前提:
- 本文是基于memcached1.4版本的,之前的版本与该版本在一些地方是不一样的(eg.《memcached全面剖析》的memcached1.2的内存管理方式就与1.4不同)
- 在看本文之前,最好先看一下memcached在实际开发中怎么进行操作的,链接《第八章 企业项目开发--分布式缓存memcached》
1、memcached特征
- 协议简单(文本协议、二进制协议)
- 基于libevent的事件处理,libevent封装了Linux的epoll模型的时间处理功能。
- slab存储模型
- 集群中服务器间互不通信(在大集群的情况下,其性能远超其他同步更新缓存的缓存器,当然小集群下,memcached的性能也十分优秀)
2、memcached访问模型

说明:
Xmemcached的具体使用代码查看"Java企业项目开发实践"系列博客的《第八章 企业项目开发--分布式缓存memcached》,下面的解释会依据该代码进行。
在上图中,memcached客户端假设使用XMemcached
- 服务器列表:在根pom.xml文件中进行了配置
- 路由算法有两种:(可以在程序中指定)
- 一致性hash算法(推荐)
- 简单求余法
- 通信模块:
- 通信协议:TCP协议
- 序列化协议:二进制协议(推荐)、文本协议
- Memcached API(缓存的增删改查):在程序中编写
整个流程:
应用程序(AdminService)调用Memcached API(假设为add操作),向memcached服务器添加缓存,这时候,程序会首先根据配置的路由算法(假设是一致性hash算法)在服务器列表中选出一台服务器(假设是node1),之后该API通过序列化协议序列化对象(当然,这个是可无的,eg.value是一个String),并通过TCP协议将将要存储的key-value对存入相应的服务器。在get时,只要采用的是与add时相同的hash算法,就会选中add时的那一台服务器。
看完这一段,流程明白了。但是有几点疑问:
- 两种路由算法是怎样实现的?为什么使用一致性hash算法
- 缓存到达服务器的时候究竟怎么存储?(slab内存模型)
- 当缓存超过一定的容量后,缓存的自动删除是采用什么策略,怎样删除的?(LRU)
- 两种序列化协议有什么优缺点?
3、hash算法
3.1、简单求余法
原理步骤:求得key的整数hash值(对于Java对象而言,直接使用其hashCode()方法就好),再除以服务器台数,获取余数,根据该余数选择服务器。
注意:如果选择的服务器无法连接时,会进行rehash,即:将连接次数添加到键中,重新计算hash值后,再重新连接。当然可以禁止rehash。
优点:
- 简单
- hash分散性好(因为hashCode()的值具有随机性)
缺点:
- 添加或删除服务器的时候,缓存的获取就会出问题了(因为服务器台数变了,求余的时候分母变了,余数也就可能变了),假设在99台memcached服务器中又新添加而一台,则缓存的不命中率是99%,即n/(n+1),n表示原有的服务器。
注意:
- 在XMemcached中仍保留了该算法
- 适用于不需要考虑集群伸缩性的时候(即机器总数不变)
3.2、一致性hash算法
对于绝大部分系统,集群的伸缩性是五个非功能需求中比较重要的一个,也就是说必须克服"简单求余法"的缺点。
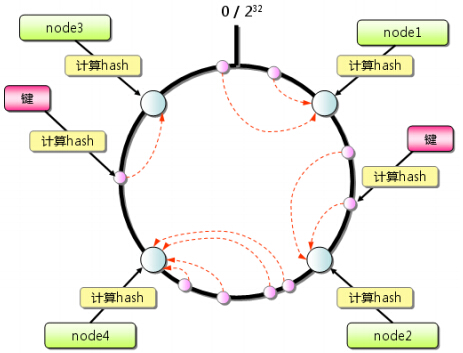
- 原理:先构造一个长度为0~232的整数环(使用二叉树构造),根据节点(memcached服务器)名称的hash值将缓存服务器节点放置在这个hash环上,然后根据需要缓存的数据的key来计算其hash值,然后在hash环上顺时针查找距离这个key的hash值最近的缓存服务器节点,完成key到服务器的hash映射查找。
- 如果超过232还找不到,则存在第一台memcached上(依旧是顺时针)
- 存在的问题:当服务器数量比较少的情况下,有可能造成负载不均衡的情况,为了防止这种情况的发生,使用将物理服务器先虚拟化成多台虚拟服务器,然后将这些虚拟服务器的hash值放在环上,当客户端路由到某台虚拟服务器上时,找到该虚拟服务器所对应的物理服务器即可。
- 一般而言,一台物理服务器虚拟化为150台虚拟服务器最合适,太少会造成负载不均,太多会影响性能
- Memcached采用这样的算法,在我们新加入服务器或集群中的某台服务器宕机时,都不会有太大的影响,只会影响一小段(见下图),确保了集群的可用性与伸缩性

注意:
- hash环是一个二叉树,最后边叶子与最左边相连成环
- 整个缓存的查找过程就是找一个刚刚大于等于查找数的最小值
疑问:(这一点没查到资料)
- 服务器的hash算法是怎样的
- 计算缓存key的hash算法是否要与服务器的一致,还能不能使用原来的hashCode()
思路:hash算法实际上就是"先将字符串转化为整数,然后再将该整数放到相应的服务器上或环上",对于key不用讲,我们可以用crc32将字符串的key转化为整数,之后放在0~232的环上的一点,对于服务器我们可以采用将"ip:port"这个字符串使用crc32转化为整数,之后放在环上(当然这里我们需要将一个实例"ip:port"虚拟化成一堆虚拟节点,每台虚拟节点可以使用"ip:port-i"作为节点名称,其中i是>0的整数,将每台虚拟节点的名称采用crc32算法算出整数放到环上)。
4、slab内存模型
4.1、为什么使用slab内存模型?
在最一开始的内存分配与回收是通过malloc和free来处理的,该方式会产生内存碎片,加重内存管理器的负担,严重缓存操作影响效率。
slab模型的出现就是为了:
- 提高缓存操作效率
- 完全的解决内存碎片问题。
注意:
- 第一个目的:已经实现了(因为直接定位合适的chunk会很快)
- 第二个目的:采用slab机制依旧会产生内存碎片,或者说成是内存浪费
4.2、slab模型原理
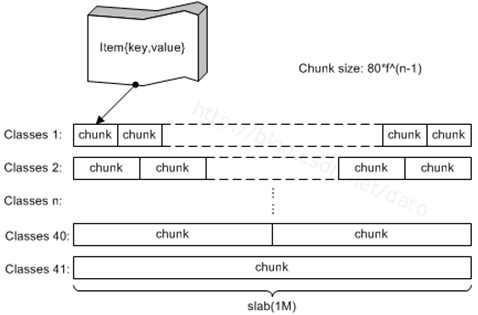
说明:该图摘自一篇博客(图中有标记,但是看不清),但是是很久以前摘的了,忘记了。以后找到了,我会标明出处的。
memcached的内存分配就是下面这一句话:采用分组管理、预分配方式。
4.2.1、分组管理
- 分组方式:Memcached将内存空间分为一组slab,每个slab的大小固定为1M,每个slab里又包含一组chunk,同一个slab里的每个chunk大小相同。根据这些slab中的chunk的大小,将这些slab编号slab class(也就是上图中的Classes i)。
- 存储原理:当来一个要存储的key-value对时,我们查看这个数据的大小,选择最适合的slab class中的空闲chunk放置该对象。
- 最合适的chunk:即该chunk的大小刚刚大于等于所存储数据的大小,而比该chunk小一级的大小刚刚比所要存储的数据小。
以上这种方式会造成内存大量浪费(我认为这也是内存碎片)。
- 减少内存浪费的方式:预估自己的缓存数据的大小,然后在启动Memcached时合理的指定参数-f(增长因子)和-n(chunk最小尺寸)来划分内存大小,根据公式chunk size = 80*f*(n-1)将内存分配为若干个slab class。
疑问:上边这个若干到底是多少?
我们可以根据f,n,以及一个slab最大为1M来确定。(例子,我不举了,自己想想)
4.2.2、预分配
在启动Memcached时通过-m参数为Memcached分配可用内存(假设-m 1024,即分配了1G内存),但是启动的时候不会把这些内存一次全部分配出去,而是默认先分配若干个slab class(数量取决于-f与-n参数),当其中的一个slab class被用完之后,Memcached就会再次申请1M空间,产生一个该slab class。这一块儿结合缓存删除机制中的LRU算法来看。(这一块如果有误,请大神帮忙指出来)
5、缓存删除机制
- memcached不会释放已分配的内存,记录超时后,其存储空间即可重复使用
- memcached内部不会监视缓存是否过期(即memcached不会在过期监视上耗费CPU时间),在get时查看缓存的时间戳,检查缓存是否过期
- memcached会优先使用已超时的缓存的空间,但是当所有空间都没有超时,所有内存都已经分配完了,就删除最近最少使用(LRU)的缓存,将其空间分配给新缓存(注意,假设防止一个100k的数据,而最合适的chunk是112k,假设最合适的chunk全部用完了,这时候就取剩下的内存分配112k chunk的slab,若是剩下的内存页分配完了,不会使用刚刚大于112k的144k chunk,而是会采用LRU算法删除最近最少使用的元素,其实这样的话,就会有一个可能,就是原本112k中的数据还未过期,就有可能被踢出去了,这就是"老数据被踢现象")
注意:第三条与内存分配部分的预分配结合来看。
LRU算法原理:
当某个单元被请求时,维护一个计数器,通过计数器来判断最近最少被使用的元素被踢出去。
6、两种序列化协议
- 文本协议:
- XML、JSON
- key的长度为256字节
- 二进制协议:相较于文本协议
- jdk序列化机制、protobuf
- 不需要文本协议的解析处理,速度更快
- 具有更长的key,理论上最大可使用65536字节长度的key
- 出现在1.4,推荐使用
注意:对于以上两种协议,自己选择吧。
- 二进制协议+JDK的序列化机制,那么由于JDK自己的序列化机制低效,所以在速度上未必会比使用了fastjson的文本协议更快
- 二进制协议+protobuf,速度很快,但是使用起来不太方便
- 文本协议+fastjson
7、部分API
- add:仅当存储空间中不存在相同key的数据时才保存
- replace:替换。即仅当存储空间中存在相同的数据时才保存
- set:add+replace。即无论何时都保存
- delete(key, '阻塞时间(秒)')
- 增1、减1操作,做计数器
- get_multi(key1, key2):一次性非同步的同时(即并发的)获取多个键,比循环调用getKIA数十倍
注意点:
- 对于memcached的监视:可以采用"nagios"


![[8.18]东西放久了会发霉的,网站也一样,拿出来晒晒~~~](http://www.doupack.com/imgs/blog/201008/doupack/5.jpg)