文章目录
- 案例背景
- 1 检验指标的确定
- 2 确定检验统计量
- 3 埋点收集数据
- 4 确定H0,H1
- 5 确定显著性水平
- 6 计算样本量
- 7 利用统计工具实现检验
案例背景
某网站首页双12 活动 banner主色调选择(现提供两个版本的banner),
banner 为网站PC端或App 的顶部或底部横向贯穿整个界面的广告条。
现需要数据分析师通过ABTest实现对A、B两个不同色调的banner进行择优选择
1 检验指标的确定
一类指标:人均停留时长
二类指标:广告点击率=点击用户数/曝光用户数
2 确定检验统计量
一类指标:用人均停留时长之差做统计量,即 μ 𝐴 − μ 𝐵 \mu_𝐴−\mu_𝐵 μA−μB
二类指标:用两组广告点击率之差做统计量,即 𝑃 𝐴 − 𝑃 𝐵 𝑃_𝐴−𝑃_𝐵 PA−PB
3 埋点收集数据
| 事件名 | 用户浏览点击banner页 |
|---|---|
| user_id | 用户ID,唯一识别码 |
| timestemp | 用户浏览banner页的时间 |
| group | 用户所属的组别,控制组和实验组 |
| landing_page | 用户所浏览的banner页的所属类别 |
| convert | 用户是否点击,0:否,1:是 |
4 确定H0,H1
一类指标:实验组人均停留时长不显著小于对照组
H 1 : μ A − μ B < α 1 μ B = μ A − α 1 x A ˉ − x B ˉ n A = k n B a n d n B = ( 1 + 1 k ) ( σ z 1 − α + z 1 − β μ A − μ B ) 2 σ = σ A 2 n A + σ B 2 n B H1:\mu_A-\mu_B<\alpha_1 \\ \mu_B=\mu_A-\alpha_1 \\ \bar{x_A}-\bar{x_B} \\ n_A=kn_B and n_B=(1+\frac{1}{k})(\sigma\frac{z_{1-\alpha}+z_{1-\beta}}{\mu_A-\mu_B})^2 \\ \sigma=\sqrt{\frac{\sigma_A^2}{n_A}+\frac{\sigma_B^2}{n_B}} H1:μA−μB<α1μB=μA−α1xAˉ−xBˉnA=knBandnB=(1+k1)(σμA−μBz1−α+z1−β)2σ=nAσA2+nBσB2
H0:control_time-treatment_time>=2*Std(control_time)
H1:control_time-treatment_time<2*Std(control_time)
二类指标:实验组广告点击率不显著大于对照组
π A − π B > α 1 \pi_A-\pi_B>\alpha_1 πA−πB>α1
H0:treatment_p-control_p<=0
H1:treatment_p-control_p>0
其中,A组为实验组treatment,B组为对照组control
5 确定显著性水平
一类错误默认:𝛼=0.05
二类错误默认:𝛽=0.02
6 计算样本量
(缺少一类指标的数据,只计算二类指标)
二类指标的H0和H1可以得知:
应选择估计比例之差时的单侧样本量
n A = k n B a n d n B = ( p A ( 1 − p A ) k + p B ( 1 − p B ) ) ( z 1 − α + z 1 − β p A − p B ) 2 n_A=kn_B and n_B=(\frac{p_A(1-p_A)}{k}+p_B(1-p_B))(\frac{z_{1-\alpha}+z_{1-\beta}}{p_A-p_B})^2 nA=knBandnB=(kpA(1−pA)+pB(1−pB))(pA−pBz1−α+z1−β)2
代码如下:
其中,treatment_p为 P A P_A PA,control_p为 P B P_B PB
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import pymysql
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.family']='SimHei'
plt.rcParams['axes.unicode_minus']= False
数据导入并清洗
data = pd.read_csv(r"D:\WORK\STUDY\数据分析\作业\阶段七\模块二作业\ab_data.csv")
data["date"] = data.timestamp.str[:10]
data.head()
# 数据是否存在重复值
data.duplicated().sum()
# 查看page_view by day分布
plt.figure(figsize=(12,5))
plt.plot(data.date.value_counts().sort_index())
数据无缺失值、无重复值
alpha = 0.05
beta = 0.2
k =1
#求P_A
treatment_p = data.converted[(data.group=="control")&(data.landing_page=="old_page")].mean()
treatment_p
#求P_A*(1-P_A)
treatment_p_1_pa = treatment_p * (1 - treatment_p)
treatment_p_1_pa
# 均值之差在大样本下其分布近似正态分布
#求Z_(1-α)
z_alpha = stats.norm.isf(alpha,loc=0,scale=1)
z_alpha
#求Z_(1-β)
z_beta = stats.norm.isf(beta,loc=0,scale=1)
z_beta
#求P_B
#H1为 Pa-Pb>0,为计算样本量,这里需要指定一个非0的值, 此值的绝对值越小样本量越大
#我们先指定一个偏小的值 0.01
control_p = treatment_p + 0.01
p0 = treatment_p - control_p
print(control_p,p0)
#求P_B*(1-P_B)
control_p_1_pb = control_p * (1 - control_p)
control_p_1_pb
n = (treatment_p_1_pa + control_p_1_pb) * ((z_alpha + z_beta)/(treatment_p - control_p)) ** 2
n
# 查看我们的样本量是否满足最低样本量
dd = data.groupby(["group","landing_page","date"],as_index=False)["user_id"].count()
dd[((dd.group == "control") & (dd.landing_page=="old_page"))|((dd.group=="treatment")&(dd.landing_page=="new_page"))]
7 利用统计工具实现检验
1.读取数据
2.计算统计量
3.计算统计量的显性P值
4.用统计量的显著性P值与显著性α比较做决策
df = data[data.date=="2017-01-03"].groupby(["group","landing_page"],as_index=False)["converted"].mean()
df
#求控制组的旧页面和对照组的新页面比例之差
statistic_t = df.converted[2] - df.converted[1]
求
σ = P A ( 1 − P A ) n A + P B ( 1 − P B ) n B \sigma=\sqrt{\frac{P_A(1-P_A)}{n_A}+\frac{P_B(1-P_B)}{n_B}} σ=nAPA(1−PA)+nBPB(1−PB)
n_B =data[data.date=='2017-01-03'].converted[(data.group=='control')&(data.landing_page=='old_page')].size
n_A =data[data.date=='2017-01-03'].converted[(data.group=='treatment')&(data.landing_page=='new_page')].size
print(n_A,n_B)
sigma = np.sqrt(df.converted[2]*(1-df.converted[2])/n_A + df.converted[1]*(1-df.converted[1])/n_B)
sigma
statistic_p = 1-stats.norm.cdf(statistic_t,0,sigma)
statistic_p
if statistic_p > alpha:print("显著性P>α,实验组点击率<对照组")
else:print("显著性P<α,实验组点击率>对照组")
#封装函数def abtest(df: pd.DataFrame, alpha=0.05, group_col: str = None, value_col: str =None):''':param df:被分析DataFrame对象:param alpha:显著性:param group_col:组列的名字,默认为df的第一列:param value_col:值列的名字,默认为df的第二列:return:tongjiliang p_value p_type''' # 列名if not group_col:group_col = df.columns[0]if not value_col:value_col = df.columns[1]temp = df.groupby(group_col,as_index=False)[value_col].mean()temp_n = df.groupby(group_col,as_index=False)[value_col].count()statistic_t =temp.iloc[0,1] - temp.iloc[1,1] #先求出各组均值在求出统计量差值sigma =np.sqrt(temp.iloc[0,1] *(1-temp.iloc[0,1])/temp_n.iloc[0,1] + temp.iloc[1,1] *(1-temp.iloc[1,1])/temp_n.iloc[1,1]) #标准差statistic_l_p = stats.norm.cdf(statistic_t,0,sigma)statistic_r_p = 1-stats.norm.cdf(statistic_t,0,sigma)statistic_p = statistic_l_p *2;if statistic_p >alpha:statistic_p = statistic_l_p*2temp_l = [[temp.iloc[0,0],temp.iloc[1,0],statistic_t,"左侧",statistic_l_p,np.where(statistic_l_p<alpha,"显著","不显著")],[temp.iloc[0,0],temp.iloc[1,0],statistic_t,"右侧",statistic_r_p,np.where(statistic_r_p<alpha,"显著","不显著")],[temp.iloc[0,0],temp.iloc[1,0],statistic_t,"双侧",statistic_p,np.where(statistic_p<alpha,"显著","不显著")]]temp = pd.DataFrame(temp_l,columns =["p","p0","统计量","检测","p_value","结果"])return temp
temp = data[data.date=='2017-01-04'].loc[((data.group=="control") & (data.landing_page=="old_page")) | ((data.group=="treatment") & (data.landing_page=="new_page")),["group","converted"]]
temp.head()
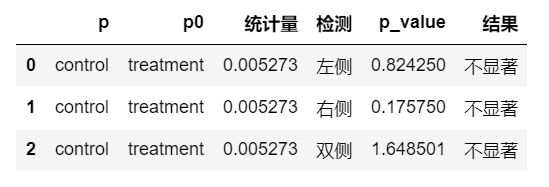
abtest(temp)
输出结果: