伙伴系统中用于分配页的函数如下:
alloc_pages(mask,order)分配2^order页并返回一个struct page的实例,表示分配的内存块的起始页。alloc_page(mask)是前者在order=0情况下的简化形式,只分配一页。
get_zeroed_page(mask)分配一页并返回一个page实例,页对应的内存填充0(所有其他函数分配之后的内容是未定义的)。
__get_free_pages(mask,order)和__get_free_page(mask)的工作方式与上述函数相同,但返回分配内存块的虚拟地址,而不是page实例。
get_dma_pages(gfp_mask,order)用来获得适用于DMA的页。
在空闲内存无法满足请求以至于分配失败的情况下,所有上述函数都返回空指针(alloc_pages和alloc_page)或者0(get_zeroed_page、__get_free_pages和__get_free_page)。因此内核在各次分配之后必须检查返回的结果。这种惯例与设计得很好的用户层应用程序没有什么不同,但在内核中忽略检查将会导致严重得多的故障。
前述所有函数中使用的mask参数的语义是什么?linux将内核划分为内存域,内核提供了所谓的内存域修饰符,来指定从哪个内存域分配所需的页。
#define __GFP_DMA ((__force gfp_t)0x01u)
#define __GFP_HIGHMEM ((__force gfp_t)0x02u)
#define __GFP_DMA32 ((__force gfp_t)0x04u)
除了内存域修饰符之外,掩码中还可以设置一些标志,这些额外的标志并不限制从哪个物理内存段分配内存,但确实可以改变分配器的行为。
#define __GFP_WAIT ((__force gfp_t)0x10u) //表示分配内存的请求可以中断。也就是说,调度器在该请求期间可随意选择另一个过程执行,或者该请求可以被另一个更重要的事件中断。
#define __GFP_HIGH ((__force gfp_t)0x20u) //如果请求非常重要,则设置__GFP_HIGH,即内核急切的需要内存时。在分配内存失败可能给内核带来严重得后果时,一般会设置该标志
#define __GFP_IO ((__force gfp_t)0x40u) //在查找空闲内存期间内核可以进行I/O操作。这意味着如果内核在内存分配期间换出页,那么仅当设置该标志时,才能将选择的页写入磁盘。
#define __GFP_FS ((__force gfp_t)0x80u) //允许内核执行VFS操作
#define __GFP_COLD ((__force gfp_t)0x100u) //如果需要分配不在CPU高速缓存中的“冷”页时,则设置__GFP_COLD。
#define __GFP_NOWARN ((__force gfp_t)0x200u) //在分配失败时禁止内核故障警告。
#define __GFP_REPEAT ((__force gfp_t)0x400u) //在分配失败后自动重试,但在尝试若干次之后会停止。
#define __GFP_NOFAIL ((__force gfp_t)0x800u) //在分配失败后一直重试,直至成功。
#define __GFP_NORETRY ((__force gfp_t)0x1000u)//不重试,可能失败
#define __GFP_COMP ((__force gfp_t)0x4000u)//增加复合页元数据
#define __GFP_ZERO ((__force gfp_t)0x8000u)//在分配成功时,将返回填充字节0的页。
#define __GFP_NOMEMALLOC ((__force gfp_t)0x10000u) //不适用紧急分配链表
#define __GFP_HARDWALL ((__force gfp_t)0x20000u) //只在NUMA系统上有意义。它限制只在分配到当前进程的各个CPU所关联的结点分配内存。如果进程允许在所有的CPU上运行(默认情况下),该标志是没有意义的。只有进程可以运行的CPU受限时,该标志才有意义。
#define __GFP_THISNODE ((__force gfp_t)0x40000u)//页只在NUMA系统上有意义,如果设置该比特位,则内存分配失败的情况下不允许使用其他结点作为备用,需要保证在当前结点或者明确指定的结点上成功分配内存。
#define __GFP_RECLAIMABLE ((__force gfp_t)0x80000u) //将分配的内存标记为可回收
#define __GFP_MOVABLE ((__force gfp_t)0x100000u) //将分配的内存标记为可移动
#define __GFP_BITS_SHIFT 21 /* Room for 21 __GFP_FOO bits */
#define __GFP_BITS_MASK ((__force gfp_t)((1 <
/* This equals 0, but use constants in case they ever change */
#define GFP_NOWAIT (GFP_ATOMIC & ~__GFP_HIGH)
由于这些标志总是组合使用,内核做了一些分组,包含了用于各种标准情形的适当地标志。
#define GFP_ATOMIC (__GFP_HIGH)//用于原子分配,在任何情况下都不能中断,可能使用紧急分配链表中的内存
#define GFP_NOIO (__GFP_WAIT)//明确禁止IO操作,但可以被中断
#define GFP_NOFS (__GFP_WAIT | __GFP_IO)//明确禁止访问VFS层操作,但可以被中断
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)//内核分配的默认配置
#define GFP_TEMPORARY (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_RECLAIMABLE)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)//用户分配的默认配置
#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | \
__GFP_HIGHMEM)//是GFP_USER的一个扩展,页用于用户空间,它允许分配无法直接映射的高端内存,使用高端内存页是没有坏处的,因为用户过程的地址空间总是通过非线性页表组织的
#define GFP_HIGHUSER_MOVABLE (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_HARDWALL | __GFP_HIGHMEM | \
__GFP_MOVABLE)//类似于GFP_HIGHUSER,但分配是在虚拟内存域ZONE_MOVABLE中进行
#define GFP_NOFS_PAGECACHE (__GFP_WAIT | __GFP_IO | __GFP_MOVABLE)
#define GFP_USER_PAGECACHE (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_HARDWALL | __GFP_MOVABLE)
#define GFP_HIGHUSER_PAGECACHE (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_HARDWALL | __GFP_HIGHMEM | \
__GFP_MOVABLE)
#ifdef CONFIG_NUMA
#define GFP_THISNODE (__GFP_THISNODE | __GFP_NOWARN | __GFP_NORETRY)
#else
#define GFP_THISNODE ((__force gfp_t)0)
#endif
/* This mask makes up all the page movable related flags */
#define GFP_MOVABLE_MASK (__GFP_RECLAIMABLE|__GFP_MOVABLE)
/* Control page allocator reclaim behavior */
#define GFP_RECLAIM_MASK (__GFP_WAIT|__GFP_HIGH|__GFP_IO|__GFP_FS|\
__GFP_NOWARN|__GFP_REPEAT|__GFP_NOFAIL|\
__GFP_NORETRY|__GFP_NOMEMALLOC)
/* Control allocation constraints */
#define GFP_CONSTRAINT_MASK (__GFP_HARDWALL|__GFP_THISNODE)
/* Do not use these with a slab allocator */
#define GFP_SLAB_BUG_MASK (__GFP_DMA32|__GFP_HIGHMEM|~__GFP_BITS_MASK)
/* Flag - indicates that the buffer will be suitable for DMA. Ignored on some
platforms, used as appropriate on others */
#define GFP_DMA __GFP_DMA
/* 4GB DMA on some platforms */
#define GFP_DMA32 __GFP_DMA32
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask),0)
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA,(order))
fastcall unsignedlong__get_free_pages(gfp_t gfp_mask, unsignedintorder)
{
structpage * page;
page = alloc_pages(gfp_mask, order);
if(!page)
return0;
return(unsignedlong) page_address(page);
}
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
根据上面的代码,可以得出各个分配函数之间的关系如下图所示:
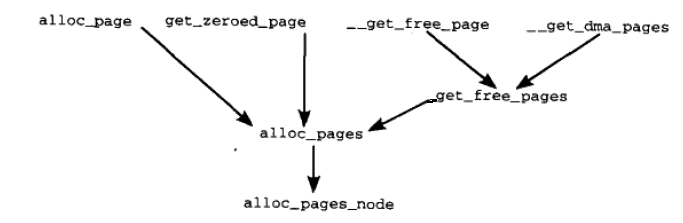
主要的函数是alloc_pages_node。alloc_pages_node源代码的详细分析如下:
staticinlinestructpage *alloc_pages_node(intnid, gfp_t gfp_mask,
unsignedintorder)
{
if(unlikely(order >= MAX_ORDER))//执行一个检查,避免分配过大的内存块
returnNULL;
/* Unknown node is current node */
if(nid
nid = numa_node_id();
return__alloc_pages(gfp_mask, order,
NODE_DATA(nid)->node_zonelists + gfp_zone(gfp_mask));//接下来的工作委托给__alloc_pages,只需传递一组适当地参数,请注意,gfp_zone用于选择分配内存的内存域。
}
staticinlineenumzone_type gfp_zone(gfp_t flags)//本函数比较好理解,就是根据指定的标志确定内存域
{
intbase = 0;
#ifdef CONFIG_NUMA
if(flags & __GFP_THISNODE)
base = MAX_NR_ZONES;
#endif
#ifdef CONFIG_ZONE_DMA
if(flags & __GFP_DMA)
returnbase + ZONE_DMA;
#endif
#ifdef CONFIG_ZONE_DMA32
if(flags & __GFP_DMA32)
returnbase + ZONE_DMA32;
#endif
if((flags & (__GFP_HIGHMEM | __GFP_MOVABLE)) ==
(__GFP_HIGHMEM | __GFP_MOVABLE))
returnbase + ZONE_MOVABLE;
#ifdef CONFIG_HIGHMEM
if(flags & __GFP_HIGHMEM)
returnbase + ZONE_HIGHMEM;
#endif
returnbase + ZONE_NORMAL;
}
__alloc_pages源代码详细分析如下:
__alloc_pages(gfp_t gfp_mask, unsignedintorder,
structzonelist *zonelist)//gfp_mask是一些标志位,用来制定如何寻找空闲页框,order用来表示所需物理块的大小,从空闲链表中获取2^order页内存,在管理区链表zonelist中依次查找每个区,从中找到满足要求的区
{
constgfp_t wait = gfp_mask & __GFP_WAIT;//gfp_mask是申请内存时用到的控制字,这一句就是为了检测我们的控制字里面是否有__GPF_WAIT这个属性
structzone **z;//管理区结构体
structpage *page;
structreclaim_state reclaim_state;
structtask_struct *p = current;
intdo_retry;
intalloc_flags;
intdid_some_progress;
might_sleep_if(wait);//如果在gfp_mask中设置了__GFP_WAIT位,表明内核可以阻塞当前进程,来等待空闲页面。在分配开始之前即阻塞,目的是为了等待其它进程释放更多的页面
if(should_fail_alloc_page(gfp_mask, order))//通过简单算法在真正分配前检查分配是否会失败,避免进入真正的分配程序后浪费系统时间
returnNULL;
restart:
z = zonelist->zones;//zonelist是struct node中的一个成员,它表示系统内所有normal内存页区的连接链表,首先让z指向第一个管理区
if(unlikely(*z == NULL)) {//如果发现头指针为空,即没有指向struct zone的有效指针,我们就直接返回错误
/*
* Happens if we have an empty zonelist as a result of
* GFP_THISNODE being used on a memoryless node
*/
returnNULL;
}
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, order,
zonelist,ALLOC_WMARK_LOW|ALLOC_CPUSET);
//get_page_from_freelist以指定的watermark来分配页面。每个zone struct中定义了三个watermark:pages_min, pages_low, pages_high,表示zone中应保持的空闲页面的阈值。get_page_from_freelist函数通过设置Alloc flags来选择watermark。
if(page)//首先以pages_low watermark分配页面,如果分配成功,则跳转到got_pg
gotogot_pg;
/*
* GFP_THISNODE (meaning __GFP_THISNODE, __GFP_NORETRY and
* __GFP_NOWARN set) should not cause reclaim since the subsystem
* (f.e. slab) using GFP_THISNODE may choose to trigger reclaim
* using a larger set of nodes after it has established that the
* allowed per node queues are empty and that nodes are
* over allocated.
*/
if(NUMA_BUILD && (gfp_mask & GFP_THISNODE) == GFP_THISNODE)//如果pages_low watermark分配失败的话,检查gfp_mask,如果GFP_THISNODE标志被设置,表明不能重试,因此跳转到nopage,返回失败goto nopage
gotonopage;
for(z = zonelist->zones; *z; z++)//否则调用kswapd对zonelist中的所有zone进行页面回收,期待能将一些闲置页面交换到文件系统中
wakeup_kswapd(*z, order);
/*
* OK, we're below the kswapd watermark and have kicked background
* reclaim. Now things get more complex, so set up alloc_flags according
* to how we want to proceed.
*
* The caller may dip into page reserves a bit more if the caller
* cannot run direct reclaim, or if the caller has realtime scheduling
* policy or is asking for __GFP_HIGH memory. GFP_ATOMIC requests will
* set both ALLOC_HARDER (!wait) and ALLOC_HIGH (__GFP_HIGH).
*/
alloc_flags = ALLOC_WMARK_MIN;//设置alloc_flags的值,以page_min watermark来分配内存
if((unlikely(rt_task(p)) && !in_interrupt()) || !wait)//假若进程是非中断处理程序的实时进程,或者该进程不能被阻塞,那么这个时候,我要在最低阈值的标准的基础上,再次降低阈值
alloc_flags |= ALLOC_HARDER;
if(gfp_mask & __GFP_HIGH))//允许使用保留页面
alloc_flags |= ALLOC_HIGH;
if(wait)
alloc_flags |= ALLOC_CPUSET;
/*
* Go through the zonelist again. Let __GFP_HIGH and allocations
* coming from realtime tasks go deeper into reserves.
*
* This is the last chance, in general, before the goto nopage.
* Ignore cpuset if GFP_ATOMIC (!wait) rather than fail alloc.
* See also cpuset_zone_allowed() comment in kernel/cpuset.c.
*/
page = get_page_from_freelist(gfp_mask, order, zonelist, alloc_flags);//以指定的watermark来分配页面,详细讨论见下文
if(page)//分配成功,就进入got_pg
gotogot_pg;
/* This allocation should allow future memory freeing. */
rebalance://上面的第二次分配失败
if(((p->flags & PF_MEMALLOC) || unlikely(test_thread_flag(TIF_MEMDIE)))
&& !in_interrupt()) {//如果当前进程允许本次申请的内存可以被释放,并且不处于软硬中断的状态,我们不顾忌必须保留最小空闲内存页,强行分配
if(!(gfp_mask & __GFP_NOMEMALLOC)) {//如果gfp_mask设置不需要保留紧急内存区域,以不设watermark再次分配页面
nofail_alloc:
/* go through the zonelist yet again, ignoring mins */
page = get_page_from_freelist(gfp_mask, order,
zonelist, ALLOC_NO_WATERMARKS);//以不设watermark进行第三次分配
if(page)//第三次分配成功
gotogot_pg;
if(gfp_mask & __GFP_NOFAIL) {//第三次分配失败,如果gfp_mask设置了__GFP_NOFAIL,则不断重试,直到分配成功
congestion_wait(WRITE, HZ/50);
gotonofail_alloc;
}
}
gotonopage;
}
/* Atomic allocations - we can't balance anything */
if(!wait)//原子分配,不允许阻塞,则只能返回失败信号,分配失败
gotonopage;
cond_resched();//重新调度之后,试图释放一些不常用的页面
/* We now go into synchronous reclaim */
cpuset_memory_pressure_bump();//开始进行同步内存回收
p->flags |= PF_MEMALLOC;//进程的标志位设置为PF_MEMALLOC
reclaim_state.reclaimed_slab = 0;//对于不再活跃的SLAB也给回收掉
p->reclaim_state = &reclaim_state;//改变进程回收的状态
did_some_progress = try_to_free_pages(zonelist->zones, order, gfp_mask);//该函数选择最近不十分活跃的页,将其写到交换区,在物理内存中腾出空间
p->reclaim_state = NULL;
p->flags &= ~PF_MEMALLOC;
cond_resched();
if(order != 0)
drain_all_local_pages();
if(likely(did_some_progress)) {//调度之后,如果确实释放了一部分页面,则重新分配页面
page = get_page_from_freelist(gfp_mask, order,
zonelist, alloc_flags);
if(page)
gotogot_pg;
}elseif((gfp_mask & __GFP_FS) && !(gfp_mask & __GFP_NORETRY)) {//如果内核可能执行影响VFS层的调用而又没有设置GFP_NORETRY,那么调用OOM killer
if(!try_set_zone_oom(zonelist)) {
schedule_timeout_uninterruptible(1);
gotorestart;
}
/*
* Go through the zonelist yet one more time, keep
* very high watermark here, this is only to catch
* a parallel oom killing, we must fail if we're still
* under heavy pressure.
*/
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, order,
zonelist, ALLOC_WMARK_HIGH|ALLOC_CPUSET);
if(page) {
clear_zonelist_oom(zonelist);
gotogot_pg;
}
/* The OOM killer will not help higher order allocs so fail */
if(order > PAGE_ALLOC_COSTLY_ORDER) {//杀死一个进程未必立即出现多余2^PAGE_ALLOC_CODTLY_ORDER页的连续内存区,因此如果当前要分配如此大的内存区,那么内核会饶恕所选择的进程,不执行杀死进程的任务,而是承认失败并跳转到nopage
clear_zonelist_oom(zonelist);
gotonopage;
}
out_of_memory(zonelist, gfp_mask, order);//选择一个内核认为犯有分配过多内存“罪行”的进程,并杀死该进程。这有很大几率腾出较多的空闲页,然后跳转到标号restart,重试分配内存的操作
clear_zonelist_oom(zonelist);
gotorestart;
}
/*
* Don't let big-order allocations loop unless the caller explicitly
* requests that. Wait for some write requests to complete then retry.
*
* In this implementation, __GFP_REPEAT means __GFP_NOFAIL for order
* <= 3, but that may not be true in other implementations.
*/
//如果设置了__GFP_NORETRY,或内核不允许可能影响VFS层的操作
do_retry = 0;
if(!(gfp_mask & __GFP_NORETRY)) {//没有设置__GFP_NORETRY
if((order <= PAGE_ALLOC_COSTLY_ORDER) ||
(gfp_mask & __GFP_REPEAT))//如果分配长度小于2^PAGE_ALLOC_COSTLY_ORDER或设置了__GFP_REPEAT,则内核进入无限循环
do_retry = 1;
if(gfp_mask & __GFP_NOFAIL)//如果设置了不允许分配失败,内核也会进入无限循环
do_retry = 1;
}
if(do_retry) {
congestion_wait(WRITE, HZ/50);
gotorebalance;
}
nopage:
if(!(gfp_mask & __GFP_NOWARN) && printk_ratelimit()) {
printk(KERN_WARNING"%s: page allocation failure."
" order:%d, mode:0x%x\n",
p->comm, order, gfp_mask);
dump_stack();
show_mem();
}
got_pg:
returnpage;
}
get_page_from_freelist源代码的详细分析如下:
staticstructpage *
get_page_from_freelist(gfp_t gfp_mask, unsignedintorder,
structzonelist *zonelist,intalloc_flags)
{
structzone **z;//管理区结构体
structpage *page = NULL;
intclasszone_idx = zone_idx(zonelist->zones[0]);//#define zone_idx(zone) ((zone) - (zone)->zone_pgdat->node_zones) 获取管理区的编号
structzone *zone;
nodemask_t *allowednodes = NULL;/* zonelist_cache approximation */
intzlc_active = 0;/* set if using zonelist_cache */
intdid_zlc_setup = 0;/* just call zlc_setup() one time */
enumzone_type highest_zoneidx = -1;/* Gets set for policy zonelists */
zonelist_scan:
/*
* Scan zonelist, looking for a zone with enough free.
* See also cpuset_zone_allowed() comment in kernel/cpuset.c.
*/
z = zonelist->zones;//让z指向第一个管理区
// 在允许的节点中,遍历满足要求的管理区
do{
/*
* In NUMA, this could be a policy zonelist which contains
* zones that may not be allowed by the current gfp_mask.
* Check the zone is allowed by the current flags
*/
if(unlikely(alloc_should_filter_zonelist(zonelist))) {//根据zonelist->zlcache_ptr来确定是否需要过滤掉此内存区链表,关于过滤的条件还不是很清楚,请指教
if(highest_zoneidx == -1)
highest_zoneidx = gfp_zone(gfp_mask);//gfp_zone用于指定分配内存的内存域
if(zone_idx(*z) > highest_zoneidx)//首先考虑利用上面指定的内存域,对于一些分配代价高于指定内存域的内存域先不考虑
continue;
}
if(NUMA_BUILD && zlc_active &&//是第一遍分配,在其他管理区中分配页面时需要考虑其页面是否充足
!zlc_zone_worth_trying(zonelist, z, allowednodes))//该管理区页面不是很充足,考虑下一个管理区
continue;
zone = *z;
if((alloc_flags & ALLOC_CPUSET) &&
!cpuset_zone_allowed_softwall(zone, gfp_mask))//当前分配标志不允许在该管理区中分配页面
gototry_next_zone;
if(!(alloc_flags & ALLOC_NO_WATERMARKS)) {//分配时需要考虑watermark
unsignedlongmark;//根据分配标志,确定使用哪一个watermark
if(alloc_flags & ALLOC_WMARK_MIN)
mark = zone->pages_min;
elseif(alloc_flags & ALLOC_WMARK_LOW)
mark = zone->pages_low;
else
mark = zone->pages_high;
if(!zone_watermark_ok(zone, order, mark,
classzone_idx, alloc_flags)) {//该管理区的可用内存不可以满足本次分配的要求
if(!zone_reclaim_mode ||//但不满足分配要求时,如果此内存域不能回收内存或者是回收不到可用内存时,就会跳转到this_zone_full
!zone_reclaim(zone, gfp_mask, order))
gotothis_zone_full;
}
}
page = buffered_rmqueue(zonelist, zone, order, gfp_mask);//调用伙伴系统的分配函数
if(page)// 从伙伴系统分配成功,退出
break;
this_zone_full:
if(NUMA_BUILD)
zlc_mark_zone_full(zonelist, z);//标记该管理区空间不足,下次分配时将略过本管理区,避免浪费太多时间
try_next_zone:
if(NUMA_BUILD && !did_zlc_setup) {//当前管理区内存不足,需要加大在其他区中的分配力度
/* we do zlc_setup after the first zone is tried */
allowednodes = zlc_setup(zonelist, alloc_flags);
zlc_active = 1;
did_zlc_setup = 1;
}
}while(*(++z) != NULL);
if(unlikely(NUMA_BUILD && page == NULL && zlc_active)) {// 第一遍分配不成功,则取消zlc_active,这样会尽量从其他节点中分配内存
/* Disable zlc cache for second zonelist scan */
zlc_active = 0;
gotozonelist_scan;
}
returnpage;
}
关于上面一段代码中zlc_active的作用不明白,还望理解的人指点一下。
structzonelist {
structzonelist_cache *zlcache_ptr;// NULL or &zlcache
structzone *zones[MAX_ZONES_PER_ZONELIST + 1];// NULL delimited
#ifdef CONFIG_NUMA
structzonelist_cache zlcache;// optional ...
#endif
};
structzonelist_cache {
unsignedshortz_to_n[MAX_ZONES_PER_ZONELIST];/* zone->nid */
DECLARE_BITMAP(fullzones, MAX_ZONES_PER_ZONELIST);/* zone full? */
unsignedlonglast_full_zap;/* when last zap'd (jiffies) */
};
zone_watermark_ok源代码详细分析如下:
intzone_watermark_ok(structzone *z,intorder, unsignedlongmark,
intclasszone_idx,intalloc_flags)
{
/* free_pages my go negative - that's OK */
longmin = mark;
longfree_pages = zone_page_state(z, NR_FREE_PAGES) - (1 <
into;
if(alloc_flags & ALLOC_HIGH)//设置了ALLOC_HIGH之后,将最小值标记减少一半
min -= min / 2;
if(alloc_flags & ALLOC_HARDER)//设置了ALLOC_HARDER之后,将最小值标记减少1/4
min -= min / 4;
if(free_pages <= min + z->lowmem_reserve[classzone_idx])//检查空闲页的数目是否小于最小值与lowmem_reserve中制定的紧急分配值之和,如果小于则不进行内存分配
return0;
for(o = 0; o
/* At the next order, this order's pages become unavailable */
free_pages -= z->free_area[o].nr_free <
/* Require fewer higher order pages to be free */
min >>= 1;//每升高一阶,所需空闲页的最小值减半,因为阶数越高,每一个块中包含的页面就越多。我们假设初始水线是2^n,那么对阶数0来说,min的值就应当是2^n,对阶数为1来说,min的值就应当除以2变为2^(n-1),因为对于阶数1来说,每个块包含的页面数为2
if(free_pages <= min)//如果内核遍历所有的低端内存域之后,发现内存不足,则不进行内存分配
return0;
}
return1;
}
buffered_rmqueue源代码详细分析如下:
staticstructpage *buffered_rmqueue(structzonelist *zonelist,
structzone *zone,intorder, gfp_t gfp_flags)
{
unsignedlongflags;
structpage *page;
intcold = !!(gfp_flags & __GFP_COLD);//如果分配参数指定了__GFP_COLD标志,则设置cold标志,两次取反操作确保cold是0或者1,why?请指教
intcpu;
intmigratetype = allocflags_to_migratetype(gfp_flags);//根据gfp_flags获得迁移类型
again:
cpu = get_cpu();//获取本CPU
if(likely(order == 0)) {//分配单页,需要管理每CPU页面缓存
structper_cpu_pages *pcp;
pcp = &zone_pcp(zone, cpu)->pcp[cold];//取得本CPU的页面缓存对象
local_irq_save(flags);//这里需要关中断,因为内存回收过程可能发送核间中断,强制每个核从每CPU缓存中释放页面。而且中断处理函数也会分配单页。
if(!pcp->count) {//缓存为空,需要扩大缓存的大小
pcp->count = rmqueue_bulk(zone, 0,
pcp->batch, &pcp->list, migratetype);//从伙伴系统中摘除一批页面到缓存中,补充的页面个数由每CPU缓存的batch字段指定
if(unlikely(!pcp->count))//如果缓存仍然为空,那么说明伙伴系统中页面也没有了,分配失败
gotofailed;
}
/* Find a page of the appropriate migrate type */
list_for_each_entry(page, &pcp->list, lru)//遍历每CPU缓存中的所有页,检查是否有指定类型的迁移类型的页可用
if(page_private(page) == migratetype)
break;
/* Allocate more to the pcp list if necessary */
if(unlikely(&page->lru == &pcp->list)) {
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, &pcp->list, migratetype);
page = list_entry(pcp->list.next,structpage, lru);
}
list_del(&page->lru);//将页面从每CPU缓存链表中取出,并将每CPU缓存计数减1
pcp->count--;
}else{
spin_lock_irqsave(&zone->lock, flags);
page = __rmqueue(zone, order, migratetype);
spin_unlock(&zone->lock);
if(!page)
gotofailed;
}
__count_zone_vm_events(PGALLOC, zone, 1 <
zone_statistics(zonelist, zone);
local_irq_restore(flags);
put_cpu();
VM_BUG_ON(bad_range(zone, page));
if(prep_new_page(page, order, gfp_flags))
gotoagain;
returnpage;
failed:
local_irq_restore(flags);
put_cpu();
returnNULL;
}我也知道有很多的细节都没有分析到位,但是我也没有办法,曾经想着把里面涉及到的每一个函数都分析到位,但是那样的话自己相当的痛苦,因为那样的结果就是很多天都没有办法前进一点,会让人相当的有挫败感,最后只能选择大概先都过一遍,因为自己是一个内核的初学者,而内核前后的关联又很大,也只能先过一遍,到后面我会重新回来看我写得博客,能增进一些分析就增进一些分析。如果您认为上面确实有很重要的地方我没有分析到,希望您指点。