博文作者:妳那伊抹微笑
itdog8 地址链接 : http://www.itdog8.com(个人链接)
博文标题:_00019 Storm的体系结构介绍以及Storm入门案例(官网上的简单Java案例)
个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前。妳却感觉不到我的存在
技术方向:Flume+Kafka+Storm+Redis/Hbase+Hadoop+Hive+Mahout+Spark ... 云计算技术
转载声明:能够转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明。谢谢合作!
qq交流群:214293307
 (期待与你一起学习。共同进步)
(期待与你一起学习。共同进步)# Storm的体系结构
# Storm介绍
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的还有一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询。在计算时就将结果以流的形式输出给用户。
它还可被用于“分布式RPC”,以并行的方式执行昂贵的运算。 Storm的主project师Nathan Marz表示:
Storm能够方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm之于实时处理,就好比Hadoop之于批处理。Storm保证每一个消息都会得到处理,并且它非常快。在一个小集群中,每秒能够处理数以百万计的消息。更棒的是你能够使用随意编程语言来做开发。
Storm的主要特点例如以下:
简单的编程模型。
类似于MapReduce减少了并行批处理复杂性,Storm减少了进行实时处理的复杂性。
能够使用各种编程语言。
你能够在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要添加对其它语言的支持。仅仅需实现一个简单的Storm通信协议就可以。
容错性。Storm会管理工作进程和节点的故障。
水平扩展。计算是在多个线程、进程和server之间并行进行的。
可靠的消息处理。Storm保证每一个消息至少能得到一次完整处理。任务失败时。它会负责从消息源重试消息。
高速。
系统的设计保证了消息能得到高速的处理,使用ØMQ作为其底层消息队列。
本地模式。Storm有一个“本地模式”。能够在处理过程中全然模拟Storm集群。
这让你能够高速进行开发和单元測试。
Storm集群由一个主节点和多个工作节点组成。
主节点执行了一个名为“Nimbus”的守护进程。用于分配代码、布置任务及故障检測。
每一个工作节点都执行了一个名为“Supervisor”的守护进程,用于监听工作。開始并终止工作进程。
Nimbus和Supervisor都能高速失败,并且是无状态的,这样一来它们就变得十分健壮。两者的协调工作是由ApacheZooKeeper来完毕的。
Storm的术语包含Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology。Stream是被处理的数据。Spout是数据源。Bolt处理数据。
Task是执行于Spout或Bolt中的线程。Worker是执行这些线程的进程。Stream Grouping规定了Bolt接收什么东西作为输入数据。数据能够随机分配(术语为Shuffle),或者依据字段值分配(术语为Fields),或者广播(术语为All),或者总是发给一个Task(术语为Global),也能够不关心该数据(术语为None),或者由自己定义逻辑来决定(术语为 Direct)。Topology是由StreamGrouping连接起来的Spout和Bolt节点网络。在Storm Concepts页面里对这些术语有更具体的描写叙述。
能够和Storm相提并论的系统有Esper、Streambase、HStreaming和Yahoo S4。
当中和Storm最接近的就是S4。两者最大的差别在于Storm会保证消息得到处理。Storm,假设须要持久化。能够使用一个类似于Cassandra或Riak这种外部数据库。Storm是分布式数据处理的框架。本身差点儿不提供复杂事件计算。而Esper、Streambase属于CEP系统。
# Storm基本概念
Storm是一个开源的实时计算系统,它提供了一系列的基本元素用于进行计算:Topology、Stream、Spout、Bolt等等。
在Storm中。一个实时应用的计算任务被打包作为Topology公布,这同Hadoop的MapReduce任务相似。可是有一点不同的是:在Hadoop中。MapReduce任务终于会运行完毕后结束;而在Storm中。Topology任务一旦提交后永远不会结束,除非你显示去停止任务。
计算任务Topology是由不同的Spouts和Bolts。通过数据流(Stream)连接起来的图。以下是一个Topology的结构示意图:

当中包括有:
Spout:Storm中的消息源,用于为Topology生产消息(数据),通常是从外部数据源(如Message Queue、RDBMS、NoSQL、Realtime Log)不间断地读取数据并发送给Topology消息(tuple元组)。
Bolt:Storm中的消息处理者,用于为Topology进行消息的处理。Bolt能够运行过滤。 聚合。 查询数据库等操作。并且能够一级一级的进行处理。
终于,Topology会被提交到storm集群中执行。也能够通过命令停止Topology的执行,将Topology占用的计算资源归还给Storm集群。
# Storm数据流模型
数据流(Stream)是Storm中对数据进行的抽象,它是时间上无界的tuple元组序列。
在Topology中,Spout是Stream的源头,负责为Topology从特定数据源发射Stream;Bolt能够接收随意多个Stream作为输入,然后进行数据的加工处理过程,假设须要,Bolt还能够发射出新的Stream给下级Bolt进行处理。
以下是一个Topology内部Spout和Bolt之间的数据流关系:

Topology中每个计算组件(Spout和Bolt)都有一个并行运行度,在创建Topology时能够进行指定,Storm会在集群内分配相应并行度个数的线程来同一时候运行这一组件。
那么,有一个问题:既然对于一个Spout或Bolt,都会有多个task线程来执行,那么怎样在两个组件(Spout和Bolt)之间发送tuple元组呢?
Storm提供了若干种数据流分发(StreamGrouping)策略用来解决这一问题。
在Topology定义时,须要为每一个Bolt指定接收什么样的Stream作为其输入(注:Spout并不须要接收Stream。仅仅会发射Stream)。
眼下Storm中提供了下面7种Stream Grouping策略:ShuffleGrouping、Fields Grouping、AllGrouping、Global Grouping、NonGrouping、Direct Grouping、Localor shuffle grouping,详细策略能够參考这里。
# Storm两种安装方式
# Storm本地安装
请看Storm集群安装,仅仅要在一台server上同一时候执行Nimbus,Supervisor,UI即可了
# Storm集群安装
# Storm集群架构图
注意:该集群结构图是依据 Hadoop-2.2.0+Hbase-0.96.2 +Hive-0.13.1这篇博文来的。假设不明确能够看看刚刚那篇博文
| ip地址 | 主机名 | ZK | Nimbus | Supervisor | UI |
| 192.168.1.229 | rs229 | 是 | 是 | 否 | 是 |
| 192.168.1.227 | rs227 | 是 | 否 | 否 | 否 |
| 192.168.1.226 | rs226 | 是 | 否 | 是 | 否 |
| 192.168.1.198 | rs198 | 是 | 否 | 是 | 否 |
| 192.168.1.197 | rs197 | 是 | 否 | 是 | 否 |
| 192.168.1.196 | rs196 | 否 | 否 | 是 | 否 |
一个Nimbus,UI,多个Supervisor
# Zookeeper集群的安装
这个Zookeeper集群的搭建在Hadoop-2.2.0 +Hbase-0.96.2+Hive-0.13.1分布式环境搭建博文中有,能够參考,这里不再叙述了。
# Storm的依赖JDK,Python的安装
这里也不再叙述了。以下是官网原文推荐版本号
Next you need to install Storm’s dependencies on Nimbus and the workermachines. These are:
- Java 6
- Python 2.6.6
These are the versions of the dependencies that have been tested withStorm. Storm may or may not work with different versions of Java and/or Python.
# Storm的解压apache-storm-0.9.2-incubating.zip
[root@rs229 storm]# pwd
/usr/local/adsit/yting/apache/storm
[root@rs229 storm]# ll
total 19684
drwxr-xr-x 9 root root 4096 Apr 25 16:48apache-storm-0.9.1-incubating
-rw-r--r-- 1 root root 20151543 Jul 7 11:48 apache-storm-0.9.2-incubating.zip
[root@rs229 storm]# unzipapache-storm-0.9.2-incubating.zip
[root@rs229 storm]# ll
total 19688
drwxr-xr-x 9 root root 4096 Apr 25 16:48apache-storm-0.9.1-incubating
drwxrwxrwx 9 root root 4096 Jun 16 12:22apache-storm-0.9.2-incubating
-rw-r--r-- 1 root root 20151543 Jul 7 11:48 apache-storm-0.9.2-incubating.zip
[root@rs229 storm]# cd apache-storm-0.9.2-incubating
[root@rs229 apache-storm-0.9.2-incubating]# ll
total 112
drwxrwxrwx 2 root root 4096 Jun 16 12:22 bin
-rw-r--r-- 1 root root 34239 Jun 12 20:46CHANGELOG.md
drwxrwxrwx 2 root root 4096 Jun 16 12:22 conf
-rw-r--r-- 1 root root 538 Mar 12 23:17 DISCLAIMER
drwxrwxrwx 3 root root 4096 Jun 16 12:22 examples
drwxrwxrwx 3 root root 4096 Jun 16 12:22 external
drwxrwxrwx 2 root root 4096 Jun 16 12:22 lib
-rw-r--r-- 1 root root 22822 Jun 11 16:07 LICENSE
drwxrwxrwx 2 root root 4096 Jun 16 12:22 logback
-rw-r--r-- 1 root root 981 Jun 10 13:10 NOTICE
drwxrwxrwx 5 root root 4096 Jun 16 12:22 public
-rw-r--r-- 1 root root 7445 Jun 9 14:24 README.markdown
-rw-r--r-- 1 root root 17 Jun 16 12:22 RELEASE
-rw-r--r-- 1 root root 3581 May 29 12:20 SECURITY.md
[root@rs229 apache-storm-0.9.2-incubating]# cd conf
[root@rs229 conf]# ll
total 8
-rw-r--r-- 1 root root 1126 May 28 12:24storm_env.ini
-rw-r--r-- 1 root root 1613 May 28 12:24 storm.yaml
# 改动storm.yaml配置文件
### ldir
storm.local.dir: "/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/ldir"
### zookeeper
storm.zookeeper.servers:
-"rs229"
-"rs227"
-"rs226"
-"rs198"
-"rs197"
### nimbus host
nimbus.host: "rs229"
### ui.* configs are for the master
ui.port: 8081 # 我这里改动了storm的ui端口
# 官方默认的配置文件
# Licensed to the Apache Software Foundation (ASF)under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additionalinformation
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this fileexcept in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to inwriting, software
# distributed under the License is distributed on an"AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,either express or implied.
# See the License for the specific language governingpermissions and
# limitations under the License.
########### These all have default values as shown
########### Additional configuration goes intostorm.yaml
java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib"
### storm.* configs are general configurations
# the local dir is where jars are kept
storm.local.dir: "storm-local"
storm.zookeeper.servers:
-"localhost"
storm.zookeeper.port: 2181
storm.zookeeper.root: "/storm"
storm.zookeeper.session.timeout: 20000
storm.zookeeper.connection.timeout: 15000
storm.zookeeper.retry.times: 5
storm.zookeeper.retry.interval: 1000
storm.zookeeper.retry.intervalceiling.millis: 30000
storm.cluster.mode: "distributed" # can bedistributed or local
storm.local.mode.zmq: false
storm.thrift.transport:"backtype.storm.security.auth.SimpleTransportPlugin"
storm.messaging.transport:"backtype.storm.messaging.netty.Context"
### nimbus.* configs are for the master
nimbus.host: "localhost"
nimbus.thrift.port: 6627
nimbus.thrift.max_buffer_size: 1048576
nimbus.childopts: "-Xmx1024m"
nimbus.task.timeout.secs: 30
nimbus.supervisor.timeout.secs: 60
nimbus.monitor.freq.secs: 10
nimbus.cleanup.inbox.freq.secs: 600
nimbus.inbox.jar.expiration.secs: 3600
nimbus.task.launch.secs: 120
nimbus.reassign: true
nimbus.file.copy.expiration.secs: 600
nimbus.topology.validator:"backtype.storm.nimbus.DefaultTopologyValidator"
### ui.* configs are for the master
ui.port: 8080
ui.childopts: "-Xmx768m"
logviewer.port: 8000
logviewer.childopts: "-Xmx128m"
logviewer.appender.name: "A1"
drpc.port: 3772
drpc.worker.threads: 64
drpc.queue.size: 128
drpc.invocations.port: 3773
drpc.request.timeout.secs: 600
drpc.childopts: "-Xmx768m"
transactional.zookeeper.root:"/transactional"
transactional.zookeeper.servers: null
transactional.zookeeper.port: null
### supervisor.* configs are for node supervisors
# Define the amount of workers that can be run onthis machine. Each worker is assigned a port to use for communication
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
supervisor.childopts: "-Xmx256m"
#how long supervisor will wait to ensure that aworker process is started
supervisor.worker.start.timeout.secs: 120
#how long between heartbeats until supervisorconsiders that worker dead and tries to restart it
supervisor.worker.timeout.secs: 30
#how frequently the supervisor checks on the statusof the processes it's monitoring and restarts if necessary
supervisor.monitor.frequency.secs: 3
#how frequently the supervisor heartbeats to thecluster state (for nimbus)
supervisor.heartbeat.frequency.secs: 5
supervisor.enable: true
### worker.* configs are for task workers
worker.childopts: "-Xmx768m"
worker.heartbeat.frequency.secs: 1
# control how many worker receiver threads we needper worker
topology.worker.receiver.thread.count: 1
task.heartbeat.frequency.secs: 3
task.refresh.poll.secs: 10
zmq.threads: 1
zmq.linger.millis: 5000
zmq.hwm: 0
storm.messaging.netty.server_worker_threads: 1
storm.messaging.netty.client_worker_threads: 1
storm.messaging.netty.buffer_size: 5242880 #5MBbuffer
storm.messaging.netty.max_retries: 30
storm.messaging.netty.max_wait_ms: 1000
storm.messaging.netty.min_wait_ms: 100
# If the Netty messaging layer is busy(netty internalbuffer not writable), the Netty client will try to batch message as more aspossible up to the size of storm.messaging.netty.transfer.batch.size bytes,otherwise it will try to flush message as soon as possible to reduce latency.
storm.messaging.netty.transfer.batch.size: 262144
# We check with this interval that whether the Nettychannel is writable and try to write pending messages if it is.
storm.messaging.netty.flush.check.interval.ms: 10
### topology.* configs are for specific executingstorms
topology.enable.message.timeouts: true
topology.debug: false
topology.workers: 1
topology.acker.executors: null
topology.tasks: null
# maximum amount of time a message has to completebefore it's considered failed
topology.message.timeout.secs: 30
topology.multilang.serializer:"backtype.storm.multilang.JsonSerializer"
topology.skip.missing.kryo.registrations: false
topology.max.task.parallelism: null
topology.max.spout.pending: null
topology.state.synchronization.timeout.secs: 60
topology.stats.sample.rate: 0.05
topology.builtin.metrics.bucket.size.secs: 60
topology.fall.back.on.java.serialization: true
topology.worker.childopts: null
topology.executor.receive.buffer.size: 1024 #batched
topology.executor.send.buffer.size: 1024 #individualmessages
topology.receiver.buffer.size: 8 # setting it toohigh causes a lot of problems (heartbeat thread gets starved, throughputplummets)
topology.transfer.buffer.size: 1024 # batched
topology.tick.tuple.freq.secs: null
topology.worker.shared.thread.pool.size: 4
topology.disruptor.wait.strategy:"com.lmax.disruptor.BlockingWaitStrategy"
topology.spout.wait.strategy:"backtype.storm.spout.SleepSpoutWaitStrategy"
topology.sleep.spout.wait.strategy.time.ms: 1
topology.error.throttle.interval.secs: 10
topology.max.error.report.per.interval: 5
topology.kryo.factory:"backtype.storm.serialization.DefaultKryoFactory"
topology.tuple.serializer: "backtype.storm.serialization.types.ListDelegateSerializer"
topology.trident.batch.emit.interval.millis: 500
topology.classpath: null
topology.environment: null
dev.zookeeper.path:"/tmp/dev-storm-zookeeper"
# 将storm的文件夹拷贝到其他发server下去
(不复制也行。直接在Nimbus的server启动3个进程都OK,一个server的集群 - -!)
饿这里的话启动了一个Nimbus,三个Supervisor。一个UI,当中Nimbus跟UI都是在一台server上面。三个Supervisor分别在不同的server上面
[root@rs229 storm]# scp -r/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubatina rs198:/usr/local/adsit/yting/apache/storm/
[root@rs229 storm]# scp -r/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubatina rs197:/usr/local/adsit/yting/apache/storm/
[root@rs229 storm]# scp -r/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubatinars196:/usr/local/adsit/yting/apache/storm/
# Nimbus的启动
后台启动。懒得开shell,以下也一样都是后台启动的。不解释 、、、
[root@rs229 apache-storm-0.9.2-incubating]# bin/storm nimbus &
[1] 16025
[root@rs229 apache-storm-0.9.2-incubating]# Running:/usr/local/adsit/yting/jdk/jdk1.7.0_60/bin/java -server -Dstorm.options=-Dstorm.home=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating-Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file=-cp /…:/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/conf-Xmx1024m -Dlogfile.name=nimbus.log-Dlogback.configurationFile=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/logback/cluster.xmlbacktype.storm.daemon.nimbus
# Supervisor的启动
# rs226上启动Supervisor
[root@rs226 apache-storm-0.9.2-incubating]# bin/storm supervisor &
[1] 15273
[root@rs226 apache-storm-0.9.2-incubating]# Running:/usr/local/adsit/yting/jdk/jdk1.7.0_60/bin/java -server -Dstorm.options=-Dstorm.home=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating-Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file=-cp /…:/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/conf-Xmx256m -Dlogfile.name=supervisor.log -Dlogback.configurationFile=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/logback/cluster.xmlbacktype.storm.daemon.supervisor
# rs198上启动Supervisor
[root@rs198 apache-storm-0.9.2-incubating]# bin/storm supervisor &
[1] 15273
[root@RS198 apache-storm-0.9.2-incubating]# Running:/usr/local/adsit/yting/jdk/jdk1.7.0_60/bin/java -server -Dstorm.options=-Dstorm.home=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating-Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file=-cp /…:/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/conf-Xmx256m -Dlogfile.name=supervisor.log -Dlogback.configurationFile=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/logback/cluster.xmlbacktype.storm.daemon.supervisor
# rs197上启动Supervisor
[root@RS197 apache-storm-0.9.2-incubating]# bin/stormsupervisor &
[1] 25262
[root@RS197 apache-storm-0.9.2-incubating]# Running:/root/jdk1.6.0_26/bin/java -server -Dstorm.options=-Dstorm.home=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating-Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file=-cp /…:/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/conf-Xmx256m -Dlogfile.name=supervisor.log-Dlogback.configurationFile=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/logback/cluster.xmlbacktype.storm.daemon.supervisor
# rs167上启动Supervisor
[root@RS196 apache-storm-0.9.2-incubating]# bin/stormsupervisor &
[1] 17330
[root@RS196 apache-storm-0.9.2-incubating]# Running:/root/jdk1.6.0_26/bin/java -server -Dstorm.options=-Dstorm.home=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating-Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file=-cp /…:/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/conf-Xmx256m -Dlogfile.name=supervisor.log-Dlogback.configurationFile=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/logback/cluster.xmlbacktype.storm.daemon.supervisor
# UI的启动
[root@rs229 apache-storm-0.9.2-incubating]# bin/storm ui &
[2] 16145
[root@rs229 apache-storm-0.9.2-incubating]# Running:/usr/local/adsit/yting/jdk/jdk1.7.0_60/bin/java -server -Dstorm.options=-Dstorm.home=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating-Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file=-cp /…:/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/conf-Xmx768m -Dlogfile.name=ui.log-Dlogback.configurationFile=/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/logback/cluster.xmlbacktype.storm.ui.core
# 在浏览器上訪问Storm UI(记得我们在配置文件里把Storm UI的port改为了8081)
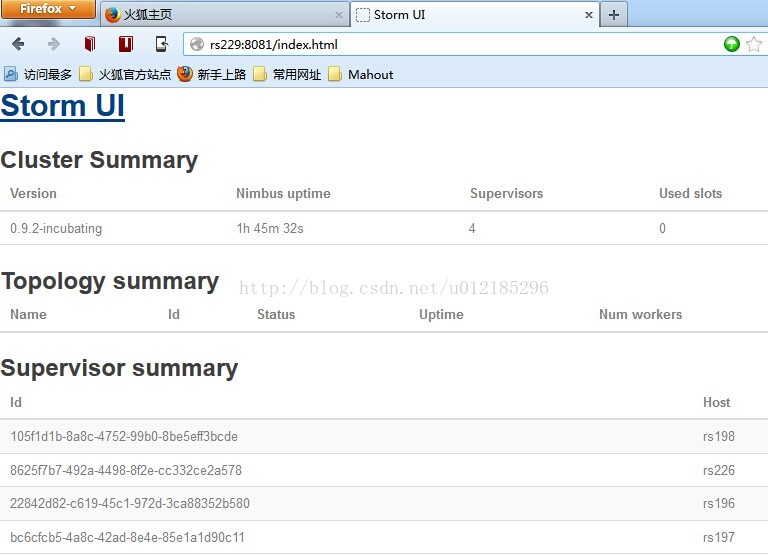
# Zookeeper下查看是否有相应storm的文件夹
[root@rs229 ldir]# zkCli.sh
Connecting to localhost:2181
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[storm, hbase,hadoop-ha, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /storm
[workerbeats, errors, supervisors, storms,assignments]
[zk: localhost:2181(CONNECTED) 2]
能够看出zookeeper已经管理storm了
# Storm集群环境已经搭建成功,以下请看Storm之入门案例一
# Storm之入门案例一(官网案例)
# 说明
这是一个单词统计的程序,Java版本号。官网给的。想要看详细的源代码的话就用Eclipse关联源代码吧!
# Java代码
package com.yting.cloud.storm.example;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
importbacktype.storm.generated.AlreadyAliveException;
importbacktype.storm.generated.InvalidTopologyException;
import backtype.storm.testing.TestGlobalCount;
import backtype.storm.testing.TestWordCounter;
import backtype.storm.testing.TestWordSpout;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.utils.Utils;
/**
* 官网给的代码,改了下并行数的大小
*
* @Author 王扬庭(妳那伊抹微笑)
* @Time2014-07-07
*
*/
public class Example {
publicstatic void main(String[] args) throws Exception {
stormLocal();
//stormCluster();
}
/**
* Local
*/
privatestatic void stormLocal() {
//并行大小所有改为1了,为了该程序能够适应Local
TopologyBuilderbuilder = new TopologyBuilder();
builder.setSpout("1",new TestWordSpout(true), 1);
builder.setSpout("2",new TestWordSpout(true), 1);
builder.setBolt("3",new TestWordCounter(), 1).fieldsGrouping("1", newFields("word")).fieldsGrouping("2", newFields("word"));
builder.setBolt("4",new TestGlobalCount()).globalGrouping("1");
Mapconf = new HashMap();
conf.put(Config.TOPOLOGY_WORKERS,4);
conf.put(Config.TOPOLOGY_DEBUG,true);
LocalClustercluster = new LocalCluster();
cluster.submitTopology("mytopology",conf, builder.createTopology());
Utils.sleep(10000);
cluster.shutdown();
}
/**
* Cluster
*
* @throws AlreadyAliveException
* @throws InvalidTopologyException
*/
privatestatic void stormCluster() throws AlreadyAliveException,InvalidTopologyException {
TopologyBuilderbuilder = new TopologyBuilder();
builder.setSpout("1",new TestWordSpout(true), 5);
builder.setSpout("2",new TestWordSpout(true), 3);
builder.setBolt("3",new TestWordCounter(), 3).fieldsGrouping("1", newFields("word")).fieldsGrouping("2", newFields("word"));
builder.setBolt("4",new TestGlobalCount()).globalGrouping("1");
Mapconf = new HashMap();
conf.put(Config.TOPOLOGY_WORKERS,4);
StormSubmitter.submitTopology("mytopology",conf, builder.createTopology());
}
}
# 将上面的代码在Eclipse下打成jar包并上传到server上去,使用storm命令运行。然后看以下的日志输出
[root@rs229 yjar]# pwd
/usr/local/adsit/yting/apache/storm/apache-storm-0.9.2-incubating/yjar
[root@rs229 yjar]# ll
total 32
-rw-r--r-- 1 root root 15149 Jul 7 16:49 storm-wordcount-official-cluster.jar
-rw-r--r-- 1 root root 15195 Jul 7 16:50storm-wordcount-official-local.jar
[root@rs229 yjar]#
[root@rs229 yjar]# storm jar./storm-wordcount-official-local.jar com.yting.cloud.storm.example.Example
# 分析日志输出(仅仅保留了实用的一部分,日志信息太多了)
14268 [Thread-26-2] INFO backtype.storm.daemon.task - Emitting: 2default[jackson]
14269 [Thread-10-3] INFO backtype.storm.daemon.executor - Processingreceived message source: 2:2, stream: default, id: {}, [jackson]
14269 [Thread-10-3] INFO backtype.storm.daemon.task - Emitting: 3default[jackson, 32]
14291 [Thread-32-1] INFO backtype.storm.daemon.task - Emitting: 1default [jackson]
14292 [Thread-10-3] INFO backtype.storm.daemon.executor - Processingreceived message source: 1:1, stream: default, id: {}, [jackson]
14292 [Thread-9-4] INFO backtype.storm.daemon.executor - Processingreceived message source: 1:1, stream: default, id: {}, [jackson]
14292 [Thread-10-3] INFO backtype.storm.daemon.task - Emitting: 3default [jackson, 33]
14292 [Thread-9-4] INFO backtype.storm.daemon.task - Emitting: 4default[80]
14368 [Thread-26-2] INFO backtype.storm.daemon.task - Emitting: 2default [golda]
14369 [Thread-10-3] INFO backtype.storm.daemon.executor - Processingreceived message source: 2:2, stream: default, id: {}, [golda]
这里是一部分日志信息。分析例如以下:
1:TestWordSpout 这个spout产生数据并emit([jackson])
2:TestWordCounter这个blot接受刚刚spout产生的数据。并统计每一个单词出现的次数([jackson, 32])
3:TestGlobalCount全局统计一共产生了多少个档次([80])
# 师傅领进门,修行靠个人,哈哈 、、、
# 时间:2014-07-07 18:09:21
版权声明:本文博主原创文章,博客,未经同意不得转载。