一直对编程感兴趣,但始终敬而远之,仅了解过一些皮毛。去年年底戒掉游戏,就突发奇想,认真学一门语言。问了一下度娘,说非科班出生比较适合学Python。因为之前对Python一点不了解,在网上搜了一些资料看,觉得挺有意思,就开始学。先是在手机上看网上的教程,主要看了菜鸟教程和廖雪峰老师关于Python的教程,学到一些基础,越发感兴趣。尤其是在工作中,偶然开窍解决一些小问题,觉得很有成就感,就想要深入系统的学一学。下定决心后,到书店买了几本书,因为刚开始不懂,就胡乱选了一些,有python基础的,数据分析的,教写网站的。混乱看了后,觉得不得法,加之有些浮躁,成效不太明显。总结了一下,觉得应该选一个研究方向,有重点的推进,而不应该眉毛胡子一把抓,结果什么都学不到。又是一阵问度娘,决定从数据分析方面入手,感觉大数据近年炒得有点火,而且感觉从数据分析入手,以后可以自己研究一些东西(比如出个报告什么的,有点想得美☺),有点像自由职业,应该是我将来想追求的。选定数据分析的方向后,就觉得应该从数据挖掘、数据采集等方面入手,因此首先想到的就是先学爬虫技术。不得不说,随着学习的逐渐深入,越发感觉自己欠缺的东西太多。比如爬虫,因为需要,就大致了解了http协议、html、正则表达式、cookie、网络抓包等好的东西,不得不服老啊,脑子不够用,学起来很慢。清明小长假,朋友圈到处是晒吃喝玩乐的照片,我除了陪孩子出去骑了半天的车,一直窝在家里捣鼓代码,攻克网站登录的难关。假期即将结束的时候基本摸清了头绪,算是假日成果吧。下面谈谈我的艰苦攻坚历程:
一、抓取网页的基本方法
要抓网页,基础的要用到urllib.request这个库,就这个库刚开始还是绕了一些弯路的。网上很多代码都是基于python2的,看了一些教程,也一直认为在python3中也是用urllib 和urllib2,遇到问题后才发现python2中的这两个库在pyhon3中被完全集成到urlllib.request这个库中。
抓网页是这样的,先拿度娘练练手:
import urllib.request
url = 'http://www.baidu.com'web_response = urllib.request.urllopen(url)
web_content = web_response.read()
print(web_content.decode('utf8'))也可以把抓取下来的网页内容写入文件:
with open('baidu.html', 'wb') as f:f.write(web_content)以上代码更规范(或者说推荐)的应该是这样写的:
import urllib.request
url = 'http://www.baidu.com'web_request = urllib.request.Request(url)
web_response = urllib.request.urllopen(web_request)
web_content = web_response.read()
print(web_content.decode('utf8'))刚开始我也觉得这样写多余,何必先定义request呢?其实后面才知道,一方面,这样更能反应浏览器与服务器请求与应答的过程,使用urllib.request.Request()定义请求,在python标准库中,它的完整定义是这样的:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)其中的名称参数data和headers分别用与在请求中发送post数据和request头数据,后面模拟浏览器登录会用到。
而urllib.request.urlopen的完整定义是这样的:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)官方文档说:url可以是网址(string),也可以是一个Request对象,就是用urllib.request.Request对象
在成功抓取百度首页后,我曾经惊喜的认为抓取网页如此简单,无非是用正则表达式找出说抓取页面中需要的内容(数据),该下载的下载,该解析的解析,该继续抓的继续抓(指从页面中解析出的网址)无非是多一些循环和递归。很快,我就意识到我错了,这还差得远啊。很多网站要通过请求数据判断客服端究竟是不是web浏览器,如果不是就拒绝响应。这时,我们要通过定义并发送headers数据,把我们的程序请求伪装成浏览器(假装是浏览器在向服务器请求),最简单的定义是这样的一个字典(只有User-Agent一项):
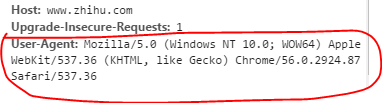
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
}这在chrome的开发者工具中可以看见,如下图:
然后,
web_request = urllib.request.Request(url, headers = headers)这样服务器就会以为我们的请求是从浏览器操作的,就会给出响应。当然,有的header会需要很多项,这我还没有深入研究。但我认为,从chrome开发者工具中,把request header 的所有数据项复制过来应该不会差太远。
二、登陆网页
抓完百度首页,我就想抓知乎试试,结果碰壁,知乎需要登陆,如果不登陆,抓下来的页面什么都没有。我在网上找资料,其中一篇正好以登陆知乎为例的标题是:零基础自学用Python 3开发网络爬虫(四): 登录,原址为:http://python.jobbole.com/77878/,在此贴出程序代码:
import gzip
import re
import http.cookiejar
import urllib.request
import urllib.parsedef ungzip(data):try: # 尝试解压print('正在解压.....')data = gzip.decompress(data)print('解压完毕!')except:print('未经压缩, 无需解压')return datadef getXSRF(data):cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)strlist = cer.findall(data)return strlist[0]def getOpener(head):# deal with the Cookiescj = http.cookiejar.CookieJar()pro = urllib.request.HTTPCookieProcessor(cj)opener = urllib.request.build_opener(pro)header = []for key, value in head.items():elem = (key, value)header.append(elem)opener.addheaders = headerreturn openerheader = {'Connection': 'Keep-Alive','Accept': 'text/html, application/xhtml+xml, */*','Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3','User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko','Accept-Encoding': 'gzip, deflate','Host': 'www.zhihu.com','DNT': '1'
}url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解压
_xsrf = getXSRF(data.decode())url += 'login'
id = '这里填你的知乎帐号'
password = '这里填你的知乎密码'
postDict = {'_xsrf':_xsrf,'email': id,'password': password,'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)print(data.decode())讲的很好,我也照做了,由于现在知乎需要验证码,并不能成功。但我从该教程中学会了定义和发生post数据,即:
headers = {}
post_dict = {'_xsrf':_xsrf,'email': id,'password': password,'rememberme': 'y'
}
post_data = urllib.parse.urlencode(postDict).encode()
web_request = urllib.request.Request(url, post_data, headers)同时,我也了解到登陆网站不仅需要发送用户名、密码,还有诸如“_xsrf”这样被原文作者称为“沙漠之舟”的数据,而且这个数据在知乎的名称是“_xsrf",在其他网站这几乎不可能一样,而且服务器发送的方式也不知道,知乎是通过首页把 _xsrf 生成发送给我们, 然后我们再把这个 _xsrf 发送给 /login 这个 url,我们可以从首页中提取它的值,但其它网站呢,应该是各不相同的。事实是,我试着用作者推荐的Fiddler 软件观察了几个网站,确实不一样,而且以我老年人的脑袋,确实想不出来要怎么获取这些值。如csdn,好像需要在request中传送一个名叫”lt“的值,但我一直没有找到。我用Fiddler观察了接近一天,全无所获,一个网站也没有成功登陆,几乎到了崩溃的边缘。
在用chrome开发者工具观察request header数据的时候,我偶然发现其中有一项叫Cookie的值,于是我灵光一现,如果把这个cookie值写在header里面会怎么样呢?于是写出了一下代码:
import urllib.request
import gzip
import re
url = 'http://www.zhihu.com'
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Encoding':'gzip, deflate, sdch, br','Accept-Language':'zh-CN,zh;q=0.8','Connection':'keep-alive','Cookie': '''此处省略一千字(实际的cookie值)''','Host':'www.zhihu.com','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
webrequest = urllib.request.Request(url, headers=headers)
webcontent_open = urllib.request.urlopen(webrequest).read()
webcontent = gzip.decompress(webcontent_open)
href_and_title_re = re.compile('<h2.*?href="(http.*?\d+)".*?>(.*?)</a></h2>')for href,title in href_and_title_re.findall(webcontent.decode('utf8')):print(title)print(href)居然成功了!有图为证:
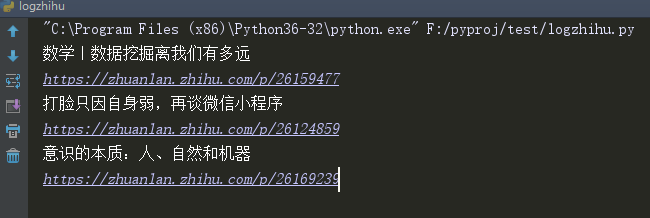
我欣喜若狂,何不直接读取chrome目录下的Cookies写入header中,不久可以登陆了么?理想是丰满的,现实往往确实骨感的,在这个思路下我有经过了很多次折腾,才明白很多道理。老年人的脑袋是不够用啊!
三、通过读取Cookie
(未完待续,今天骑了半天的车太累了,年纪大了,扛不住,洗洗睡☺)