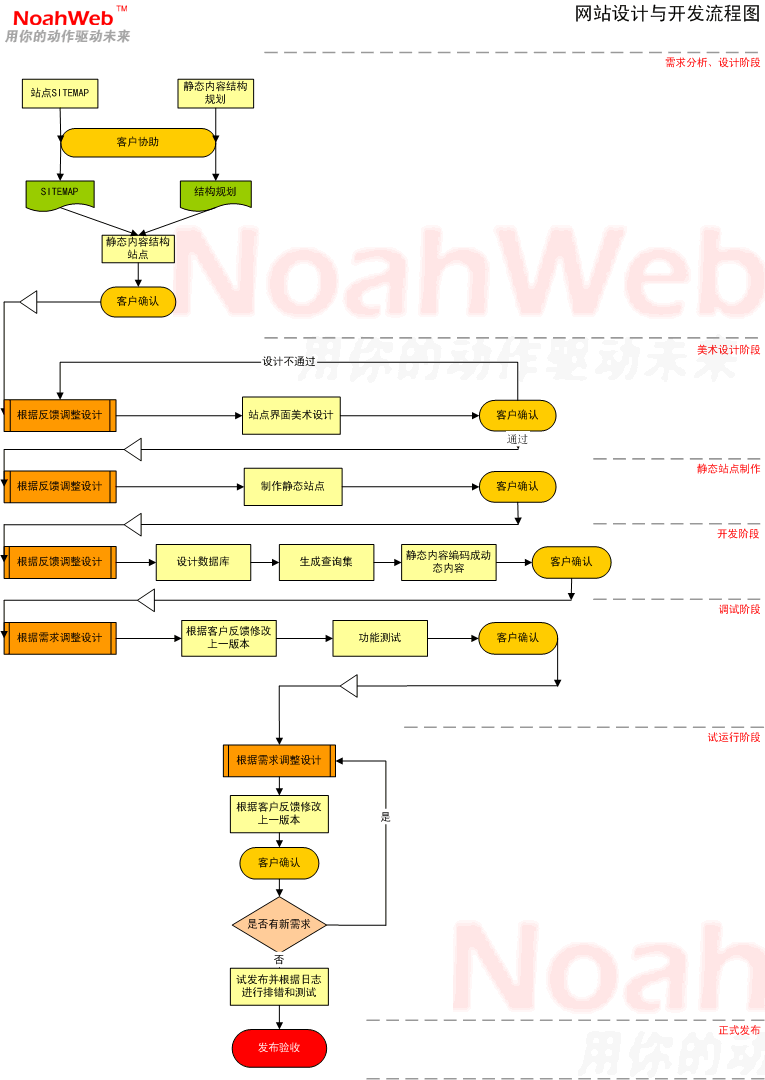
1.1 Web server
Web server 用来解析HTTP协议。当web服务器接收到一个HTTP请求时,会返回一个HTTP响应,例如送回一个HTML页面。为了处理一个请求,web服务器可 以响应一个静态页面或者图片。进行页面跳转,或者把动态响应的产生委托给一些其它的程序完成,比如CGI, JSP, Servlets, ASP.NET,PHP脚本。
当用户访问一个网站时,首先用户通过查询DNS服务器,得到该域名对应的IP地址,然后使用这个IP地址来进行访问。用户的请求是一个url地 址,在web服务器端,url地址对应web服务器上的文件系统中的某个网站文件的路径。Web server的作用就是解析HTTP协议,通过用户发来请求的url地址从web服务器的文件系统中找到用户需要的HTML页面、静态文件,然后返回给用 户。如果用户访问的是动态页面,则将请求转发到应用服务器来执行。
1.1.1 FastCGI
1.1.1.1 CGI
CGI(Common Gateway Interface) ,指运行在服务器上,提供同客户端HTML页面的接口。多数CGI程序被用来解释处理来自表单的输入信息,并在服务器产生相应的处理,或将相应的信息反馈给浏览器。
1.1.1.2 FastCGI
FastCGI是语言无关的、可伸缩架构的CGI开放扩展,其主要行为是将CGI解释器进程保持在内存中并因此获得较高的性能。而CGI解释器 的反复加载是CGI性能低下的主要原因。如果CGI解释器保持在内存中并接受FastCGI进程管理器的调度,则可以提供良好的性能、伸缩性能和 Fail-over特性等。
FastCGI的工作原理如下:
(1) FastCGI进程管理器自身初始化,启动多个CGI解释器进程(多php-cgi进程)并等待来自web server的连接。启动php-cgi FastCGI进程时,可以配置以TCP和UNIX套接字两种方式启动。
(2) 当客户端请求到达web服务器时,web服务器将请求采用TCP协议或者UNIX套接字方式转发到FastCGI主进程,FastCGI主进程选择并连接 到一个CGI解释器(子进程)。Web服务器将CGI环境变量和标准输入法发送到FastCGI子进程php-cgi。
(3) FastCGI子进程完成处理后,将标准输出和错误信息从同一连接返回web服务器。当FastCGI子进程关闭连接时,请求便告知处理完成。FastCGI子进程接着等待并处理来自FastCGI进程管理器的下一个连接。
FastCGI的优点如下:
(1) 稳定性。FastCGI是以独立的进程池运行CGI,单独一个进程死掉,系统可以轻松的丢弃,然后重新分配新的进程。
(2) 安全性。FastCGI和宿主Server完全独立,FastCGI如果down了,不会影响到Server的性能。
(3) 高性能。FastCGI和宿主Server分开,大负荷的IO处理留给web server进行,比如大量图片、CSS等静态文件的IO操作,完全由web server处理完成。[2]
1.1.1.3 Lighttpd服务器
Lighttpd是一个具有非常低的内存开销,CPU占用率低,性能好的轻量级Web Server。支持FastCGI, CGI, 输出压缩,URL重写,Alias等重要功能。
Lighttpd使用FastCGI方式运行php。
1.1.1.4 Apache服务器
Apache是世界上使用最多的web服务器,市场占有率50%以上。Apache支持SSL技术,支持多个虚拟主机。Apache是以进程为 基础结构,进程相对线程消耗更多系统资源。相对Lighttpd和Nginx,Apache是一款重量级的web服务器。总体来讲,Apache web 服务器具有以下特性:
(1) 支持HTTP1.1通信协议。
(2) 支持通用网关接口。
(3) 支持基于ip、域名、端口的虚拟主机。
(4) 支持服务器端包含指令(ssl)。
(5) 支持FastCGI。
(6) 支持url重写。
1.1.1.5 Nginx服务器
Nginx是俄罗斯人Igor Sysoev编写的一款高性能HTTP和反向代理服务器。Nginx能够选择高效的epoll(Linux 2.6内核)、kqueue(FreeBSD)、eventport(Solaris 10)作为网络I/O模型,在高连接并发的情况下,Nginx是Apache服务器很好的替代者,因为在同样并发连接的情况下,Nginx相对 Apache占用更少的系统资源。[3]
1.1.1.6 Lighttpd、Apache、Nginx比较
Lighttpd是一个单进程模型的web server,内存使用量很小。Nginx在内存分配方面,表现良好。它使用多线程来处理请求,这使得多个线程之间可以共享内存资源,从而使它的内存使用 量大大减少。此外,Nginx使用分阶段的内存分配策略,按需分配,及时释放,所以总体占用内存很小。可以支持较大的并发连接数。Apache在运行时使 用较大的内存,Apache是多进程模型。Apache使用基于内存池策略的内存管理方法,这种方法使得Apache在运行开始时便一次性申请大片内存作 为内存池,这样在随后需要的时候只在内存池中直接获取,不需要再分配。显然,Apache很占用内存。根据国内金山技术经理、系统架构师张宴给出的统计信 息,2009年的web server使用情况如表4-1-1-5所示。
表4-1-1-5 各种web server市场占有率排名
| Web server | 2008.12使用数 | 占有率 | 2009.01使用数 | 占有率 | 占有率变化 |
| Apache | 95678052 | 51.24% | 96947298 | 52.26% | +1.02% |
| IIS | 63126940 | 33.81% | 61038371 | 32.91% | -0.90% |
| | 10455103 | 5.60% | 9868819 | 5.32% | -0.28 |
| Nginx | 3354329 | 1.80% | 3462551 | 1.87% | +0.07% |
| Lighttpd | 3046333 | 1.63% | 2989416 | 1.61% | -0.02% |
1.2 缓存
在计算机系统中,缓存有很多种。比如CPU内部的一级缓存、二级缓存。文件系统的缓存,磁盘的缓存。在大型网站的后台部署过程中,也灵活运用了 各级缓存。主要有客户端的浏览器缓存,服务器端的web server自身缓存,代理缓存,分布式缓存,数据库自身的缓存等。本节主要分析一下代理缓存和分布式缓存。
1.2.1 代理缓存
在网站后台架构中,代理缓存主要部署在web server之上,当用户对网站后台发起连接请求时,用户请求先到代理缓存中去查找,如果命中,则将请求返回给用户,如果没有命中,则代理缓存将请求发到 web server,然后web sever将请求复制一份到代理缓存中,同时把请求返回给客户。
常用的代理缓存有varnish和squid。如图4-2-1所示。

图4-2-1 代理缓存(黄色部分)
1.2.1.1 Squid
Squid是一个高性能的代理缓存服务器,可以用来加快浏览网页的速度,提高客户机的访问命中率。Squid不仅支持HTTP协议,还支持FTP、SSL、WAIS等协议。Squid用一个单独的、非模块化的、I/O驱动的进程来处理所有的客户端请求。
Squid的原理如下:
(1) 每一台Squid代理服务器上存有若干个颗磁盘。每颗磁盘又分割成多个分区,每一个分区又可建立很多目录,目录下存放着具体的文件(object)。
(2) Squid通过查询表的方式来定位某个资源的位置。所查询的表有两种,一种是Hash table,一种是Digest table。Hash table记录着所有Digest table表信息,所以Hash table可以称之为目录或者提纲。而Digest table记录了磁盘上每个分区、每个目录里存放的缓存摘要,所以Digest table可以称之为摘要或者索引。所以,Squid接到请求后先查询Hashtable,根据Hash table所指向的Digest table,再查询所需要的文件。
(3) Squid服务器存在两种工作关系,一种为Child-Parent,当Child Squid Server没有用户需要的数据时,就向Parent squid Server发送请求,并持续等待,直到Parent Squid Server回应为止;另一种为Sibling,当本地Squid Server没有用户请求的数据时,会向Sibling Server发送请求,如果Sibling Server没有资料则会向上级Sibling或者Internet发送数据请求。
所以,综上所述,Squid运行模式如下:
当Squid Server没有资料时,先向Sibling的Squid Server查询数据,如果Sibling没有,则跳过它直接向Parent查询,直到Parent提供资料为止(如果Parent没有资料,则到后端的 web server上获取,当获取到数据后返回给用户的同时,保留一份在自身的缓存中)。如果不存在Parent,则Squid Server自身到后端的web server上获取数据,当获取到数据后返回给用户的同时,保留一份在自身的缓存中。如果还是不能得到数据,则向用户端回复不能得到数据。
1.2.1.2 Varnish
Varnish是一款高性能的开源HTTP加速器,挪威最大的在线报纸Verdens Gang使用3台Varnish代替了原来的12台Squid,性能比以前更好。
Varnish的作者Poul-Henning Kamp是FreeBSD内核开发者之一,他认为现在的计算机比起1975年已经复杂很多。在1975年时,存储媒介只有两种:内存与硬盘。但现在计算机 系统的内存除了主存外,还包括了CPU内的L1\L2\L3等cache。因此Squid Cache自行处理物件替换的架构不可能得知这些情况而做到最佳化,但操作系统可以。所以这部分的工作应该交给操作系统处理,这就是Varnish cache设计架构[4]。Varnish将所有的HTTP object存于一个单独的大文件中,该文件在工作进程初始化的时候,将其整个映射到内存中。这样Varnish在该块内存中实现一个简单的文件系统,具有分配、释放、修剪、合并内存等功能。
Varnish文件缓存的工作流程:
Varnish与一般服务器软件类似,分为master进程和child进程。其中master进程负责管理,child进程负责cache工 作。Master进程读入命令,进行一些初始化,然后fork并监控child进程。Child进程分配若干线程进行工作,主要包括管理线程和 worker线程。如图4-2-1-2所示。

主进程fork子进程,主进程等待子进程的信号,子进程退出后,主进程重新启动子进程,子进程生成若干线程:
(1) Accept线程:接受请求,将请求挂在overflow队列上。
(2) Work线程:有多个,负责从overflow队列上摘除请求,对请求进行处理,直到完成,然后处理下一个请求。
(3) Epoll线程:一个请求处理称为一个session,在session周期内,处理完请求后,会交给Epoll处理,监听是否还在事件发生。
(4) Expire线程:对于缓存的object,根据过期时间,组织成二叉堆,该线程周期检查该堆得根,处理过期的文件。对过期的数据进行删除或重取操作。
Varnish分配缓存机制:
根据所读到的object大小,创建相应大小的缓存文件。为了读写方便,程序将每个object的大小,转变为最接近其大小的内存页面倍数。然 后从现有的空闲存储结构体中查找,找到最合适的大小的空闲存储块,分配给它。如果空闲块没有用完,则把多余的内存再组成一个空闲存储块,挂接到管理结构体 上。如果缓存已满,则根据LRU算法,把旧的object释放掉。
Varnish释放缓存机制:
Expire线程负责检测缓存中所有object的生存期(TTL)。如果超过了设定的TTL,该object没有被访问,则删除该object,并释放内存。释放的过程会考虑内存的合并等操作。
1.2.2 分布式缓存
1.2.2.1 Memcached
Memcached是以LiveJournal旗下Danga Interactive公司的Brad Fitzpatric为首开发的一款软件。现在Memcached已成为mixi、hatena、Facebook等公司提高web应用扩展性的重要缓存 软件。许多web应用都将数据保存到RDBMS中,应用服务器从中读取数据并返回给用户。但随着数据量的增大,访问的集中性,读写比例的增大,会使 RDBMS增加其系统开销,相应速度下降,网络延迟增大。Memcached通过缓存数据库查询结果,减少数据库读的访问次数,提高动态网站的响应速度。 此外,电子商务网站的客户端cookie和服务器端session机制也可以利用Memcached解决,比如典型的购物车跟踪记录访问行为、购买问题 等。也可以将其信息记录在后端的Memcached中。典型的应用如图4-2-2-1-1所示。

图 4-2-2-1-1
如图所示,当用户第一次访问数据库时,应用服务器从数据库中查询数据返回给用户,并且在memcached中存储一份数据。当第二次,应用服务 器需要从数据库中查询数据时,首先从memcached查询数据,如果有则得到数据,返回给用户,如果没有,则再从数据库中查找数据。返回给用户,并拷贝 一份数据到memcached中。
Memcached默认情况下采用名为Slab Allocator的机制分配、管理内存。Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Slab Allocator原理,将分配的内存分割成各种尺寸的块(chunk),并将尺寸相同的块分成组(chunk的集合)。如图4-2-2-1-2所示。

图 4-2-2-1-2
如图所示,memcached根据收到的数据的大小,选择最适合数据大小的slab。Memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存在其中。如图4-2-2-1-3所示。

图4-2-2-1-3
同squid、varnish一样,memcached同样使用LRU机制来分配内存,删除最近最少未使用的数据。
1.3 本文小结
本章主要分析了FastCGI的运行机制,简单介绍了三种常用的web server —— Lighttpd、Apache、Nginx,对三款常用web server进行了对比。然后又分别介绍了代理缓存Squid和Varnish。最后简单分析了分布式缓存Memcached。总体而言,这些缓存的应用 可以极大加快网站的访问速度。提升用户体验。缓存的应用,在高可用的大型网站中,处处可见。