文章目录
- 爬虫需求:
- 需要爬取的网站 [目标网站](http://shop.jc001.cn/r1-231/?p=1)
- 爬取内容:需要爬取网站的公司名称以及电话
- 该网站有6000多条信息
- 爬虫思路解析
- 1.封装函数获取网站所有页码
- 2.通过获取页面的url去解析获取每一个详情页的url
- 3.网站详情页请求以及解析
- 3.1详情页请求函数
- 3.2详情页解析函数(解析需要内容,并存储)
- 3.3详情页解析总函数
- UA伪装以及代理IP
- 最终结果
爬虫需求:
需要爬取的网站 目标网站
爬取内容:需要爬取网站的公司名称以及电话
公司名称在列表页
 联系方式在详情页
联系方式在详情页

该网站有6000多条信息

1.考虑到网站信息太多,不能使用简单的爬虫请求页面,需要考虑到单个ip无法满足要求,网站访问次数过多,会被网站反爬机制封ip
2.单个程序请求页面,还要解析,单线程太慢
爬虫思路解析
事先导入需要用的模块
import random
import requests
from lxml import etree
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import time
1.封装函数获取网站所有页码
def get_pageurl(start, page_len, url):""":param start: 起止页码:param page_len: 页码个数:param url: 网站模板url:return: """print('****************开始获取取页面URL****************')i = startj = 0url_list = []while j <= page_len:#网站页码规律 模板url http://shop.jc001.cn/r1-231/?p=# j为页码数 url_full= 'http://shop.jc001.cn/r1-231/?p=' +页码数url_full = url + str(i)url_list.append(url_full)i += 1j += 1else:print('****************已爬取页面URL****************')return url_list2.通过获取页面的url去解析获取每一个详情页的url

def get_allurls(url_list):print('****************开始爬取商家页面URL****************')# 集合用来存储不重复的所有详情页的urlall_urls = set()count = 0for page_url in url_list:page_text = requests.get(url=page_url, headers=header,proxies={"http": random.choice(proxy_ip)}).texttree = etree.HTML(page_text)#解析每个页面所包含的详情页的urla_list = tree.xpath('/html/body/div[8]/div[2]/div[2]/table/tbody/tr/td[1]/a/@href')for a in a_list:# a = "http:" + aall_urls.add(a)count += 1print('****************已爬取 %s 家商家页面URL****************' % count)return all_urls
3.网站详情页请求以及解析
首先网站详情页6000多张 ,不可能网站一张张的去请求,这样花费时间非常多,而且由于ip的访问频率限制,在请求的时候还需要设置请求间隔,以防单个ip请求速度过快导致ip被封,所以这里需要用到多线程
3.1详情页请求函数
这里注意一点,一定要使用异常模块,想一想发生异常就要抛出一面红看着就难受,所以这里使用异常模块,单个线程执行速度很快
time.sleep(0.5) random.choice(proxy_ip) 都是是为了防止单个ip每秒内访问服务器次数太多导致ip不可用。
def get_page(detail_url):time.sleep(0.5)try:response = requests.get(detail_url, headers=header, proxies={"http": random.choice(proxy_ip)}, timeout=5).textexcept Exception as e:response = ' 'return {'url': detail_url, 'text': response}
3.2详情页解析函数(解析需要内容,并存储)
def parase_page(res):# parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果res = res.result()page_text = res.get('text')try:if page_text:tree = etree.HTML(page_text)name = tree.xpath('/html/body/div[2]/div[1]/div[1]/div/h3/a/text()')[0]num = tree.xpath('//div[@class="cnt line"]/table//tr[3]/td//text()')[0].strip('\xa0')with open('xiaogan.txt', 'a', encoding='utf-8') as f:f.write('%s|%s\n' % (name, num))except Exception as e:print(e)
3.3详情页解析总函数
def get_information(all_urls):print('****************开始爬取所有公司名称电话****************')#线性池 15个线程同时执行p = ThreadPoolExecutor(15)for detail_url in all_urls:#add_done_callback(parase_page) 回调函数 执行完请求就回调解析模块p.submit(get_page,detail_url).add_done_callback(parase_page)
UA伪装以及代理IP
代理ip是在快代理上购买的私密ip
#UA伪装
header = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",'Connection': 'close',"Accept-Encoding": "Gzip",
}
#代理ip
#proxy_ip是一个包含30个代理ip的列表
api_url = "http://dps.kdlapi.com/api/getdps/?orderid=958623468831485&num=30&pt=1&format=json&sep=1"
proxy_ip = requests.get(api_url).json()['data']['proxy_list']
调用函数开始执行
url = "http://shop.jc001.cn/r1-239/?p="
url_list = get_pageurl(1,49, url)
all_urls = get_allurls(url_list)
print(all_urls)
get_information(all_urls)
最终结果
上面程序是运行一次可以爬取1000条资料,运行速度也很快,15线程同时运行

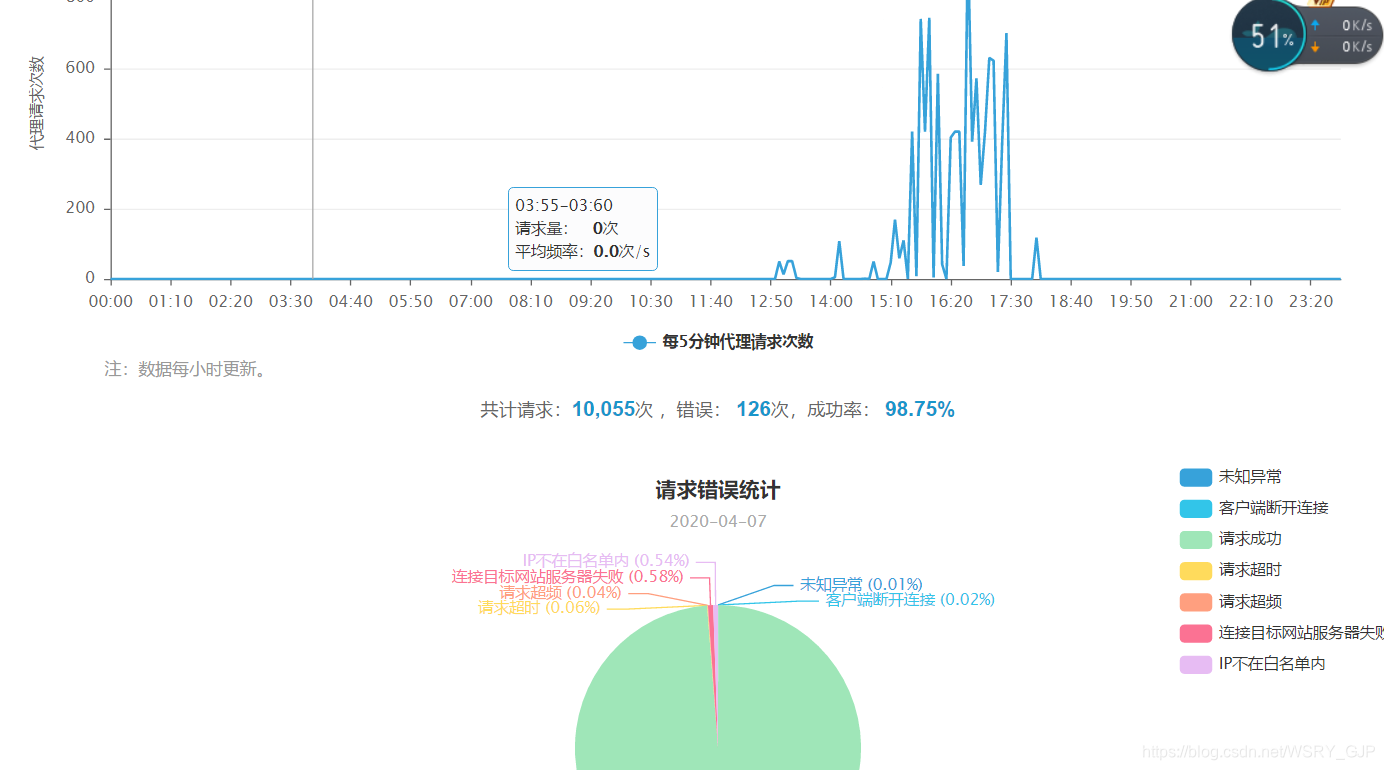
从代理ip网站后台可以看到程序的响应数很高