanqiu.com/access.log
domain="huanqiu.com"
email="wangshibo@huanqiuc.com"
maketime=`date +%Y-%m-%d" "%H":"%M`
logdate=`date -d "yesterday" +%Y-%m-%d`
total_visit=`wc -l ${log_path} | awk '{print $1}'`
total_bandwidth=`awk -v total=0 '{total+=$10}END{print total/1024/1024}' ${log_path}`
total_unique=`awk '{ip[$1]++}END{print asort(ip)}' ${log_path}`
ip_pv=`awk '{ip[$1]++}END{for (k in ip){print ip[k],k}}' ${log_path} | sort -rn | head -20`
url_num=`awk '{url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
referer=`awk -v domain=$domain '$11 !~ /http:\/\/[^/]*'"$domain"'/{url[$11]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
notfound=`awk '$9 == 404 {url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
spider=`awk -F'"' '$6 ~ /Baiduspider/ {spider["baiduspider"]++} $6 ~ /Googlebot/ {spider["googlebot"]++}END{for (k in spider){print k,spider[k]}}' ${log_path}`
search=`awk -F'"' '$4 ~ /http:\/\/www\.baidu\.com/ {search["baidu_search"]++} $4 ~ /http:\/\/www\.google\.com/ {search["google_search"]++}END{for (k in search){print k,search[k]}}' ${log_path}`
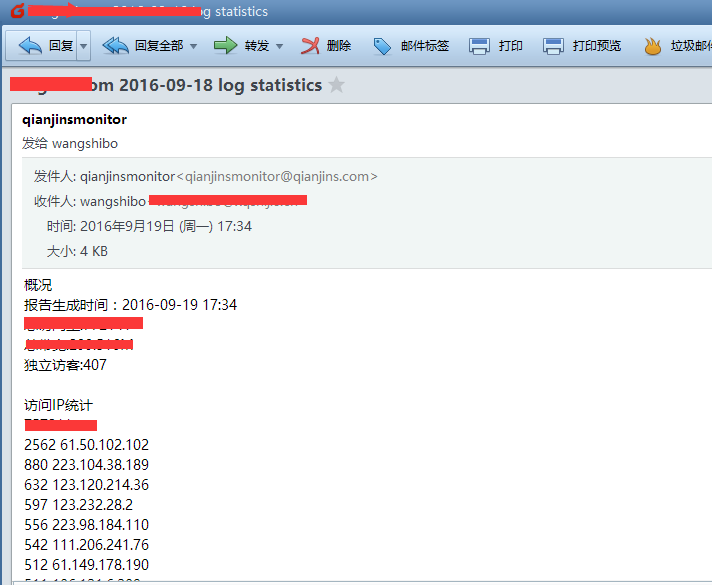
echo -e "概况\n报告生成时间:${maketime}\n总访问量:${total_visit}\n总带宽:${total_bandwidth}M\n独立访客:${total_unique}\n\n访问IP统计\n${ip_pv}\n\n访问url统计\n${url_num}\n\n来源页面统计\n${referer}\n\n404统计\n${notfound}\n\n蜘蛛统计\n${spider}\n\n搜索引擎来源统计\n${search}" | mail -s "$domain $logdate log statistics" ${email}
|
上述脚本可适用于其他网站的统计。只需要修改上面脚本中的三个变量即可:
log_path
domain
email
把此脚本添加到计划任务,就可以每天接收到统计的数据了。
执行上面的脚本,去wangshibo@huanqiu.com邮箱里查看统计报告:
[root@115r ~]# sh tongji.sh
[root@115r ~]#crontab -e
#每天凌晨按时统计一次
59 23 * * * /bin/bash -x /root/tongji.sh >/dev/null 2>&1
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | ------------------------------------------------------------------------------------------------------------------------------
上面是单个url的统计情况,如果时多个网站的访问情况(使用for do done语句做shell脚本),则脚本如下:
[root@web ~]# cat all_wang_access.sh
#!/bin/bash
for log_path in /data/nginx/logs/athena_access.log /data/nginx/logs/ehr_access.log /data/nginx/logs/im_access.log /data/nginx/logs/www_access.log /data/nginx/logs/zrx_access.log
do
domain=`echo $(echo ${log_path}|cut -d"_" -f1|awk -F"/" '{print $5}').wang.com`
email="shibo.wang@wang.com daiying.qi@wang.com nan.li@wang.com"
maketime=`date +%Y-%m-%d" "%H":"%M`
logdate=`date -d "yesterday" +%Y-%m-%d`
total_visit=`wc -l ${log_path} | awk '{print $1}'`
total_bandwidth=`awk -v total=0 '{total+=$10}END{print total/1024/1024}' ${log_path}`
total_unique=`awk '{ip[$1]++}END{print asort(ip)}' ${log_path}`
ip_pv=`awk '{ip[$1]++}END{for (k in ip){print ip[k],k}}' ${log_path} | sort -rn | head -20`
url_num=`awk '{url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
referer=`awk -v domain=$domain '$11 !~ /http:\/\/[^/]*'"$domain"'/{url[$11]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
notfound=`awk '$9 == 404 {url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
spider=`awk -F'"' '$6 ~ /Baiduspider/ {spider["baiduspider"]++} $6 ~ /Googlebot/ {spider["googlebot"]++}END{for (k in spider){print k,spider[k]}}' ${log_path}`
search=`awk -F'"' '$4 ~ /http:\/\/www\.baidu\.com/ {search["baidu_search"]++} $4 ~ /http:\/\/www\.google\.com/ {search["google_search"]++}END{for (k in search){print k,search[k]}}' ${log_path}`
echo -e "-----------------------------------$domain访问概况-----------------------------------\n报告生成时间:${maketime}\n总访问量:${total_visit}\n总带宽:${total_bandwidth}M\n独立访客:${total_unique}\n\n访问IP统计\n${ip_pv}\n\n访问url统计\n${url_num}\n\n来源页面统计\n${referer}\n\n404统计\n${notfound}\n\n蜘蛛统计\n${spider}\n\n搜索引擎来源统计\n${search}" | mail -s "$domain $logdate log statistics" ${email}
done
使用crontab做定时任务
[root@web ~]# crontab -l
#网站访问情况统计
50 23 * * * /bin/bash -x /opt/wang.com_access/all_wang_access.sh > /dev/null 2>&1
|
***************当你发现自己的才华撑不起野心时,就请安静下来学习吧***************