项目的数据分析过程在hadoop集群上实现,主要应用hive数据仓库工具,因此,采集并经过预处理后的数据,需
要加载到hive数据仓库中,以进行后续的挖掘分析。
ETL:用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程
6.1创建原始数据表
--在hive仓库中建贴源数据表
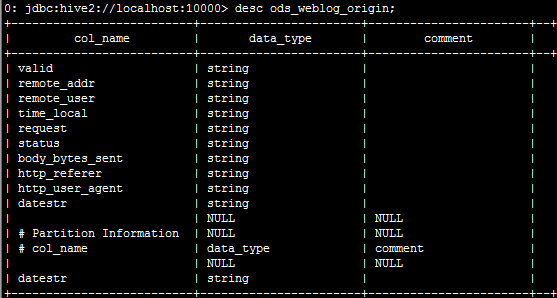
drop table if exists shizhan.ods_weblog_origin; create table shizhan.ods_weblog_origin( valid string, remote_addr string, remote_user string, time_local string, request string, status string, body_bytes_sent string, http_referer string, http_user_agent string) partitioned by (datestr string) row format delimited fields terminated by '\001';
--点击流模型pageviews表
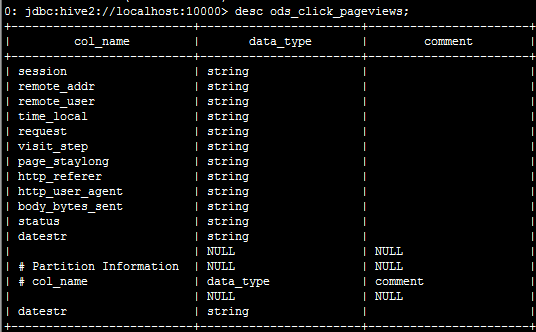
drop table if exists ods_click_pageviews; create table ods_click_pageviews( Session string, remote_addr string, remote_user string, time_local string, request string, visit_step string, page_staylong string, http_referer string, http_user_agent string, body_bytes_sent string, status string) partitioned by (datestr string) row format delimited fields terminated by '\001';
--点击流visit模型表
drop table if exist click_stream_visit; create table click_stream_visit( session string, remote_addr string, inTime string, outTime string, inPage string, outPage string, referal string, pageVisits int) partitioned by (datestr string);
6.2 导入数据
1.首先将日志文件上传至服务器,原则上是在HDFS上的(wash_part-m-00000、pageview_part-r-00000、visiout_part-r-00000)
2.导入清洗结果数据到贴源数据表:ods_weblog_origin
load data local inpath '/data/wash_part-m-00000' into table ods_weblog_origin partition(datestr='2013-09-18');
3.导入点击流模型pageviews数据到:ods_click_pageviews
load data local inpath '/data/pageview_part-r-00000' into table ods_click_pageviews partition(datestr='2013-09-18');
4.导入点击流模型visit数据到:click_stream_visit
load data local inpath '/data/visiout_part-r-00000' into table click_stream_visit partition(datestr='2013-09-18');
6.3 生成ODS层明细宽表
6.3.1 需求概述
整个数据分析的过程是按照数据仓库的层次分层进行的,总体来说,是从操作数据存储ODS原始数据中整理出一
些中间表(比如,为后续分析方便,将原始数据中的时间、url等非结构化数据作结构化抽取,将各种字段信息进行细化,
形成明细表),然后再在中间表的基础之上统计出各种指标数据
6.3.2 ETL实现:
建表——明细表ods_weblog_detail (源:ods_weblog_origin) (目标:ods_weblog_detail)
drop table ods_weblog_detail; create table ods_weblog_detail( valid string, --有效标识 remote_addr string, --来源IP remote_user string, --用户标识 time_local string, --访问完整时间 daystr string, --访问日期 timestr string, --访问时间 month string, --访问月 day string, --访问日 hour string, --访问时 request string, --请求的url status string, --响应码 body_bytes_sent string, --传输字节数 http_referer string, --来源url ref_host string, --来源的host ref_path string, --来源的路径 ref_query string, --来源参数query ref_query_id string, --来源参数query的值 http_user_agent string --客户终端标识 ) partitioned by(datestr string);
抽取refer_url,将来访url分离出host path query query id,抽取转换time_local字段
insert into table ods_weblog_detail partition(datestr='2013-09-18') select c.valid,c.remote_addr,c.remote_user,c.time_local, substring(c.time_local,0,10) as daystr, substring(c.time_local,12) as tmstr, substring(c.time_local,6,2) as month, substring(c.time_local,9,2) as day, substring(c.time_local,11,3) as hour, c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent from (SELECT a.valid,a.remote_addr,a.remote_user,a.time_local, a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as ref_host, ref_path, ref_query, ref_query_id) c
操作数据存储ODS