数据采集篇
- 1.数据库设计:
- 2.环境:
- 3.创建项目:
- 4. settings.py
- 5.爬虫编写:
- 6.增量式爬虫:
- 7.启动爬虫:
- 8.总结:
1.数据库设计:
source表(播放源):
| id | name | desc | parse | show |
|---|---|---|---|---|
| 自增id | 播放源名称 | 播放源描述 | 解析url | 展示名 |

video表:
| id | title | desc | type | area | thumb | year | director | introduction | actors |
|---|---|---|---|---|---|---|---|---|---|
| 视频id | 视频名称 | 视频描述 | 类型(1:电影,2:电视剧,3:综艺,4:动漫) | 地区 | 缩略图 | 年份 | 导演 | 简介 | 演员 |

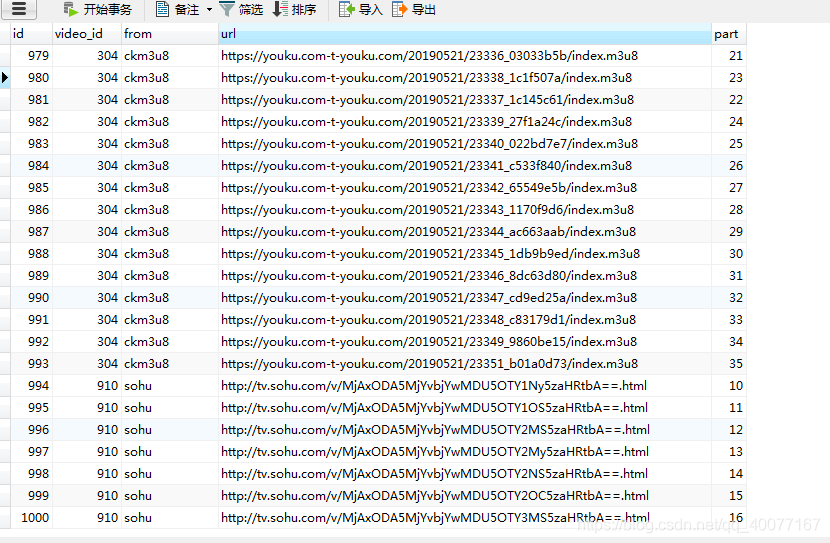
play表:
| id | video_id | from | url | part |
|---|---|---|---|---|
| 自增id | 视频id(与video.id关联) | 播放源名称(与source.name关联) | 播放地址 | 集数 |
2.环境:
- python 3.6.6
- 所用模块:
- scrapy:编写爬虫
- scrapy-redis:与scrapy结合实现增量式爬虫
- requests:发送post,get请求
- windows7系统
- mysql数据库:存储数据
- redis数据库
3.创建项目:
scrapy startproject project_name
4. settings.py
LOG_LEVEL="WARNING"
USER_AGENT="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Scrapy_www_vultr1_com (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = False5.爬虫编写:
初始化(连接数据库):
def __init__(self):dict = {}dict["host"] = self.MYSQL_HOSTdict["port"] = self.MYSQL_PORTdict["user"] = self.MYSQL_USERdict["passwd"] = self.MYSQL_PWDdict["db"] = self.MYSQL_DBdict["use_unicode"]=Truedict["charset"]="utf8"self.db = MySQLdb.connect(**dict)#self.playerconfig()
处理响应:
def parse(self, response):href_list = response.xpath("//ul[@class='stui-header__menu type-slide']/li/a/@href")[1:-1]for href in href_list:_type=re.search(r"v/(\d*).html",href.get()).group(1)yield scrapy.Request(self.domain+href.get(),callback=self.parse_item,meta={"type":_type})#处理专题def parse_item(self, response):a_list=response.xpath("//a[@class='stui-vodlist__thumb lazyload']/@href")for a in a_list:yield scrapy.Request(self.domain+a.extract(),callback=self.parse_detail,meta={"type": response.meta["type"]})#print(self.domain + a.extract() +"---已抓取")next_url = response.xpath("//ul[@class='stui-page text-center clearfix']/li/a[text()='下1页']/@href").extract_first(default="")last_url = response.xpath("//ul[@class='stui-page text-center clearfix']/li/a[text()='尾页']/@href").extract_first(default="")active_url=response.xpath("//ul[@class='stui-page text-center clearfix']/li[@class='hidden-xs active']/a/@href").extract_first(default="")if (next_url != None) and active_url!=last_url:#print("---------------------")print("next_url:"+self.domain + next_url + "---已抓取")yield scrapy.Request(self.domain + next_url, callback=self.parse_item,meta={"type":response.meta["type"]})else:print("数据已爬完.......")#处理详情页def parse_detail(self,response):item={}item["table"]="video"item["id"]=re.search(r"video/(\d*).html",response.request.url).group(1)item['thumb']=response.xpath("//img[@class='lazyload']/@src").get(default="")item['title']=response.xpath("//h1[@class='title']/text()").extract_first(default="")#item['type']=response.xpath("//p[@class='data ']/a/text()").extract_first()item["type"]=response.meta["type"]item['area']=response.xpath("//p[@class='data ']/text()[4]").extract_first(default="").replace('\t','')item['year'] = response.xpath("//p[@class='data ']/text()[6]").extract_first(default="").replace('\t','').replace('\r\n','')item['director']=response.xpath("//p[@class='data'][2]/a/text()").get(default="")item['introduction']=""sketch=response.xpath("//span[@class='detail-sketch']/text()")content=response.xpath("//span[@class='detail-content']/text()")if sketch:item['introduction'] +=sketch.get(default="")if content:item['introduction'] += sketch.get(default="")item['actors'] =""for s in response.xpath("//p[@class='data'][1]/a/text()"):item['actors']+=s.extract()+" "yield item#之后略#处理视频播放页def parse_play(self,response):item={}item["part"]=response.meta["part"]item["video_id"] = response.meta["video_id"]item["table"]="play"player_data=re.search(r"player_data=(.*?)</script>",response.text).group(1)player_data=json.loads(player_data)item["from"]=player_data["from"]item["url"]=player_data["url"]yield item
piplines(数据处理:存入数据库)
def process_item(self, item, spider):#print(item)sql=""sql+="INSERT INTO "+item["table"]+" SET "item.pop("table")for k,v in item.items():if k=="id" or k=="video_id" or k=="part" or k=="type":sql += "`" + k + "`=" + v + ","else:sql+="`"+k+"`=\""+v+"\","sql=sql[:-1]#print(sql)cursor=spider.db.cursor()cursor.execute(sql)spider.db.commit()return item
6.增量式爬虫:
- settings.py:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = TrueREDIS_URL="redis://127.0.0.1:6379"
- spider继承RedisSpider
- redis数据库写入键值:
LPUSH spider_name:start_urls start_url
7.启动爬虫:
scrapy crawl spider_name
8.总结:
- re.match与re.search区别:match是从字符串开头开始匹配,search则不是
- response.xpath返回的是SelectorList ,是一个包含Selector的列表
class SelectorList(list):def getall(self):"""Call the ``.get()`` method for each element is this list and returntheir results flattened, as a list of unicode strings."""return [x.get() for x in self]extract = getalldef get(self, default=None):"""Return the result of ``.get()`` for the first element in this list.If the list is empty, return the default value."""for x in self:return x.get()else:return defaultextract_first = get
class Selector(object):def get(self):"""Serialize and return the matched nodes in a single unicode string.Percent encoded content is unquoted."""try:return etree.tostring(self.root,method=self._tostring_method,encoding='unicode',with_tail=False)except (AttributeError, TypeError):if self.root is True:return u'1'elif self.root is False:return u'0'else:return six.text_type(self.root)extract = getdef getall(self):"""Serialize and return the matched node in a 1-element list of unicode strings."""return [self.get()]