1、任选一小说网站,爬取任意一部小说,以记事本的形式保存。
第一种情况(网址可能已失效):
import requests
from lxml import etree
def get_url():url = 'http://www.yuetutu.com/cbook_24378/'r = requests.get(url)tree = etree.HTML(r.text)return treedef get_book_url(tree):book_list= []dd_list = tree.xpath('//*[@id="list"]/dl/dd')i = 1for dd in dd_list:if i >= 9:url_book = dd.xpath('a')[0].attrib['href']title_book = dd.xpath('a')[0].textbook_list.append((title_book, url_book))i += 1return book_listdef get_content(book):domain = 'http://www.yuetutu.com'for i in book:url = domain + i[1]r = requests.get(url)r.encoding = 'utf8'tree = etree.HTML(r.text)title = tree.xpath('//*[@id="wrapper"]/div[3]/div/div[2]/h1')[0].texttext = tree.xpath('//*[@id="content"]/text()')path = r'C:\Users\dell\Desktop\小说\ 'with open(path + title + '.txt', 'w', encoding='utf8') as f:for j in text:f.write(j)print('******{} 下载完成! ******'.format(title))if __name__ == '__main__':a = get_url()b = get_book_url(a)get_content(b)


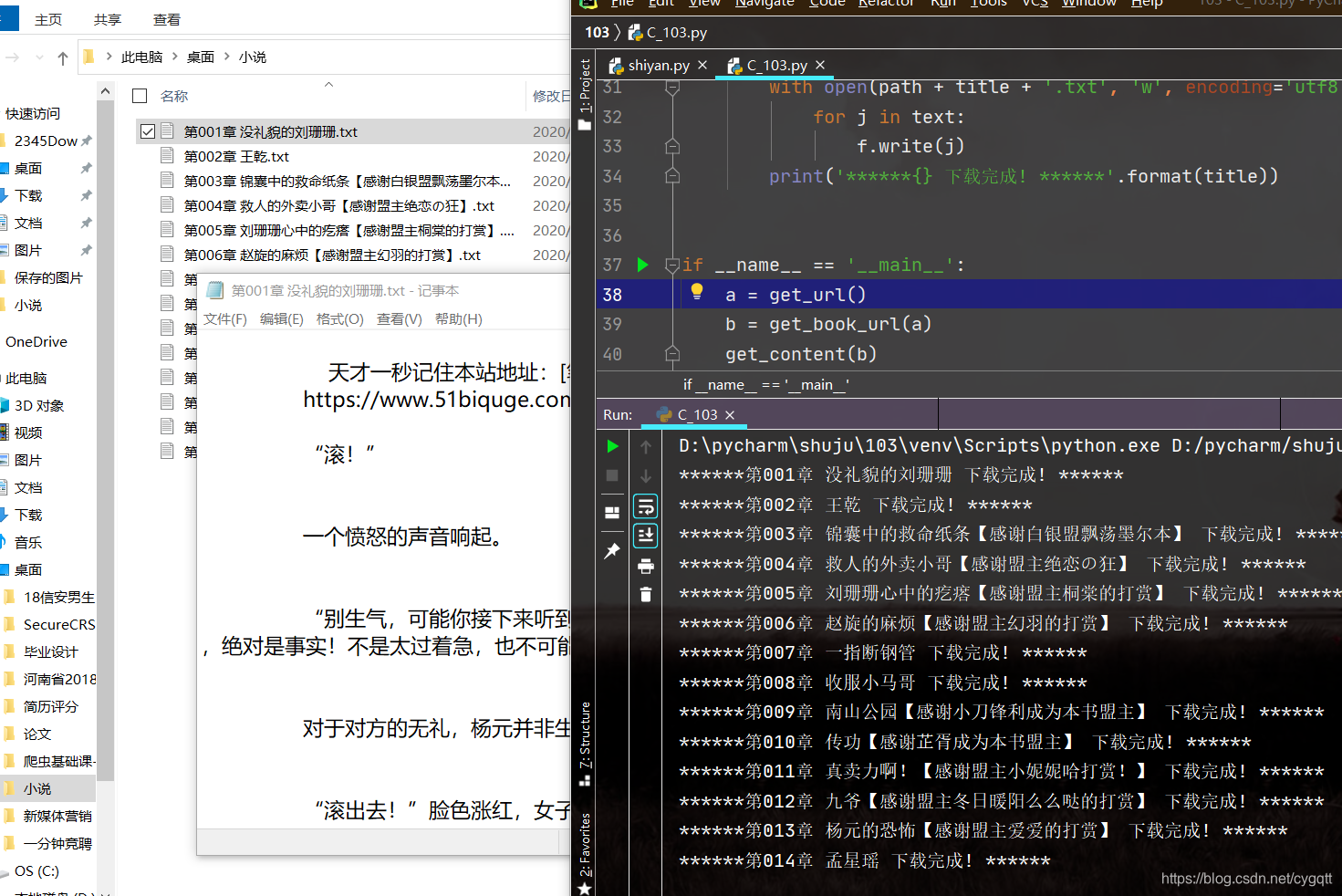
第二种情况:
import requests
from lxml import etree
def get_url():url = 'https://www.51biquge.com/book_12066/'r = requests.get(url)tree = etree.HTML(r.text)return treedef get_book_url(tree):book_list = []dd_list = tree.xpath('//*[@id="list"]/dl/dd')i = 1for dd in dd_list:if i >= 13:url_book = dd.xpath('a')[0].attrib['href']title_book = dd.xpath('a')[0].text.strip()book_list.append((title_book, url_book))i += 1return book_listdef get_content(book):domain = 'https://www.51biquge.com'for i in book:url = domain + i[1]r = requests.get(url)r.encoding = 'utf8'tree = etree.HTML(r.text)title = tree.xpath('//*[@id="main"]/div/div/div[2]/h1')[0].texttext = tree.xpath('//*[@id="content"]//p/text()')path = r'C:\Users\dell\Desktop\小说\ 'with open(path + title + '.txt', 'w', encoding='utf8') as f:for j in text:f.write(j)print('******{} 下载完成! ******'.format(title))if __name__ == '__main__':a = get_url()b = get_book_url(a)get_content(b)