Python爬取猫眼网站榜单TOP100,并存入CSV文件!
1. 目标网址
看到榜单的时候网址是https://maoyan.com/board/4是这样的,通过下一页看到https://maoyan.com/board/4?offset=10,然后在下一页https://maoyan.com/board/4?offset=20,所以得到规律,其实首页也可以这样访问https://maoyan.com/board/4?offset=0
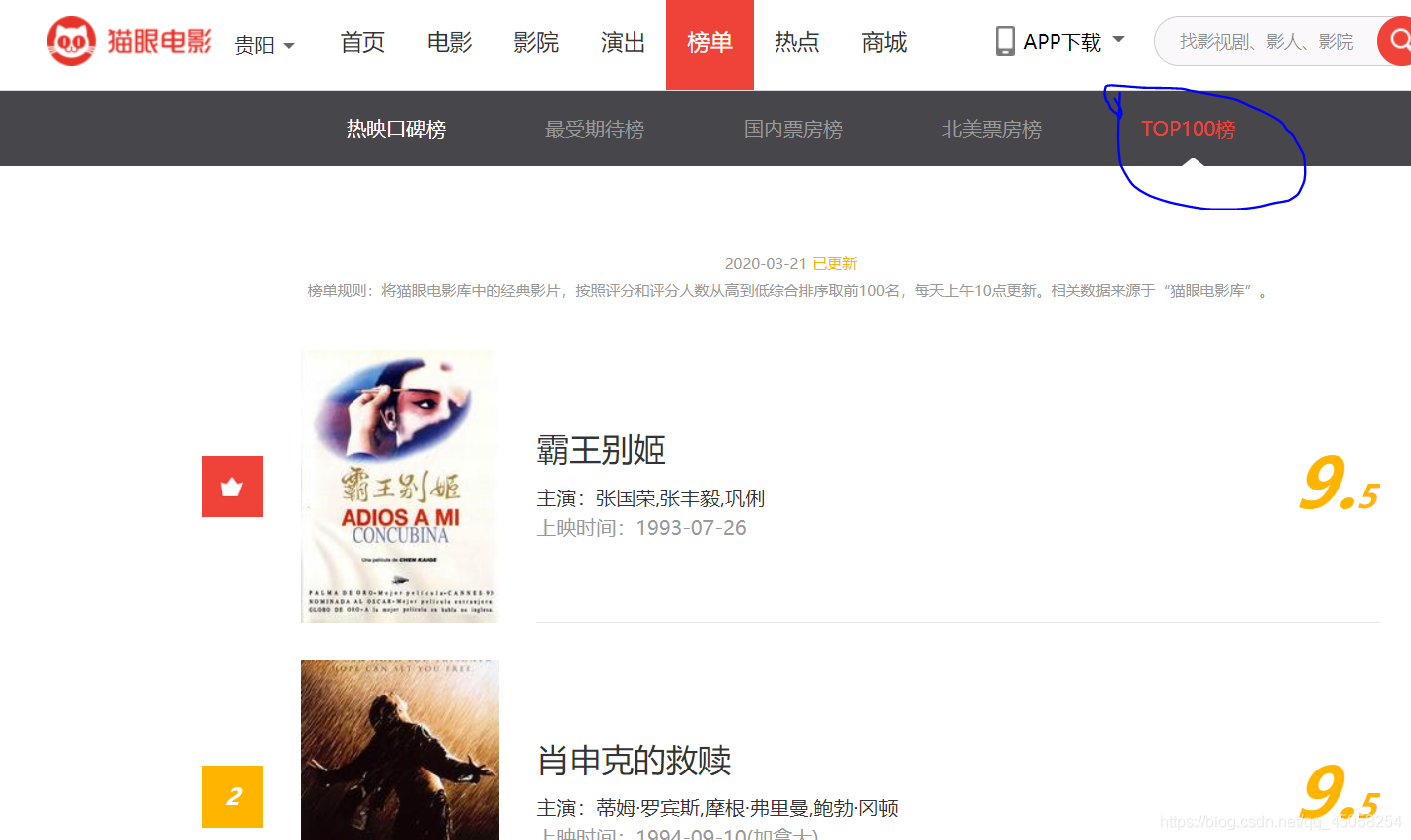
2. 请求网页,出现的问题
一定要记得带请求头,因为现在的网站反爬虫机制还是挺厉害的,必须模仿浏览器访问,针对一些网站访问的时候必须请求头,不要因为坏毛病不带请求头,在编写代码的时候我没带请求头只能访问到猫眼网站的详情页,害我找了半天的毛病的,并且控制台的打印的字符简直看不清楚,如下图。然后呢,还有一个问题,如果你用自己的浏览器的请求头的访问还是详情页,建议去找哈其他浏览器的请求头,这里我用的极速浏览器的请求头只能访问详情页,应该是浏览器的内核问题,换成谷歌,火狐浏览的请求头也就可以了。

3. 编写代码
这里我用的parsel库,这个库解析的网页支持xpath,css,re正则,提取网页元素,感觉这个库挺好用的,值得推荐。
在存储数据的时候,遇到一些问题想使用pandas的DataFarms来直接导出数据这样也就很方便了,但是我发现不能追加数据在同一张表上(应该是可以的,我对这个库不太熟悉),然后就用了下面的这个方法两次操作同一个CSV文件也达到了了预期的效果,就是感觉这办法挺生硬的,简单的来说第一次打开文件进行第一行的字段说明写入,然后第二次打开文件对数据的追加写入,所以存在两个with open()。
# -*- coding: utf-8 -*-
#@Project filename:PythonDemo MaoyanTOP100.py
#@IDE :IntelliJ IDEA
#@Author :ganxiang
#@Date :2020/03/21 0021 09:36import parsel
import requests
import csv
from concurrent.futures import ThreadPoolExecutor,wait,ALL_COMPLETED
import time
def parse_html(url,i):# url ="https://maoyan.com/board/4?offset=10"headers = { 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0" }res =requests.get(url,headers=headers)# print(res.text)sels=parsel.Selector(res.text)##解析网页texts =sels.css("dd")#css定位到存放电影标签的上级标签with open("./SaveData/maoyanTOP100.csv",'a+',newline="")as f:write =csv.writer(f)for sel in texts:title=sel.css('p.name a::text').getall()[0]#getall()以列表的形式返回所有数据,get()返回一个数据href=sel.css('p.name a::attr(href)').getall()[0]actor =sel.css('p.star ::text').getall()[0].strip()show_time =str(sel.css('p.releasetime ::text').getall()[0]).replace("上映时间:","")score ="".join(sel.css('p.score i::text').getall())row =[str(i),str(title),"https://maoyan.com"+str(href),actor,show_time,score]write.writerow(row)print(i,title,"https://maoyan.com"+str(href),actor,show_time,score)i+=1def run():t1 =time.time()with open("./SaveData/maoyanTOP100.csv",'w',newline="")as f:header=["rank","电影名","电影链接","演员","上映时间","评分"]write=csv.writer(f)write.writerow(header)#1,不使用多线程执行程序# for i in range(0,110,10):# url ="https://maoyan.com/board/4?offset={}".format(i)# parse_html(url,i+1)#2,使用多线程执行程序executor =ThreadPoolExecutor(max_workers=3)#设置线程个数# submit()的参数:第一个为函数,其他是为该函数的传入参数,允许有多个tasks =[executor.submit(parse_html,"https://maoyan.com/board/4?offset={}".format(url),url)for url in range(0,110,10)]wait(tasks, return_when=ALL_COMPLETED)# 等待所有的线程完成,才进入后续的执行t2=time.time()print("使用线程的时间为:",t2-t1)#使用线程的时间为: 1.9762754440307617# print("不使用线程的时间为:",t2-t1)#不使用线程的时间为: 7.454896450042725if __name__ =='__main__':run()4. 效果如图
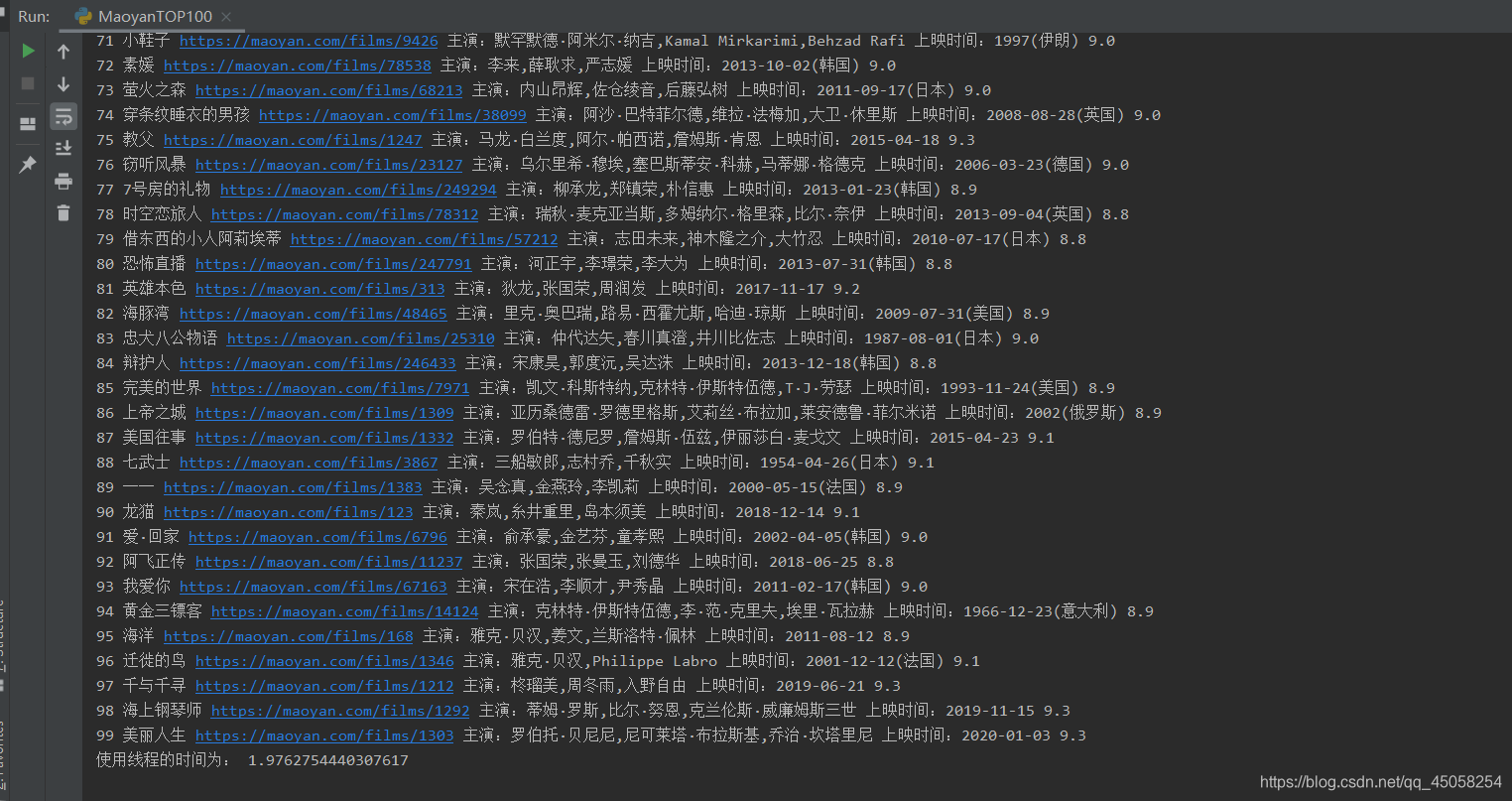
5.csv中展示
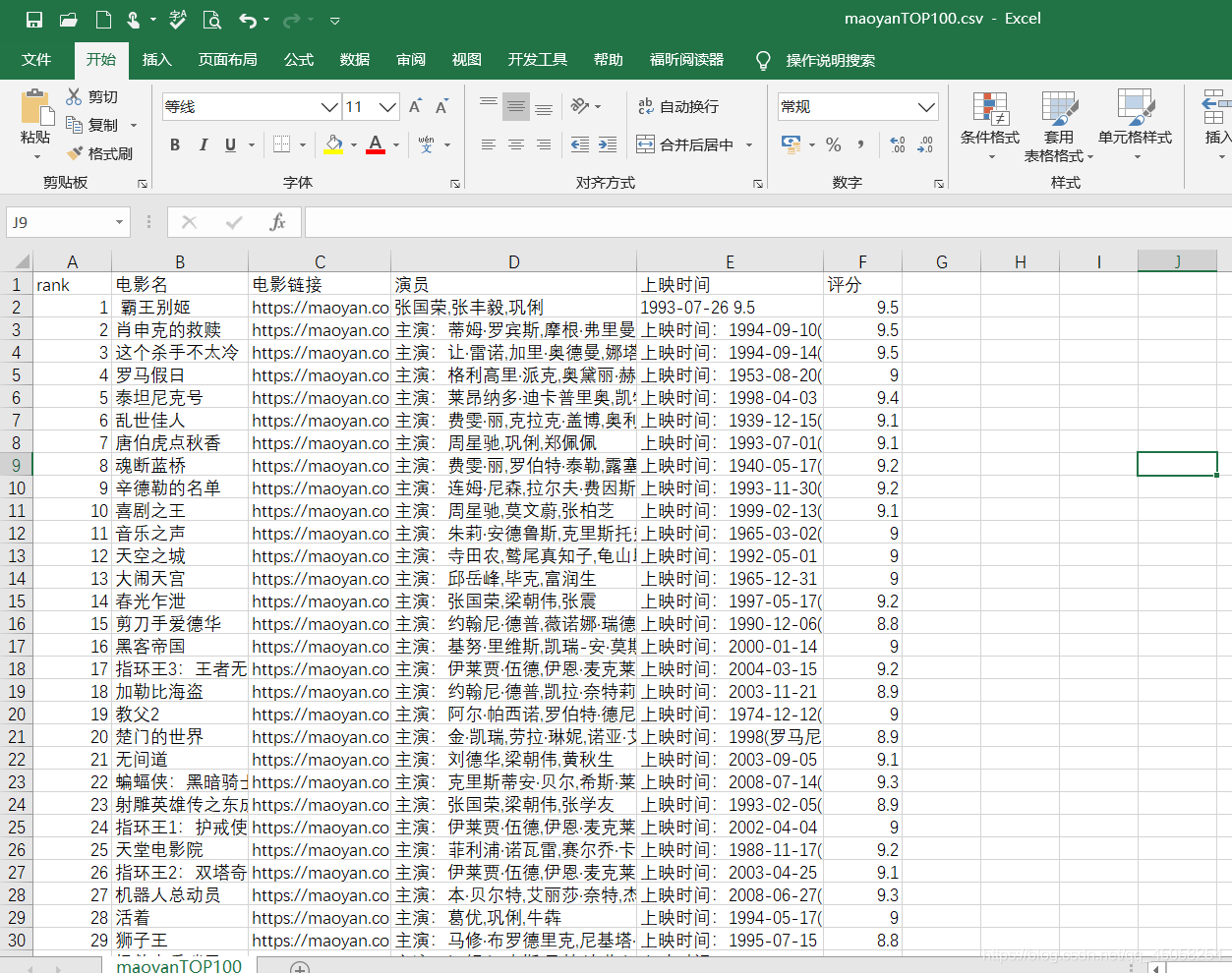
欧克啦